
模型上下文长度达到10000000,又一批创业者完蛋了?

“ 硅兔君荐语
RAG终究是个过渡期的产物? 没有疑问,Gemini 1.5 Pro的隆重推出被Sora抢了风头。 社交平台X上OpenAI介绍Sora的第一条动态,现在已经被浏览了超过9000万次,而关于Gemini 1.5 Pro热度最高的一条,来自谷歌首席科学家Jeff Dean,区区123万人。 或许Jeff Dean自己也觉得郁闷。Gemini 1.5 Pro和Sora共同发布的一周后,他在X上点赞了沃顿商学院副教授Ethan Mollick认为人们对大模型的注意力发生了偏差的观点。 Ethan Mollick几乎是教育界最早公开推崇生成式AI的人之一,他在2023年2月公开呼吁学生应该都应该开始用ChatGPT写论文。而这一次他的观点是,考虑到大模型在图像生成方面所体现出的有限价值,它实在是引起了过多的讨论了。 “对于大模型的实验室来说,图像生成更像是一个聚会上的节目......做为内核的LLM才是价值所在。但社交媒体更乐于分享照片。” ——没说的是,社交媒体也更乐于分享Gif,以及视频。 人类是视觉动物,所以Sora才会这么抢眼。或许我们太高估了Sora,又太忽视了Gemini 1.5 Pro。 Gemini 1.5 Pro展现出的众多能力中有一点很特殊,它已经是一个具备处理视频语料输入的多模态大模型。Sora能将文字扩展成视频,Gemini 1.5 Pro的野心是把理解视频的能力开放出来。在对模型能力的考验上,很难说后者就弱于前者。 这背后的基础性工作在上下文输入长度上。Gemini 1.5 Pro的上下文长度达到1M Token,这意味着一小时的视频、3万行代码或者JK·罗琳把小说从《哈利波特与魔法石》写到《哈利波特与凤凰社》,远高于包括GPT、Claude系列在内的目前市面上所有的大模型。而谷歌甚至透露,1M Token并不是极限,谷歌内部已经成功测试了高达10M Token的输入,也就是说,它已经能一口气看完9个小时的《指环王》三部曲。 上下文长度抵达10M Token到底意味着什么,等到Sora带来的激情稍褪,人们逐渐回过味儿来。 X、Reddit......越来越多的讨论场开始关注到10M Token所展现出的可能性,其中最大的争议在于,它是否“杀死”了RAG(Retrieval Augment Generation,检索增强生成)。 大模型从概念走向商业应用的过程中,本身的问题逐渐暴露,RAG开始成为贯穿整个2023年最火热的技术名词。 一个被普遍接受的描述框架给这项技术找到了最精准的定位。如果将整个AI看作一台新的计算机,LLM就是CPU,上下文窗口是内存,RAG技术是外挂的硬盘。RAG的责任是降低幻觉,并且提升这台“新计算机”的实效性和数据访问权限。 但本质上这是因为这台“新计算机”仍然又笨又贵,它需要更多脑容量、需要了解更具专业性的知识,同时最好不要乱动昂贵又玻璃心的那颗CPU。RAG某种程度上是为了生成式AI能够尽早进入应用层面的权宜之计。 10M Token的上下文输入上限,意味着很多RAG要解决的问题不成问题了,然后一些更激进的观点出现了。 曾构建了评测基准C-EVAL的付尧认为,10M Token杀死了RAG——或者更心平气和的说法是,长文本最终会取代RAG。
