
微服务的战争:选型?分布式链路追踪
“微服务的战争” 是一个关于微服务设计思考的系列题材,主要是针对在微服务化后所出现的一些矛盾/冲突点,不涉及具体某一个知识点深入。如果你有任何问题或建议,欢迎随时交流。
背景
在经历微服务的战争:级联故障和雪崩 的 P0 级别事件后,你小手一摊便葛优躺了。开始进行自我复盘,想起这次排查经历,由于现在什么基础设施都还没有,因此在接收到客户反馈后,你是通过错误日志进行问题检查的。
但在级联错误中,错误日志产生的实在是太多了,不同的服务不同的链路几乎都挤在一起,修复时间都主要用在了翻日志上,翻了好几页才找到了相对有效的错误信息。
如果下一次在出现类似的问题,可不得了,MTTR 太久了,4 个 9 很快就会用完。这时候你想到了业界里经常被提起的一个利器,那就是 “分布式链路追踪系统”。粗略来讲,能够看到各种应用的调用依赖:
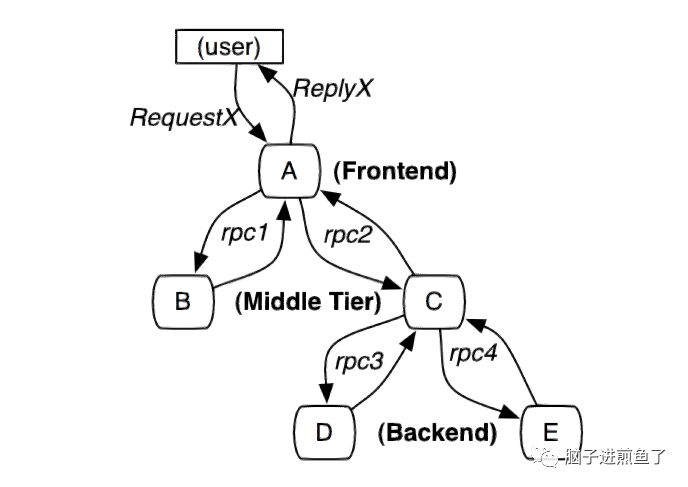
其中最著名的是 Google Dapper 论文所介绍的 Dapper。源于 Google 为了解决可能由不同团队,不同语言,不同模块,部署在不同服务器,不同数据中心的所带来的软件复杂性(很难去分析,无法做定位),构建了一个的分布式跟踪系统:
自此就开启了业界在分布式链路的启发/启蒙之路,很多现在出名的分布式链路追踪系统都是基于 Google Dapper 论文发展而来,基本原理和架构都大同小异。若对此有兴趣的可具体查看 Google Dapper,非常有意思。

(Google Dapper 中存在跟踪树和 Span 的概念)
选型?有哪些
想做链路追踪,那必然要挑选一款开源产品作为你的分布式链路追踪系统,不大可能再造一个全新的,先实现业务目的最重要。因此在网上一搜,发现如下大量产品:
Twitter:Zipkin。 Uber:Jaeger。 Elastic Stack:Elastic APM。 Apache:SkyWalking(国内开源爱好者吴晟开源)。 Naver:Pinpoint(韩国公司开发)。 阿里:鹰眼。 大众点评:Cat。 京东:Hydra。
随手一搜就发现这类产品特别的多,并且据闻各大公司都有自己的一套内部链路追踪系统,这下你可犯了大难。他们之间都是基于 Google Dapper 演进出来的,那本质上到底有什么区别,怎么延伸出这么多的新产品?
