
【何恺明新作速读】Masked Autoencoders Are Scalable Vision Learners
作者 | 胖虎
原文 | https://zhuanlan.zhihu.com/p/434345170
本文经过作者同意转载。
最近这篇文章大火了,毕竟是FAIR的文章,而且一作还是Kaiming大佬。粗略地读了一下,概括性地写了本篇笔记。
Autoencoders在NLP应用的比CV多,这是为什么呢?
1、CV界基本是卷积称霸的现状(尽管transformer逐渐兴起)。要把例如mask tokens或者位置编码融入到卷积操作中很难。而ViT一定程度上解决了这个问题。
2、信息密度问题。语言是人类创造的,所以基本都是信息密集的。而图片可能存在很多信息冗余。这造成了什么问题呢?一句话如果我mask掉一两个单词,模型若想要补全这句话,需要非常high-level的理解,也就是真正理解这句话(想想高中英语的完形填空)。但是图片如果我mask掉十几个像素点,我根本不需要理解这张图片是什么,就算用个二插值我都能补全个七七八八。为了解决这个问题,本文mask掉大量的像素(例如75%)。这样,模型就不得不去理解high-level的信息,才能够补全出来一张图了。
3、autoencoder中的decoder,在NLP和CV中是不同的。CV中解码出来的是pixel,是low-level的语义信息。NLP中解码出来的是单词,语义信息丰富的多。同时,NLP中,例如BERT,他的decoder就是MLP,但是CV中,decoder决定了latent representation的语义级别。
于是本文提出了非对称masked autoencoders(MAE)。整体结构如下,先遮,然后把可见的patch输入encoder,然后把masked tokens合并进去,接着一顿操作猛如虎,解码后补全图片。
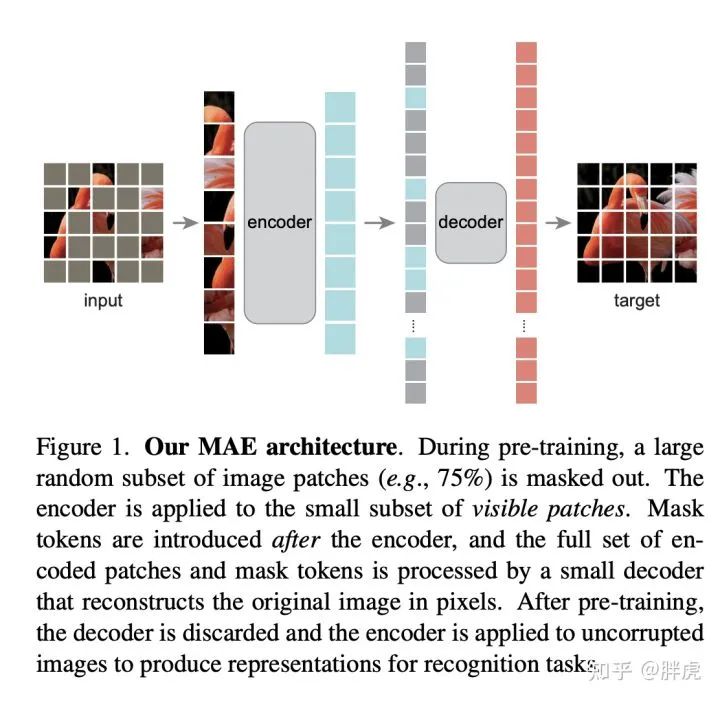
Approach
1、Mask:与ViT类似,把图片切分成一个个小patch,然后根据uniform distribution随机mask掉一定比例的patch。
2、Encoder:直接用ViT,但是输入的是未mask的patch。这使得整张图片只有一小部分(未mask的部分)会被ViT处理,大大提高了效率。而mask的部分,会交给更轻量级的decoder来处理。
3、Decoder:解码过程加入了masked patch,同时加入了位置编码。decoder只在预训练的时候使用。所以decoder完全可以和encoder独立。本文的默认设置中就用了一个很小的decoder,平均每一个patch的计算量比encoder少了90%以上。
4、Reconstruction Target:本文做了两种实验,第一种是直接产出pixel,然后计算MSE。第二种是对每一个patch计算均值方差,然后归一化。实验发现,归一化处理后representation的质量有提升。
