
见鬼了,容器好端端就重启了?

在日常的开发工作中相信使用 Kubernetes 的同学们一定会偶尔收到容器重启的事件告警。由于应用层面的问题导致的容器重启相对容易排查,比如看容器的内存监控我们能确定是不是内存超过配置的 limit; 又或者看是不是应用有 panic 没有 recovery。
一个正常的工作日我们突然连续收到多条容器重启告警,查看报警还是来自不同的应用。按照一般的排查思路先去查看监控,内存没有异常,使用值一直在 limit 之下;然后去看日志也没有找到任何 panic 或者其他错误。仔细一看这几个告警的应用都是来自同一个集群,这个时候猜测大概率和集群有关系,但是这个集群我们还有其他很多应用并没有发生容器重启,所以猜测应该不是集群本身的问题,那是不是和机器有关系呢?然后我把重启过的实例所在的 node ip 都筛选出来发现重启的应用都是集中在某几台机器。在这些节点上我去查看了一下 kubelet进程,发现 kubelet 在容器告警的时间段都重启了进程。在这种情况下基本就找到了容器重启的直接原因--kubelet 重启了。但是我们并没有更新实例,kubelet 重启怎么会把我们的容器重启呢?下面我们就介绍一下根本原因--kubelet计算容器的 hash 值。
我们知道在 Kubernetes 中的节点上运行着 kubelet 进程,这个进程负责当前节点上所有 Pod 的生命周期。在这里我们从源码层面看看 kubelet 怎么实现容器的重启。
SyncPod
我们首先看 https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kuberuntime/kuberuntime_manager.go 中的 SyncPod 方法, 这个方法就是保证运行中的 Pod 与我们期望的配置时刻保持一致。通过以下步骤完成
根据从 API Server 获得的 Pod Spec 以及当前 Pod 的 Status 计算所需要执行的 Actions 在需要情况下 Kill 掉当前 Pod 的 sandbox 根据需要(如重启)kill 掉 Pod 内的 containers 根据需要创建 Pod 的 sandbox 启动下一个 init container 启动 Pod 内的 containers
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, _ v1.PodStatus, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
// Step 1: Compute sandbox and container changes.
// 计算 pod 的
podContainerChanges := m.computePodActions(pod, podStatus)
glog.V(3).Infof("computePodActions got %+v for pod %q", podContainerChanges, format.Pod(pod))
if podContainerChanges.CreateSandbox {
ref, err := ref.GetReference(legacyscheme.Scheme, pod)
if err != nil {
glog.Errorf("Couldn't make a ref to pod %q: '%v'", format.Pod(pod), err)
}
if podContainerChanges.SandboxID != "" {
m.recorder.Eventf(ref, v1.EventTypeNormal, events.SandboxChanged, "Pod sandbox changed, it will be killed and re-created.")
} else {
glog.V(4).Infof("SyncPod received new pod %q, will create a sandbox for it", format.Pod(pod))
}
}
// Step 2: Kill the pod if the sandbox has changed.
// sandbox 有更新,需要 kill pod
if podContainerChanges.KillPod {
...
killResult := m.killPodWithSyncResult(pod, kubecontainer.ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil)
result.AddPodSyncResult(killResult)
if killResult.Error() != nil {
glog.Errorf("killPodWithSyncResult failed: %v", killResult.Error())
return
}
if podContainerChanges.CreateSandbox {
m.purgeInitContainers(pod, podStatus)
}
} else {
// Step 3: kill any running containers in this pod which are not to keep.
// kill 掉 pod 中不需要保留的容器
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
glog.V(3).Infof("Killing unwanted container %q(id=%q) for pod %q", containerInfo.name, containerID, format.Pod(pod))
killContainerResult := kubecontainer.NewSyncResult(kubecontainer.KillContainer, containerInfo.name)
result.AddSyncResult(killContainerResult)
if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, nil); err != nil {
killContainerResult.Fail(kubecontainer.ErrKillContainer, err.Error())
glog.Errorf("killContainer %q(id=%q) for pod %q failed: %v", containerInfo.name, containerID, format.Pod(pod), err)
return
}
}
}
...
// Step 4: Create a sandbox for the pod if necessary.
// 按需创建 sandbox
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
var msg string
var err error
glog.V(4).Infof("Creating sandbox for pod %q", format.Pod(pod))
createSandboxResult := kubecontainer.NewSyncResult(kubecontainer.CreatePodSandbox, format.Pod(pod))
result.AddSyncResult(createSandboxResult)
podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt)
...