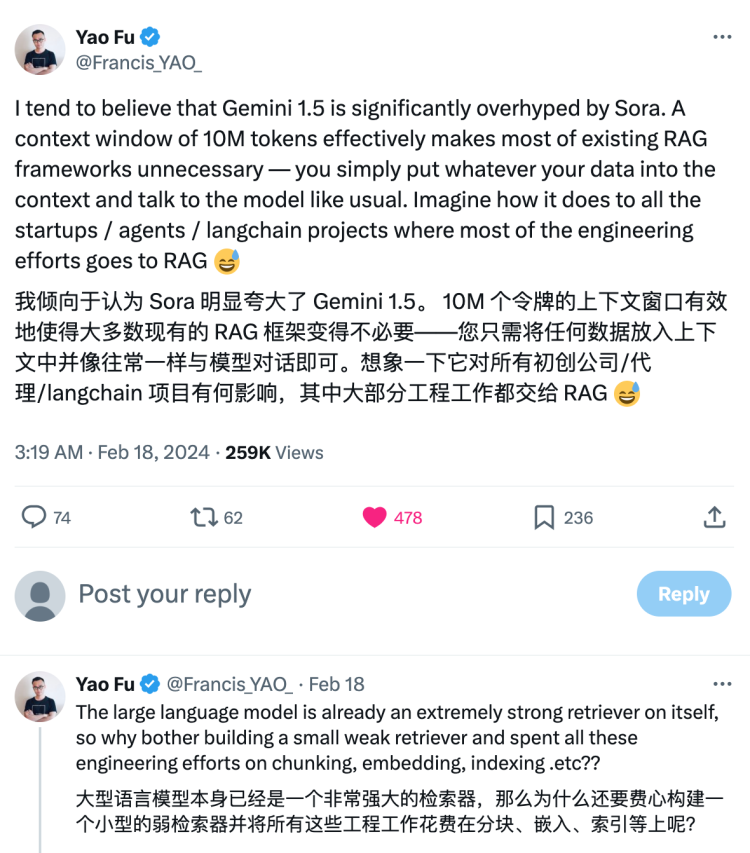 这个观点引发了巨大讨论,他也随后对这个看起来“暴论”式的判断所引发的反对观点做了进一步解释,值得一看。 其中最重要的,是长文本相比于RAG在解码过程中检索上的优越性: “RAG只在最开始进行检索。通常,给定一个问题,RAG会检索与该问题相关的段落,然后生成。长上下文对每一层和每个Token进行检索。在许多情况下,模型需要进行即时的每个Token的交错检索和推理,并且只有在获得第一个推理步骤的结果后才知道要检索什么。只有长上下文才能处理这种情况。 针对RAG支持1B级别的Token,而目前Gemini 1.5 pro支持的上下文长度是1M的问题: “确实如此,但输入文档存在自然分布,我倾向于相信大多数需要检索的案例都在百万级以下。例如,想象一个处理案例的层,其输入是相关的法律文件,或者一个学习机器学习的学生,其输入是三本机器学习书籍——感觉不像1B那么长,对吗?” “大内存的发展并不意味着硬盘的淘汰。”有人持更温和的观点。 出于成本和效率上的考虑,超长文本输入在这两方面显然并不成熟。因此哪怕面对10M Token的上下文输入上限,RAG仍然是必须的,就像我们时至今日仍然没有淘汰掉硬盘。
这个观点引发了巨大讨论,他也随后对这个看起来“暴论”式的判断所引发的反对观点做了进一步解释,值得一看。 其中最重要的,是长文本相比于RAG在解码过程中检索上的优越性: “RAG只在最开始进行检索。通常,给定一个问题,RAG会检索与该问题相关的段落,然后生成。长上下文对每一层和每个Token进行检索。在许多情况下,模型需要进行即时的每个Token的交错检索和推理,并且只有在获得第一个推理步骤的结果后才知道要检索什么。只有长上下文才能处理这种情况。 针对RAG支持1B级别的Token,而目前Gemini 1.5 pro支持的上下文长度是1M的问题: “确实如此,但输入文档存在自然分布,我倾向于相信大多数需要检索的案例都在百万级以下。例如,想象一个处理案例的层,其输入是相关的法律文件,或者一个学习机器学习的学生,其输入是三本机器学习书籍——感觉不像1B那么长,对吗?” “大内存的发展并不意味着硬盘的淘汰。”有人持更温和的观点。 出于成本和效率上的考虑,超长文本输入在这两方面显然并不成熟。因此哪怕面对10M Token的上下文输入上限,RAG仍然是必须的,就像我们时至今日仍然没有淘汰掉硬盘。  如果将上下文的窗口设定为1M,按现在0.0015美元/1000token的收费标准,一次请求就要花掉1.5美元,这么高的成本显然是无法实现日常使用的。 时间成本上,1M的上下文长度在Gemini 1.5 Pro的演示实例中,需要60秒来完成结果的输出——但RAG几乎是实时的。 付尧的观点更倾向于——“贵的东西,缺点只有贵”。 “RAG 很便宜,长上下文很昂贵。确实如此,但请记住,与 LLM 相比,BERT-small 也便宜,n-gram 更便宜,但今天我们已经不使用它们,因为我们希望模型首先变得智能,然后再变得智能模型更便宜。 ——人工智能的历史告诉我们,让智能模型变得更便宜比让廉价模型变得智能要容易得多——当它很便宜时,它就永远不会智能。” 一位开发者的观点代表了很多对这一切感到兴奋的技术人员:在这样一场技术革命的早期阶段,浪费一点时间可能也没有那么要紧。 “假设我花了5分钟或1小时(见鬼,即使花了一整天)才将我的整个代码库放入聊天的上下文窗口中。如果在那之后,人工智能能够像谷歌声称的那样,在剩下的对话中近乎完美地访问该上下文,我会高兴、耐心和感激地等待这段时间。”这位在一家数字产品设计公司中供职的博客作者里这样写道。 在这位开发者发布这条博客之前,CognosysAi的联创Sully Omarr刚刚往Gemini 1.5 Pro的窗口里塞进去一整个代码库,并且发现它被完全理解了,甚至Gemini 1.5 Pro辨别出了代码库中的问题并且实施了修复。 “这改变了一切。”Sully Omarr在X上感叹。 被改变的可能也包括与Langchain相关的一切。一位开发者引用了Sully Omarr的话,暗示Langchain甚至所有中间层玩家即将面临威胁。 向量数据库可能突然之间就变成了一个伪需求——客户直接把特定领域的知识一股脑儿扔进对话窗口就好了,为什么要雇人花时间来做多余的整理工作呢(并且人脑对信息的整理能力也比不过优秀的LLM)? 付尧的预测与这位开发者相似,甚至更具体——以Langchain 、LLaMA index这类框架作为技术栈的初创公司,会在2025年迎来终结。 但必须强调的是,付尧对于RAG的判断和解释弱化了在成本和响应速度上的考虑,原因或许是他正在为谷歌工作,而这两点仍然是让在当下RAG具备高价值的决定性因素。而如果看向这场上下文长度的讨论背后,谷歌在这场竞争中最大的优势开始展现出来了。 他拥有目前这个行业里最多的计算能力。换句话说,对于上下文长度极限的探索,目前只有谷歌能做,它也拿出来了。 从2014年至今,谷歌已经构建了6种不同的TPU芯片。虽然单体性能仍然与H100差距明显,但TPU更贴合谷歌自己生态内的系统。去年8月,SemiAnalysis的两位分析师Dylan Patel和Daniel Nishball揭露谷歌在大模型研发上的进展时表示,⾕歌模型FLOPS利⽤率在上一代TPU产品TPUv4上已经⾮常好,远超GPT-4。 目前谷歌最新的TPU产品是TPUv5e。两位分析师的调查显示,谷歌掌握的TPUv5e数量比OpenAI、Meta、CoreWeave、甲骨文和亚马逊拥有的GPU总和更多。文章里称TPUv5e将会用到谷歌最新的大模型(即是后来发布的Gemini系列)训练上,算力高达1e26 FLOPS,是GPT-4的5倍。
如果将上下文的窗口设定为1M,按现在0.0015美元/1000token的收费标准,一次请求就要花掉1.5美元,这么高的成本显然是无法实现日常使用的。 时间成本上,1M的上下文长度在Gemini 1.5 Pro的演示实例中,需要60秒来完成结果的输出——但RAG几乎是实时的。 付尧的观点更倾向于——“贵的东西,缺点只有贵”。 “RAG 很便宜,长上下文很昂贵。确实如此,但请记住,与 LLM 相比,BERT-small 也便宜,n-gram 更便宜,但今天我们已经不使用它们,因为我们希望模型首先变得智能,然后再变得智能模型更便宜。 ——人工智能的历史告诉我们,让智能模型变得更便宜比让廉价模型变得智能要容易得多——当它很便宜时,它就永远不会智能。” 一位开发者的观点代表了很多对这一切感到兴奋的技术人员:在这样一场技术革命的早期阶段,浪费一点时间可能也没有那么要紧。 “假设我花了5分钟或1小时(见鬼,即使花了一整天)才将我的整个代码库放入聊天的上下文窗口中。如果在那之后,人工智能能够像谷歌声称的那样,在剩下的对话中近乎完美地访问该上下文,我会高兴、耐心和感激地等待这段时间。”这位在一家数字产品设计公司中供职的博客作者里这样写道。 在这位开发者发布这条博客之前,CognosysAi的联创Sully Omarr刚刚往Gemini 1.5 Pro的窗口里塞进去一整个代码库,并且发现它被完全理解了,甚至Gemini 1.5 Pro辨别出了代码库中的问题并且实施了修复。 “这改变了一切。”Sully Omarr在X上感叹。 被改变的可能也包括与Langchain相关的一切。