谷歌I/O时隔3年回归线下!发布新安卓新手机,还立下AR眼镜等一堆Flag

大数据文摘出品
作者:Caleb
“科技让所有人都过得更好。”
美国东部时间5月11日,谷歌召开2022年的Google I/O大会,时隔三年再度回归线下,劈柴哥登场时都忍不住调侃,“线上会议参加多了,老担心麦克风出问题”。
近两年,随着疫情和世界格局的不断变化和发展,谷歌也一直在寻找自己的落脚点。
比如,在疫情期间谷歌就利用Google Maps精准定位了疫苗接种点,也在最近的季风期帮助了成千上万的印度人逃往避难点。
再比如,在乌克兰,谷歌也部署了防控预警,在乌克兰与俄罗斯发生军事冲突期间,发出了数以万计的预警。
在波兰的谷歌员工也都收留了来自乌克兰的难民,为了更好地帮助他们沟通,Google Translate开发了单语版的翻译模型文本,也新增了24种语言。

今年的Google I/O推进得十分连贯,也可以看出谷歌正在朝着打造运行良好、协同工作的产品方向而努力。
搜索正在成为一个多感官、多设备的命题,在了解谁在搜索、在搜索什么之后,谷歌还扩展了搜索体验,远远超出了问答范围。
谷歌正在使安卓更具有上下文和内容感知能力,以便手机匹配用户的操作。
谷歌也一直强调自然交互,这样用户就可以在不死记硬背命令的情况下获取信息。
……
赶快和文摘菌来一睹今年Google I/O的风采吧~
LaMDA 2:3种模式解锁所有对话场景
既去年具有突破性的大型语言模型LaMDA后,谷歌推出了新一代的对话式AI模型LaMDA 2,以及一款名为AI Test Kitchen的新应用程序。
LaMDA 2是对第一代的更新,基本功能相同:跟它说话,它就会回话。但是Test Kitchen AI将系统包装在一个新的、可访问的界面中,鼓励用户就其性能提供反馈。