}
...
}
...
// Step 5: start the init container.
// 启动 init 容器
if container := podContainerChanges.NextInitContainerToStart; container != nil {
// Start the next init container.
startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, container.Name)
result.AddSyncResult(startContainerResult)
...
if msg, err := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, kubecontainer.ContainerTypeInit); err != nil {
startContainerResult.Fail(err, msg)
utilruntime.HandleError(fmt.Errorf("init container start failed: %v: %s", err, msg))
return
}
// Successfully started the container; clear the entry in the failure
glog.V(4).Infof("Completed init container %q for pod %q", container.Name, format.Pod(pod))
}
// Step 6: start containers in podContainerChanges.ContainersToStart.
// 根据 step1 结果启动容器
for _, idx := range podContainerChanges.ContainersToStart {
container := &pod.Spec.Containers[idx]
startContainerResult := kubecontainer.NewSyncResult(kubecontainer.StartContainer, container.Name)
result.AddSyncResult(startContainerResult)
...
glog.V(4).Infof("Creating container %+v in pod %v", container, format.Pod(pod))
if msg, err := m.startContainer(podSandboxID, podSandboxConfig, container, pod, podStatus, pullSecrets, podIP, kubecontainer.ContainerTypeRegular); err != nil {
...
}
}
return
}
computePodActions
在上面 SyncPod 方法中我们可以看到 step 1 的 computePodActions 是决定容器是否需要重启的关键调用,我们看看这个方法具体的逻辑
// computePodActions checks whether the pod spec has changed and returns the changes if true.
func (m *kubeGenericRuntimeManager) computePodActions(pod *v1.Pod, podStatus *kubecontainer.PodStatus) podActions {
glog.V(5).Infof("Syncing Pod %q: %+v", format.Pod(pod), pod)
createPodSandbox, attempt, sandboxID := m.podSandboxChanged(pod, podStatus)
changes := podActions{
KillPod: createPodSandbox,
CreateSandbox: createPodSandbox,
SandboxID: sandboxID,
Attempt: attempt,
ContainersToStart: []int{},
ContainersToKill: make(map[kubecontainer.ContainerID]containerToKillInfo),
}
// 这里我们省略其他内容,直接看判断容器是否需要重启的核心逻辑
// Number of running containers to keep.
keepCount := 0
// check the status of containers.
for idx, container := range pod.Spec.Containers {
containerStatus := podStatus.FindContainerStatusByName(container.Name)
// Call internal container post-stop lifecycle hook for any non-running container so that any
// allocated cpus are released immediately. If the container is restarted, cpus will be re-allocated
// to it.
if containerStatus != nil && containerStatus.State != kubecontainer.ContainerStateRunning {
if err := m.internalLifecycle.PostStopContainer(containerStatus.ID.ID); err != nil {
glog.Errorf("internal container post-stop lifecycle hook failed for container %v in pod %v with error %v",
container.Name, pod.Name, err)
}
}
// If container does not exist, or is not running, check whether we
// need to restart it.
if containerStatus == nil || containerStatus.State != kubecontainer.ContainerStateRunning {
if kubecontainer.ShouldContainerBeRestarted(&container, pod, podStatus) {
message := fmt.Sprintf("Container %+v is dead, but RestartPolicy says that we should restart it.", container)
glog.V(3).Infof(message)
changes.ContainersToStart = append(changes.ContainersToStart, idx)
}
continue
}
// The container is running, but kill the container if any of the following condition is met.
reason := ""
restart := shouldRestartOnFailure(pod)
// 计算容器的期望的 hash 和 当前 hash, 来判断是否需要重启容器
if expectedHash, actualHash, changed := containerChanged(&container, containerStatus); changed {
reason = fmt.Sprintf("Container spec hash changed (%d vs %d).", actualHash, expectedHash)
// Restart regardless of the restart policy because the container
// spec changed.
restart = true
} else if liveness, found := m.livenessManager.Get(containerStatus.ID); found && liveness == proberesults.Failure {
// If the container failed the liveness probe, we should kill it.
reason = "Container failed liveness probe."