Jaeger
首先看看由 Uber 开发的 Jaeger,Jaeger 目前由 Cloud Native Computing Foundation(CNCF)托管,是 CNCF 的第七个顶级项目(于 2019 年 10 月毕业):
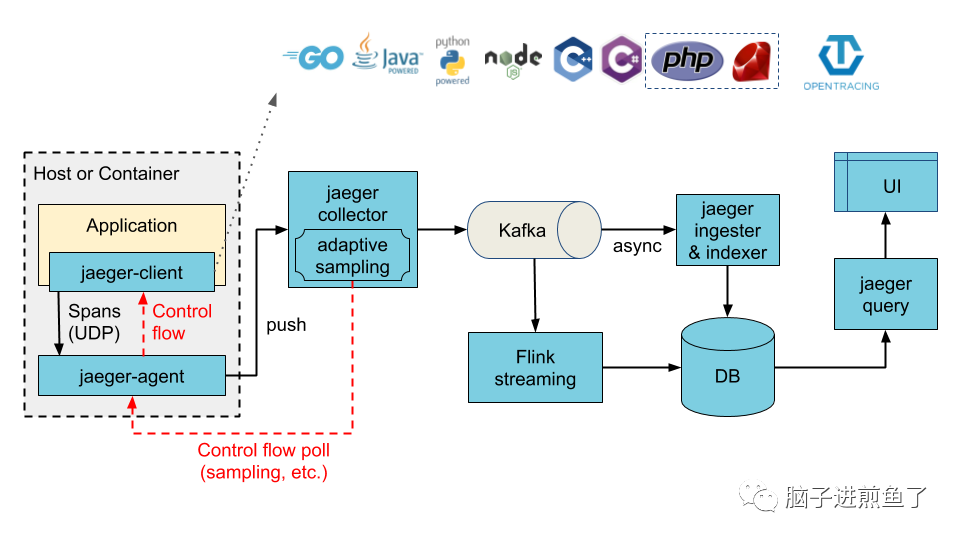
Jaeger Client:Jaeger 客户端,是 Jaeger 针对 OpenTracing API 的特定语言实现,可用于手动或通过与 OpenTracing 集成的各种现有开源框架(例如Flask,Dropwizard,gRPC等)来检测应用程序以进行分布式跟踪。
Jaeger Agent:Jaeger 客户端代理,在 UDP 端口上监听所接受的跨度并将其分批发送给 Collector。
Jaeger Collector:Jaeger 收集器,顾名思义是面向 Agent,用于收集/管理链路的追踪信息。
Jaeger Query:数据查询与前端界面展示。
Jaeger Ingester:可从 Kafka 读取数据并写入其他的存储介质(Cassandra,Elasticsearch)。
在了解 Jaeger 的各组件功能后,主要关注其整体的整体架构上的数据流转:
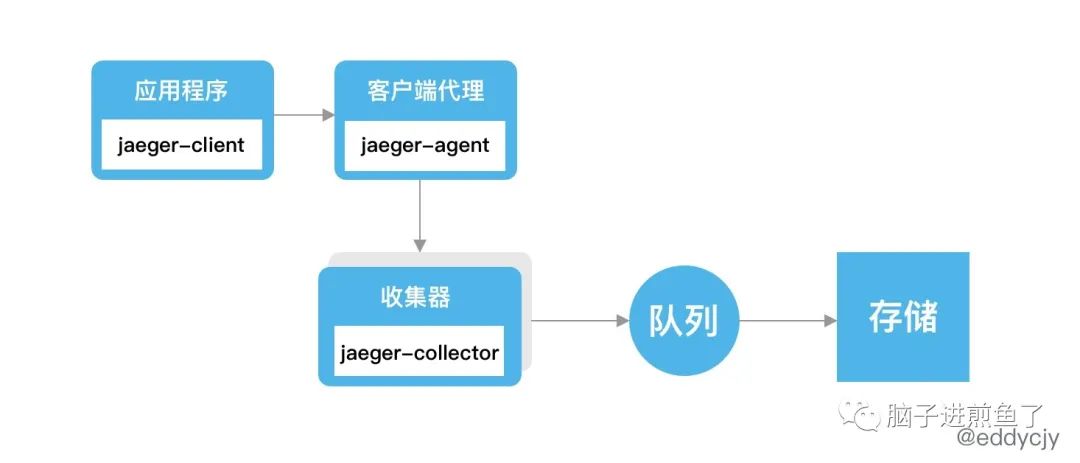
Jaeger 是一个很经典的架构,由客户端主动发送链路信息到 Agent,Agent 上报给 Collector,再经由队列,最终落地到存储。再由另外的可视化管理后台进行查看和分析。