作为一个主打“对话应用程序”的人工智能系统,LaMDA 2可以理解数百万个主题并生成“自然对话”。与大多数AI系统一样的是,LaMDA 2可以根据许多文本示例来了解单词在文本主体中出现的可能性。示例以训练数据集中的文档形式出现,其中包含从社交媒体、维基百科、书籍、GitHub等软件托管平台以及公共网络上的其他来源抓取的TB到PB级数据。
这是为谷歌最新的人工智能模型创造一个实验空间。
该应用程序有3种模式,Imagine It,Talk About It和List It。
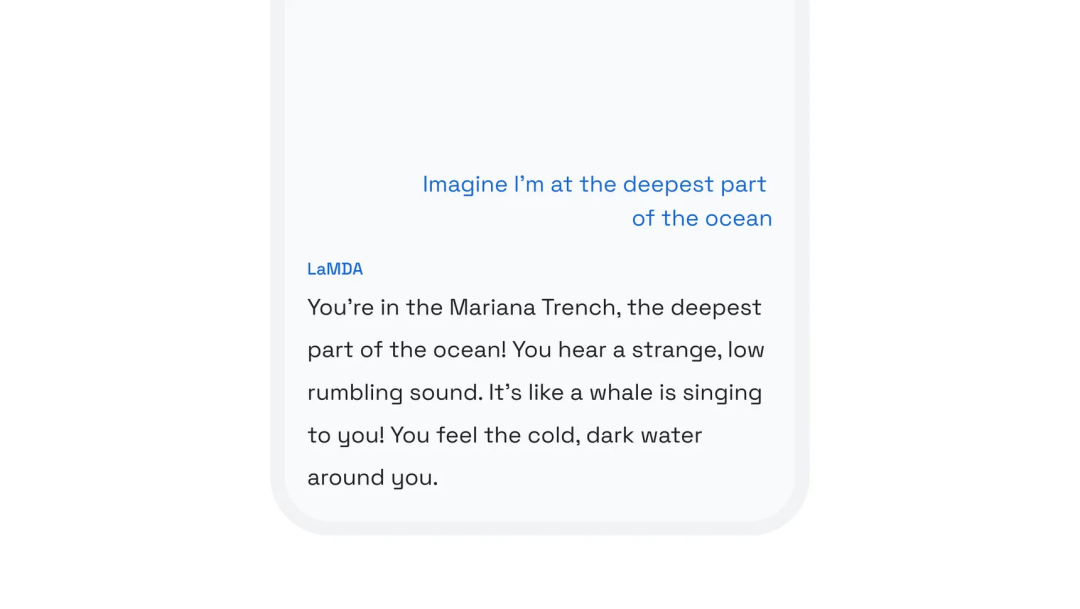
Imagine It就像一个简单的头脑风暴工具,该程序能够帮助想象是否处于某种场景中。比如,当用户输入,“我在海洋的最深处”时,程序就会用描述性语言输出一小段当用户身处马里亚纳海沟潜艇中时的场景。
其次,该程序可以与用户就某事进行对话,并了解上下文。比如,当程序提问,“有没有想过为什么狗那么喜欢玩捡东西游戏?”在回答简单的后续问题时,比如“为什么会这样”,系统会回答更多关于狗和它们的嗅觉的信息。
最后,AI Test Kitchen展示了LaMDA 2如何“分解复杂的目标或主题”。当用户提出“我想学尤克里里”或“我想种花园”之类的问题时,LaMDA 2会列出子任务列表,以帮助入门,甚至系统还可能提供一些没有想到的信息,比如除了提供可以种植的蔬菜的名称外,LaMDA 2还会提供后续的步骤以及需要考虑的天气因素。
劈柴哥表示,谷歌正在使用该程序收集对其新AI模型的反馈,并将“在未来几个月内开放访问,仔细评估来自广泛利益相关者的反馈,包括人工智能研究人员、社会科学家到人权专家”。这些发现将被纳入未来版本的LaMDA中,随着时间的推移,谷歌打算“继续将其他新兴的人工智能技术添加到AI Test Kitchen中”。