} else {
// Keep the container.
keepCount += 1
continue
}
// We need to kill the container, but if we also want to restart the
// container afterwards, make the intent clear in the message. Also do
// not kill the entire pod since we expect container to be running eventually.
message := reason
// 可以看到如果需要重启容器,则把容器 id 放到待启动 slice 里准备重启
if restart {
message = fmt.Sprintf("%s. Container will be killed and recreated.", message)
changes.ContainersToStart = append(changes.ContainersToStart, idx)
}
// 容器信息更新到待 kill 的 map 里
changes.ContainersToKill[containerStatus.ID] = containerToKillInfo{
name: containerStatus.Name,
container: &pod.Spec.Containers[idx],
message: message,
}
glog.V(2).Infof("Container %q (%q) of pod %s: %s", container.Name, containerStatus.ID, format.Pod(pod), message)
}
if keepCount == 0 && len(changes.ContainersToStart) == 0 {
changes.KillPod = true
}
return changes
}
containerChanged
在上个方法里我们看到 containerChanged的调用决定了容器是否需要重启,接下来我们看看如果计算容器的 hash 值
func containerChanged(container *v1.Container, containerStatus *kubecontainer.ContainerStatus) (uint64, uint64, bool) {
expectedHash := kubecontainer.HashContainer(container)
return expectedHash, containerStatus.Hash, containerStatus.Hash != expectedHash
}
在文件`kubernetes/pkg/kubelet/container/helpers.go` 中提供了计算 hash 的方法
// HashContainer returns the hash of the container. It is used to compare
// the running container with its desired spec.
func HashContainer(container *v1.Container) uint64 {
hash := fnv.New32a()
hashutil.DeepHashObject(hash, *container)
return uint64(hash.Sum32())
}
通过上述的代码的我们可以清楚的看到只要 v1.Container 这个 struct 里任何一个字段发生改变都会导致期望的容器 hash 值更新。
下面这种图清晰总结了 Kubelet 重启容器的过程,详相信对照下图和上面的代码大家应该能很好的了解 Kubernetes 的容器重启过程。
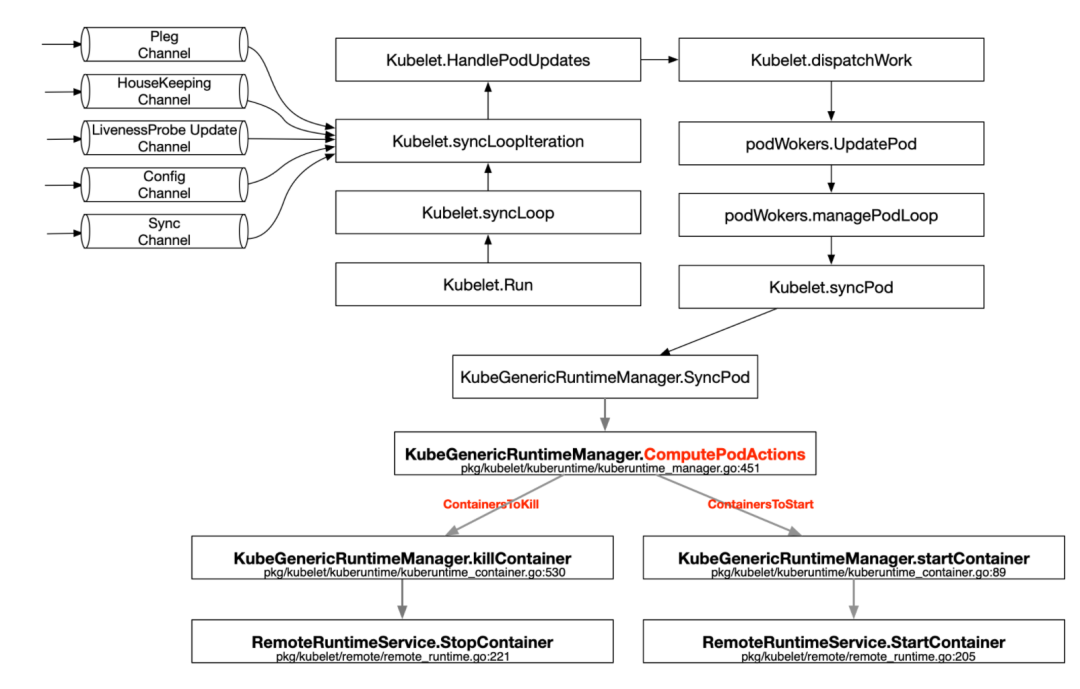
原文链接:https://lxkaka.wang/kubelet-hash/


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