一位开发者引用了Sully Omarr的话,暗示Langchain甚至所有中间层玩家即将面临威胁。 向量数据库可能突然之间就变成了一个伪需求——客户直接把特定领域的知识一股脑儿扔进对话窗口就好了,为什么要雇人花时间来做多余的整理工作呢(并且人脑对信息的整理能力也比不过优秀的LLM)? 付尧的预测与这位开发者相似,甚至更具体——以Langchain 、LLaMA index这类框架作为技术栈的初创公司,会在2025年迎来终结。 但必须强调的是,付尧对于RAG的判断和解释弱化了在成本和响应速度上的考虑,原因或许是他正在为谷歌工作,而这两点仍然是让在当下RAG具备高价值的决定性因素。而如果看向这场上下文长度的讨论背后,谷歌在这场竞争中最大的优势开始展现出来了。 他拥有目前这个行业里最多的计算能力。换句话说,对于上下文长度极限的探索,目前只有谷歌能做,它也拿出来了。 从2014年至今,谷歌已经构建了6种不同的TPU芯片。虽然单体性能仍然与H100差距明显,但TPU更贴合谷歌自己生态内的系统。去年8月,SemiAnalysis的两位分析师Dylan Patel和Daniel Nishball揭露谷歌在大模型研发上的进展时表示,⾕歌模型FLOPS利⽤率在上一代TPU产品TPUv4上已经⾮常好,远超GPT-4。 目前谷歌最新的TPU产品是TPUv5e。两位分析师的调查显示,谷歌掌握的TPUv5e数量比OpenAI、Meta、CoreWeave、甲骨文和亚马逊拥有的GPU总和更多。文章里称TPUv5e将会用到谷歌最新的大模型(即是后来发布的Gemini系列)训练上,算力高达1e26 FLOPS,是GPT-4的5倍。  这个猜测在谷歌最新开源的Gemma身上得到了佐证。Gemma是Gemini的轻 量化版本,两者共享相同的基础框架和相关技术,而在Gemma放出的技术报告中表明,其训练已经完全基于TPUv5e。 这也不难理解为何奥特曼要花7万亿美元为新的算力需求未雨绸膜。虽然OpenAI拥有的总GPU数量在2年内增长了4倍。 “"In our research, we’ve also successfully tested up to 10 million tokens." (在研究中,我们也成功测试了多达10M Token)” 这被Sora暂时掩盖住的一次尝试或许在未来会作为生成式AI上的一个重要时刻被反复提及,它现在也真正让发明了transformer框架的谷歌,回归到这场本该由自己引领的竞争中了。 文末互动:
这个猜测在谷歌最新开源的Gemma身上得到了佐证。Gemma是Gemini的轻 量化版本,两者共享相同的基础框架和相关技术,而在Gemma放出的技术报告中表明,其训练已经完全基于TPUv5e。 这也不难理解为何奥特曼要花7万亿美元为新的算力需求未雨绸膜。虽然OpenAI拥有的总GPU数量在2年内增长了4倍。 “"In our research, we’ve also successfully tested up to 10 million tokens." (在研究中,我们也成功测试了多达10M Token)” 这被Sora暂时掩盖住的一次尝试或许在未来会作为生成式AI上的一个重要时刻被反复提及,它现在也真正让发明了transformer框架的谷歌,回归到这场本该由自己引领的竞争中了。 文末互动: 你看好谷歌Gemini的发展吗? 👇评论区留言告诉我们你的想法哦~

别忘了点关注,不迷路啊。
👇👇👇

 2024的初创公司,不蹭AI就融不到资?
2024的初创公司,不蹭AI就融不到资? 

评论