Android 13:更多可定制,更多安全
在今年的Google I/O上,谷歌为今年安卓的更新制定了总体愿景。
距离 Android 13 的第一个测试版发布仅几周时间,但谷歌推出了全新的测试版——Beta2。这一次,它与第三方制造商一起推出。包括一加、联想等在内的近十几家公司都参与了今天的升级。
继去年Material You可定制主题功能之后,安卓已经可以将其配色方案与手机壁纸的配色方案进行匹配。今年,媒体控件也进行了类似的修整,将能够从正在播放的音乐的专辑封面中提取颜色。

Google Messages的RCS支持也将得到重大改进,推出用于群聊的端到端加密测试版。对此谷歌表示,他们旨在成为SMS和MMS协议的继任者,现已可供全球超过5亿Google Messages用户使用。
正如测试版的那样,Android 13对应用程序默认使用的个人数据和手机功能设置了更多限制。很快,应用程序甚至必须首先请求许可才能发送通知,同时还有一个新的照片选择器,可让用户限制应用程序可以访问的照片和视频,而不是直接授予查看整个库的权限。这个权限还将限制应用程序访问“照片和视频”或“音乐和音频”文件,而不是所有文件类型。
同时,Android 13还将添加一个新的安全和隐私设置页面,以便在一个地方收集用户的所有关键数据隐私信息,这它旨在鼓励安卓用户解决可能出现的任何安全问题。
除此之外,谷歌还强调了其在与其他设备互连方面所做的工作。比如与今年秋季推出的Matter智能家居标准添加快速配对支持,Android 13也正在支持新的节能蓝牙LE音频标准。