更具现化就是 上报 =》收集 =》存储 =》分析的标准化流程。并且你会发现 Jaeger 与 Zipkin 在架构上差不多:
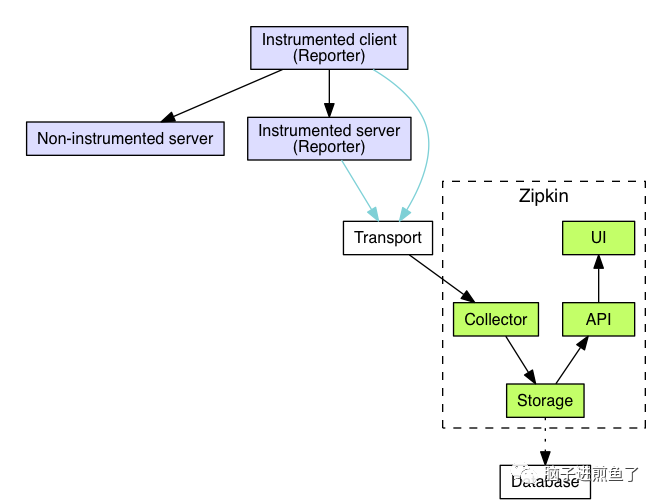
Zipkin Collector:Zipkin 收集器,用于收集/管理链路的追踪信息。
Storage:Zipkin 数据存储,支持 Cassandra、ElasticSearch 和 MySQL 等第三方存储。
Zipkin Query Service:数据存储并建立索引后,用于查找和检索跟踪信息。
Web UI:数据查询与前端界面展示。
从时间上来看 Jaeger 比 Zipkin 晚四年,莫非是重复造轮子。经过翻阅,可得知做 Jaeger 的主要原因是:
当时将跨度发送到 Zipkin 的唯一方法是通过 Scribe,而 Zipkin 支持的唯一高性能数据存储是 Cassandra。当时 Uber 对这两种技术都没有经验,因此选择了自己构建一个后端,该后端将一些自定义组件与 Zipkin UI 结合在一起,形成了一个完整的跟踪系统。
更详细可阅读 Evolving Distributed Tracing at Uber Engineering,可以了解很多细节。
阿里鹰眼
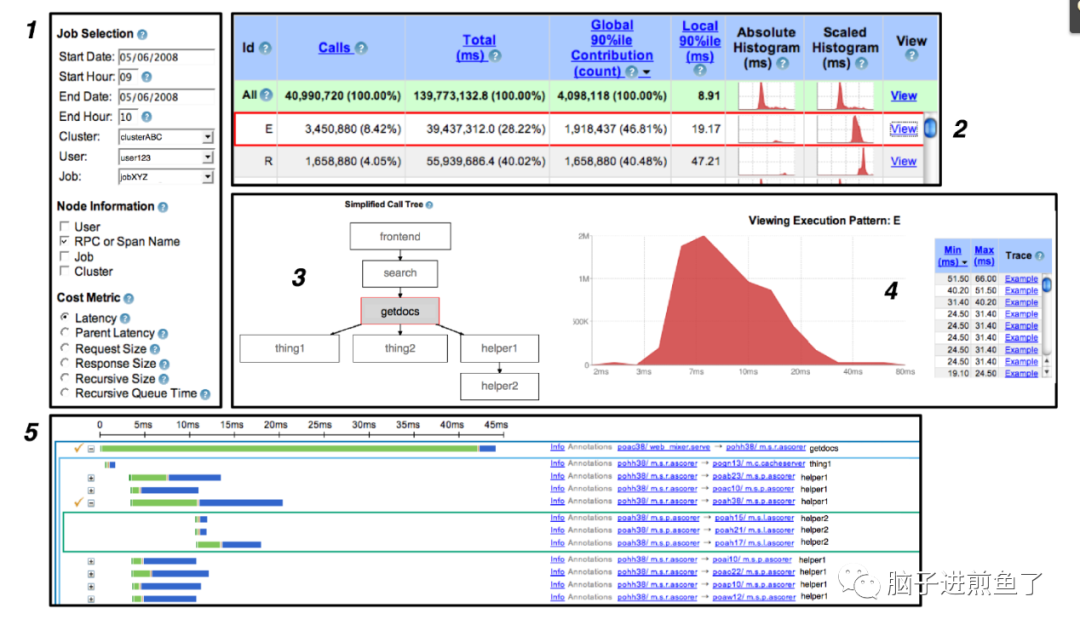
链路追踪系统的另一代表,基于日志和流式计算去做的居多,像是阿里的鹰眼,滴滴的 traces,如下图:
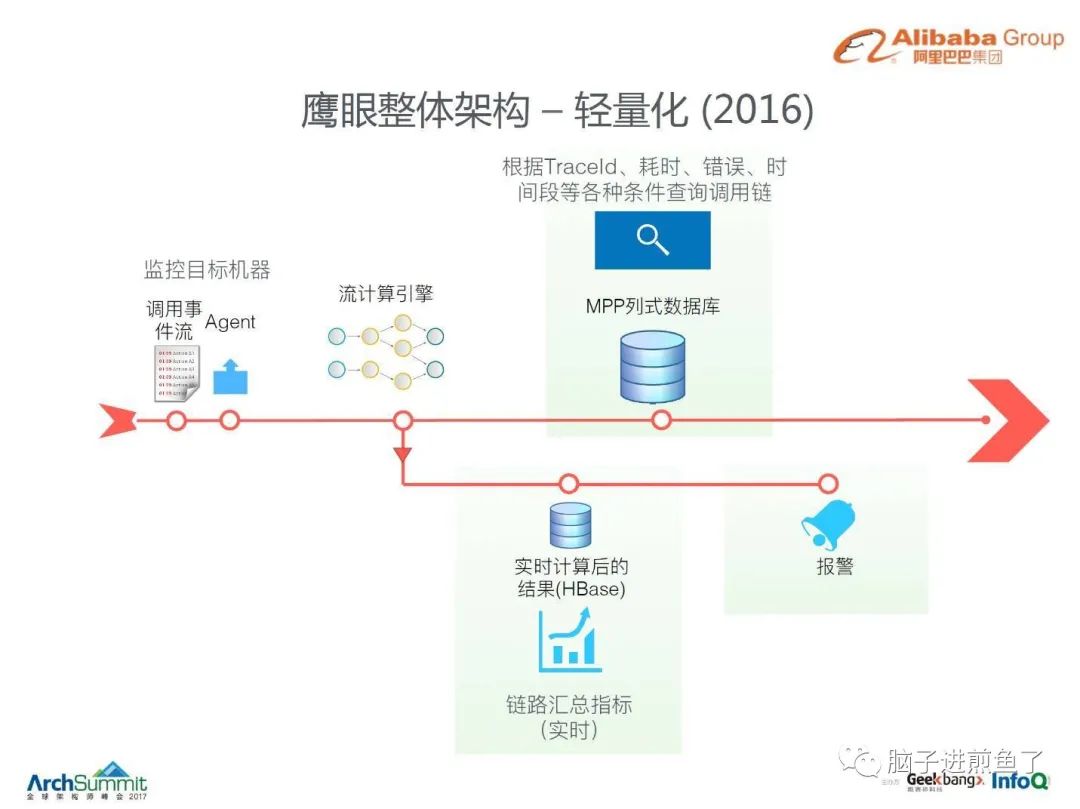
更具体可见《阿里巴巴鹰眼技术解密》 和 《异构系统链路追踪——滴滴 trace 实践》 在大会上的分享,这里就不再赘述了,推荐好奇或忧愁链路追踪落地的小伙伴们阅读。
总结
大多数在初始选型时都会选择亲和性比较强的追踪系统,就像是 Jaeger 属于 Go,Zipkin、Skywalking 是 Java 系居多,三者都完全兼容 OpenTracing,只是架构上多少有些不同,且都是基于 Google Dapper 发散,因此所支持的基本功能和查询页面优雅与否很重要。
而本来就有原始的 N 个系统,如果想接入直接新的链路追踪系统,还是非常麻烦的。因为原意想接入,必然是想解决原有系统的排查/定位问题,而不单单是为了新系统,因此单从接入的角度来讲,大多不会就不会使用既有开源追踪系统(除非历史债务不大),且数据量可能极大。
因此基于既有方法去改造来清洗数据再做成链路追踪的模式也挺常见的,这之中日志常常是一个比较好的下手点,也就是去清洗某某数据,形成新的分析系统,再造一个内部轮子。
另外近两年基于 ServiceMesh 的 ”无” 侵入式链路追踪也广受欢迎,似乎是一个被看好的方向,其代表作之一 Istio 便是使用 CNCF 出身的 Jaeger,且 Jaeger 还兼容 Zipkin,在这点上 Jaeger 完胜。
推荐阅读
站长 polarisxu
自己的原创文章
不限于 Go 技术
职场和创业经验
Go语言中文网
每天为你
分享 Go 知识
Go爱好者值得关注