5、Simple Implementation:整个模型实现起来很简单。
ImageNet Experiment
往常这一部分我都会简略,自己看原文比较快,无非是demonstrate自己的模型有多牛逼,多好。但是这篇文章的实验部分挺有意思。简单地来写一下。
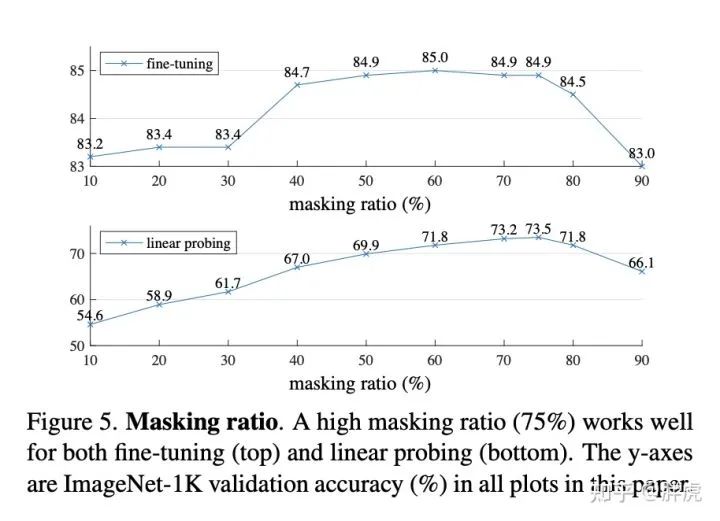
实验结果中,很神奇的一点就是,当mask比例在75%上下的时候,准确率非常好。反而当mask比例比较小的时候,效果不好。这点比较反直觉。个人推测可能的原因是,当mask比例太小的时候,模型无法学习到很多high-level的语义信息,导致其无法真正“理解”图片。而支持我这一猜想的证据是,该模型所做的图片补全看起来并不是简单的延长一下线条或者色块,而是对整幅图有深刻的理解,才能补全出来的。
Decoder Design
Decoder的部分也很有趣,并不是越大、越深,就越好,反而是合适的深度和宽度更能发挥作用。

主要的差别通过linear probing可以体现。Decoder需要有一定深度,因为autoencoder的最后几层应当是专注于重建,而不是识别。一个合理深度的decoder可以专注于重建工作,使得latent representations停留在一个更抽象的层面上。
Mask Token
上面提到,编码的时候,mask token不参与。实验中,如果让mask token也参与,不仅变慢了,准确率还下降了。这是因为预训练和部署之间存在了一个差异:预训练的时候给了他很多mask tokens,但是这些tokens并不存在于未被污染的图片中。
Conclusion
这篇文章提出了MAE这个架构,算是又一个NLP领域到CV领域的重要迁移。NLP之前有BERT和GPT大红大紫过,而现在这种mask的方法迁移到了CV任务上。全文看下来一个大公式都没有(这点挺神奇的,以往的论文基本都至少有两三个大公式)。虽然文章强调了自己的模型lightweight,但是ViT-Large有多大懂的都懂。希望未来能够找到一个更加轻量级的backbone。另外,文章对于具体训练的流程说的比较简略,大部分都在介绍模型的架构本身。比如如何pretrian,finetune,以及如何做linear probing的等等。但是抛开这些,从科研的角度来说,这是一个颇有价值的新突破。
——The End——

推荐阅读
Yann LeCun主讲,纽约大学《深度学习》2021春季课程放出,免费可看
如何看待何恺明最新一作论文Masked Autoencoders Are Scalable Vision Learners?
为了方便大家学习交流,我们建立了微信群,欢迎大家进群讨论。
你可以加我的微信邀请你进群,微商和广告无关人员请绕道,谢谢合作!