最后值得一提的是,Android 13将允许用户在每个应用程序的基础上设置系统语言,该功能对于在不同情况下依赖不同语言的多语言用户很有帮助。
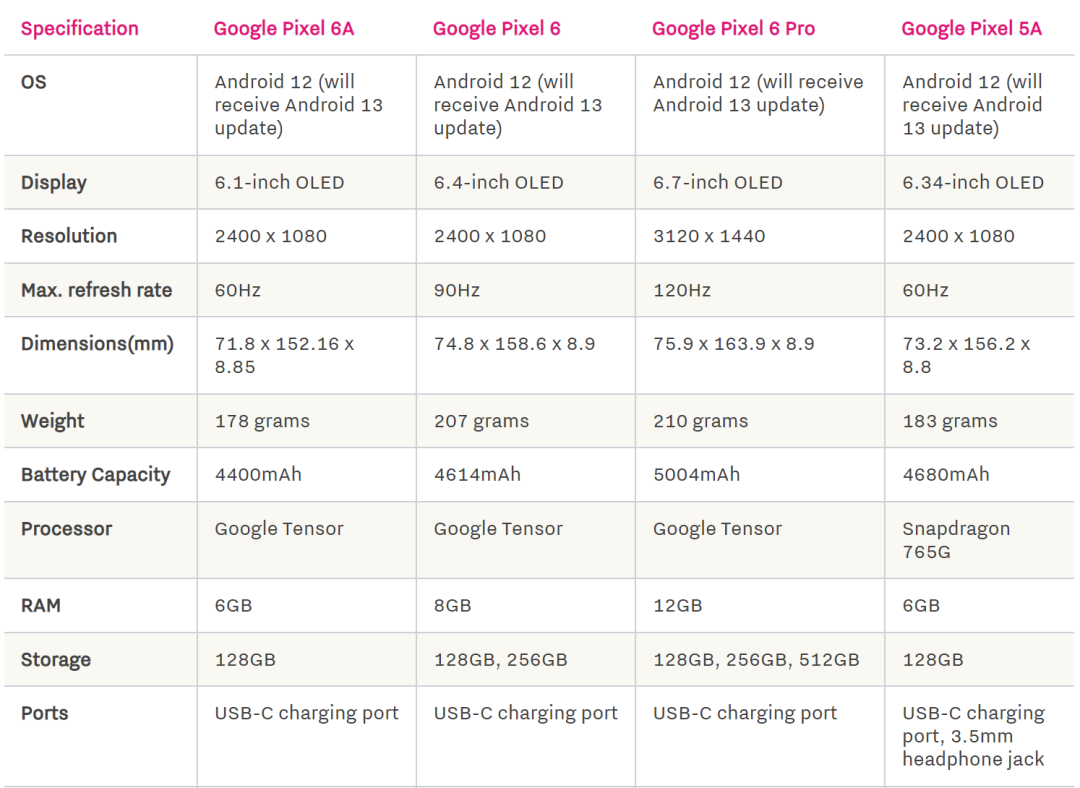
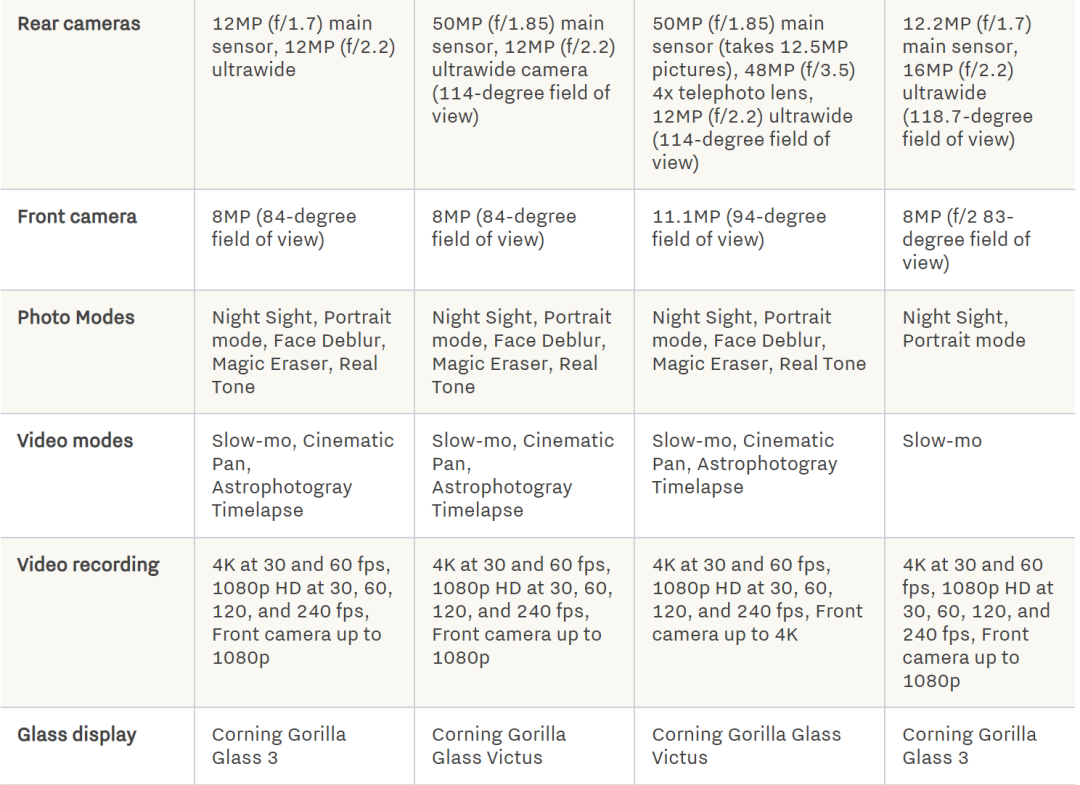
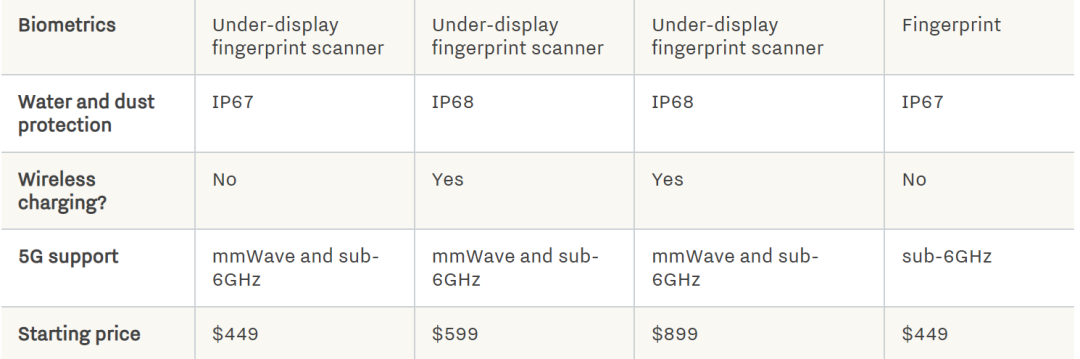
Pixel 6A:至少看起来很强大


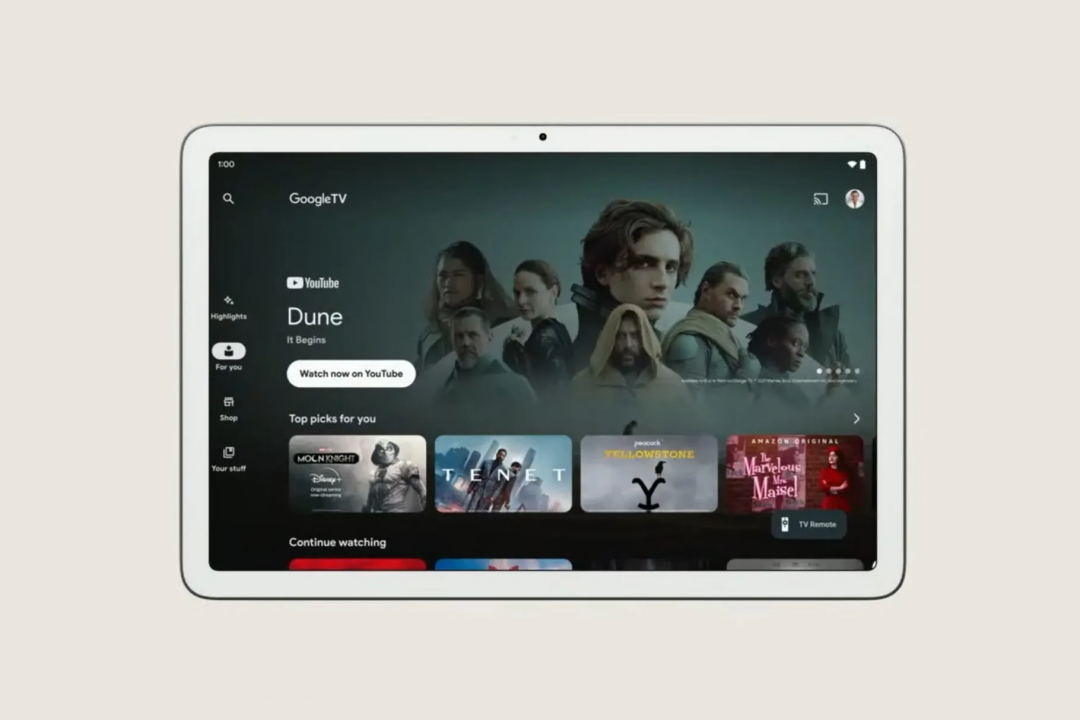
Google Maps推出沉浸式视图,还能“走”进商店
Google Maps也有所更新。
据介绍,Google Maps使用了新的沉浸式视图模式,用户可以从上方俯瞰某个位置了解周围的情况,比如实时交通信息。
沉浸式视图的图像都是通过计算机技术生成的,这结合了谷歌的卫星捕捉技术和街景照片。用户就能像在一个精准缩放的世界上玩视频游戏一样,正如谷歌工程副总裁Liz Reid所说的那样,“我们能够将这些融合在一起,真正理解更多信息,比如如何结合街景和鸟瞰图,如何让用户有身临其境的感觉等”。
有了沉浸式视图,用户不仅可以看到更细致的街景信息,还能够真正的走入商店,查看店内情况。
谷歌也公开了非洲建筑物数据集,这类数据集也已经被联合国等机构使用,以便提供更及时的紧急救援等。
沉浸式视图将适用于大多数设备,但迄今为止只有旧金山、纽约、洛杉矶、伦敦和东京的少数社区,未来还会辐射更多国家和地区。

Google Maps还推出了环保路线,截至目前已经帮助减少了50万吨的碳排放。
除了Google Maps的更新外,现在,唤醒Google Assistant也无需用Hey Google来唤醒了。
其中的一个方法便是Look and Talk,根据Google Assistant副总裁Sissie Hsiao的说法,这是一个可选功能。用户要打开该模式,就需要同时开启Face Match和Voice Match,开启后,用户就能在目光聚焦于屏幕的同时说出自己的需求或提出问题。
除了Look and Talk外,谷歌也引入了更多的快捷用语,比如定闹钟、开关灯等。

现在有7亿人每天都在使用Google Assistant,但这些交互还远远不够自然。
因此,谷歌选择利用6个机器学习模型,来实时处理来自摄像头和麦克风的100多个信号,比如注视方向、嘴唇运动、上下文感知和意图分类。
据了解,在搭载Tensor芯片的情况下,谷歌正在无限接近于实时对话的流畅性,可以超快速地处理设备上的机器学习任务。通过定制设计芯片,还可以超快速地处理设备上的机器学习任务。

同时,谷歌透露,他们正在构建新的、更强大的语音和语言模型,可以理解人类语音的细微差别,比如出现停顿但对话还在继续的时候。
Multisearch:更自然的搜索
搜索的逻辑正在被改写。
谷歌知识和信息产品高级副总裁Prabhakar Raghavan表示,“我们希望让用户周围的整个世界都可以被搜索,这样就可以通过对用户来说最自然的方式找到关于所看到、所听到和所体验的任何东西的有用信息”。
这就需要对搜索重新定义,不能局限于在搜索框中输入关键字。
最明显的成果是Multisearch。使用谷歌应用程序,用户可以拍摄一件连衣裙的照片,然后输入“green”细化自己的偏好,这是在文本框中无法做到的事情。
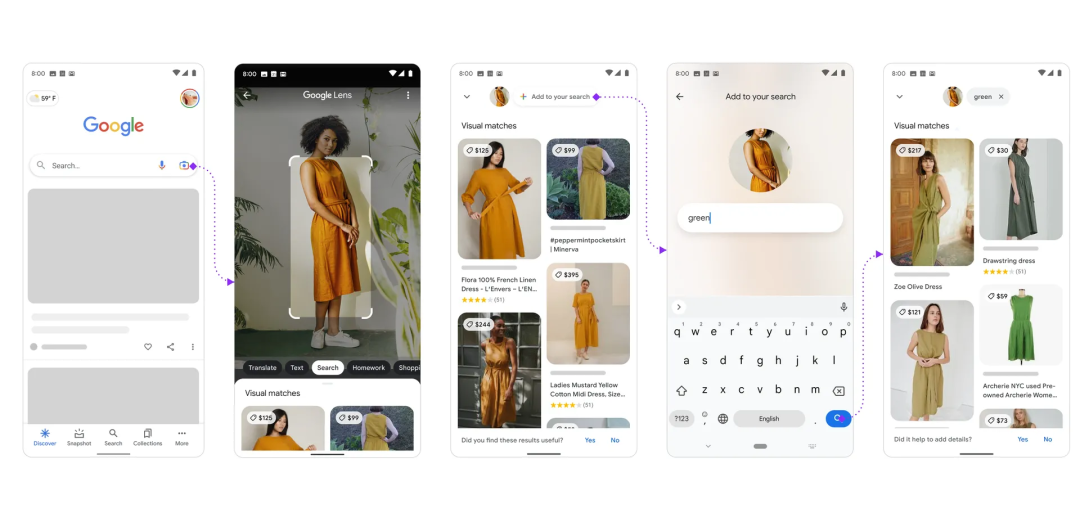
同时,谷歌还展示了一种工具,用于对包含多种内容的图像进行多重搜索。比如拍一张摆满了花生酱的货架的照片,输入“无坚果”,谷歌就会输出该买哪一个。
“我们发现,人们的一些信息需求往往难以表达,这就是我们解锁新功能的出发点。”搜索是一回事,Google Lens是一回事,语音又是另一回事,但当结合这三者时,新的事物就成为了一种可能。
Multisearch的扩展功能Multisearch Near Me也一起得到了公布。这一新增功能将允许用户把图片或屏幕截图与“附近”结合起来,以定向到当地零售商或餐厅。这还包括了一项即将开发的多重搜索,即通过手机摄像头的取景器“看到”的内容在场景中搜索多个对象。
当使用near me进行多搜索查询时,用户能够找到与当前视觉和基于文本的搜索组合相关的选项。比如正在DIY项目中遇到需要更换的零件,用户就可以用手机拍下该零件,系统就会对其识别,然后找到有库存的当地五金店。
“现在使用Google Lens进行视觉搜索每个月能达到80亿次,这是一年前的三倍。这也能看出,人们对视觉搜索的需求和渴望是存在的。而我们现在要做的是精益求精,找出最有用的地方。我认为,当我们思考搜索的未来时,视觉搜索绝对是其中的关键部分。”

而场景理解的进步,不仅可以体现在日常生活中,还能超越日常,应对更多更紧迫的社会挑战,比如识别森林或草地上需要保护的物种,以及在混乱中快速识别并分类捐赠物。
AI伦理的新尝试
在今年的大会上,谷歌在AI伦理方面也做出了不小的努力。
谷歌宣布与哈佛大学社会学助理教授、Monk Skin Tone(MST)的创造者Ellis Monk合作。MST这种肤色量表是一个10分制的量表,更具代表性,并包含更多肤色,尤其深色人种。

但是,创建新的肤色量表还只是第一步,真正的挑战是将这项工作整合到现实中。为了推广MST量表,谷歌创建了网站skintone.google,专门解释其在人工智能中的研究和最佳实践。谷歌表示,他们正在努力将MST量表应用到一些产品上,比如“Real Tone”照片滤镜。
据了解,谷歌正在为图像搜索引入一项新功能,让用户可以根据MST量表对肤色进行细化搜索。如果用户搜索“眼妆”或“新娘妆容”,就可以按肤色过滤结果,这样得到的结果就不会是清一色的白人面孔。
而谷歌也将开放肤色量表的源代码,通过与社会各界人士地合作,不断改善系统,以更包容的模式为图片中的肤色和发色等进行标注。

在隐私方面,谷歌还宣布了一系列新的隐私措施,帮助用户更好地控制他们的数据。
比如新推出的My Ad Center可以让用户通过从他们感兴趣的一系列主题中来自定义他们希望看到的广告类型,或者在给定主题上看到更少的广告。这将帮助用户控制他们的数据使用方式,以及改善他们的网络体验。
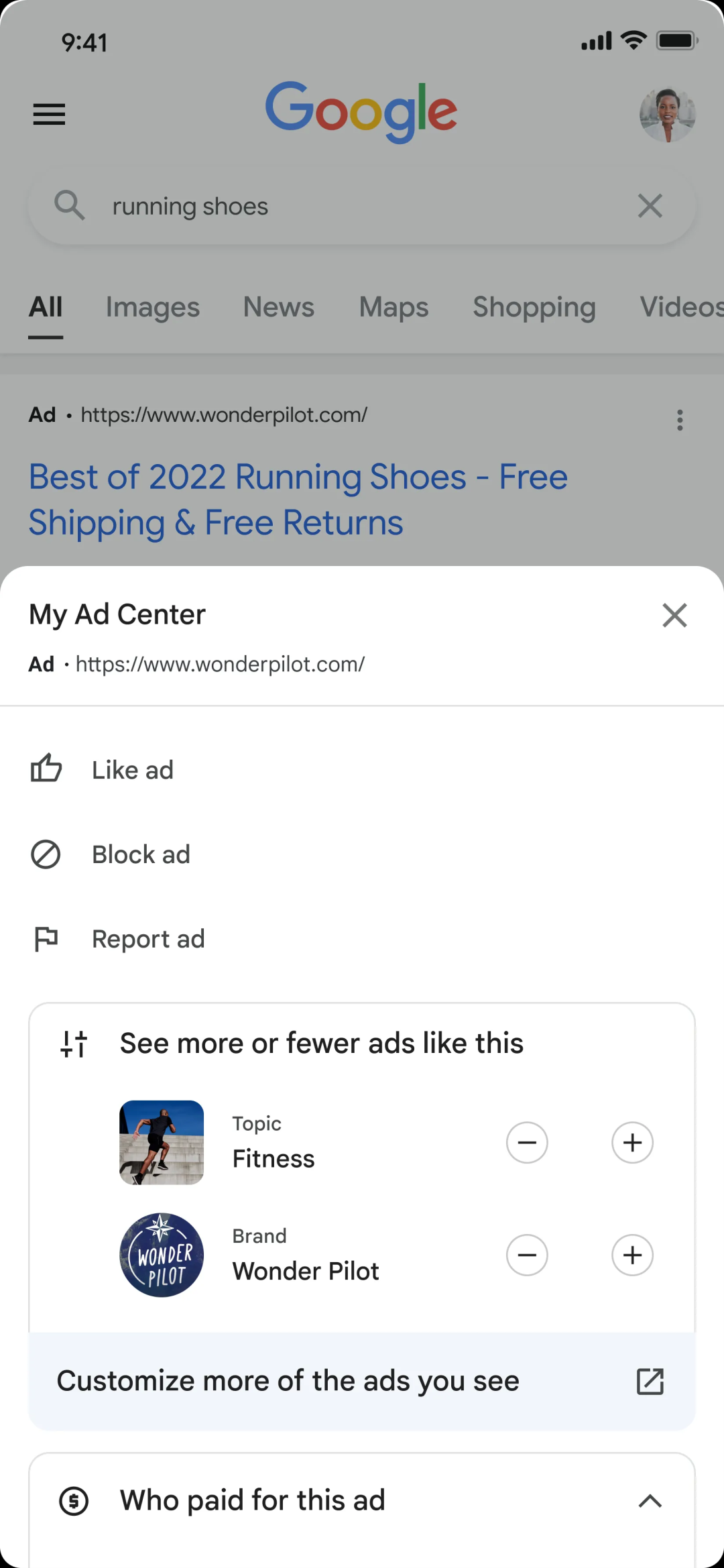
除此之外,用户还将能够通过一种新工具,请求从搜索结果中删除自己的电子邮件或地址详细信息等个人信息。
谷歌核心系统和体验高级副总裁Jen Fitzpatrick还强调了“受保护的计算”(protected computing)的概念。简单来说,这意味着更多数据将无需发送到谷歌云服务器;而当用户信息被发送到谷歌服务器时,这些信息将通过使用差分隐私和边缘计算等技术匿名化。
今年的Google I/O,既像是一场正经的开发者大会,又像是一次立flag大会,我们能看到新的安卓系统、新的Pixel A系列手机、更智能的搜索系统和语音助手,还能看到谷歌画的智能家居、智能手表、平板电脑的大饼。
但不管怎样,尽情期待就对了!