
阿里云原生技术架构白皮书(附下载)


关于云原生的定义,版本众多,云原生架构的理解也不尽相同,阿里根据自身的云原生技术、产品和上云实践,给出自己的理解。
从技术的角度,云原生架构是基于云原生技术的一组架构原则和设计模式的集合,旨在将云应用中的非业务代码部分进行最大化的剥离,从而让云设施接管应用中原有的大量非功能特性(如弹性、韧性、安全、可观测性、灰度等),使业务不再有非功能性业务中断困扰的同时,具备轻量、敏捷、高度自动化的特点。

业务代码、三方软件、处理非功能特性的代码中只有业务代码是核心,是对业务真正带来价值的,另外两个部分都只算附属物,但随着软件规模的增大、业务模块规模变大、部署环境增多、分布式复杂性增强,使得今天的软件构建变得越来越复杂,对开发人员的技能要求也越来越高。
云原生架构相比较传统架构进了一大步,从业务代码中剥离了大量非功能性特性(不会是所有,比如易用性还不能剥离)到 IaaS 和 PaaS 中,从而减少业务代码开发人员的技术关注范围,通过云厂商的专业性提升应用的非功能性能力。此外,具备云原生架构的应用可以最大程度利用云服务和提升软件交付能力,进一步加快软件开发。
云原生架构有非常多的架构模式,这里选取一些对应用收益更大的主要架构模式进行讨论。
服务化架构是云时代构建云原生应用的标准架构模式,要求以应用模块为颗粒度划分一个软件,以接口契约(例如 IDL)定义彼此业务关系,以标准协议(HTTP、gRPC 等)确保彼此的互联互通,结合 DDD(领域模型驱动)、TDD(测试驱动开发)、容器化部署提升每个接口的代码质量和迭代速度。服务化架构的典型模式是微服务和小服务(Mini Service)模式,其中小服务可以看做是一组关系非常密切的服务的组合,这组服务会共享数据,小服务模式通常适用于非常大型的软件系统,避免接口的颗粒度太细而导致过多的调用损耗和治理复杂度。
通过服务化架构,把代码模块关系和部署关系进行分离,每个接口可以部署不同数量的实例,单独扩缩容,从而使得整体的部署更经济。
Mesh化架构是把中间件框架(比如 RPC、缓存、异步消息等)从业务进程中分离,让中间件SDK与业务代码进一步解耦,从而使得中间件升级对业务进程没有影响,甚至迁移到另外一个平台的中间件也对业务透明。分离后在业务进程中只保留很“薄”的Client部分,Client 通常很少变化,只负责与 Mesh 进程通讯,原来需要在SDK中处理的流量控制、安全等逻辑由 Mesh 进程完成。

实施 Mesh 化架构后,大量分布式架构模式(熔断、限流、降级、重试、反压、隔仓等)都由Mesh进程完成,即使在业务代码的制品中并没有使用这些三方软件包;同时获得更好的安全性(比如零信任架构能力)、按流量进行动态环境隔离、基于流量做冒烟/回归测试等。
Serverless 将“部署”这个动作从运维中“收走”,使开发者不用关心应用在哪里运行,更不用关心装什么 OS、怎么配置网络、需要多少 CPU …… 从架构抽象上看,当业务流量到来/业务事件发生时,云会启动或调度一个已启动的业务进程进行处理,处理完成后云自动会关闭/调度业务进程,等待下一次触发,也就是把应用的整个运行时都委托给云。
今天Serverless还没有达到任何类型的应用都适用的地步,因此架构决策者需要关心应用类型是否适合于 Serverless 运算。如果应用是有状态的,云在进行调度时可能导致上下文丢失,毕竟Serverless的调度不会帮助应用做状态同步;如果应用是长时间后台运行的密集型计算任务,会得不到太多Serverless的优势;如果应用涉及到频繁的外部I/O(网络或者存储,以及服务间调用),也因为繁重的I/O负担、时延大而不适合。Serverless非常适合于事件驱动的数据计算任务、计算时间短的请求/响应应用、没有复杂相互调用的长周期任务。
分布式环境中的CAP困难主要是针对有状态应用,因为无状态应用不存在C(一致性)这个维度,因此可以获得很好的A(可用性)和P(分区容错性),因而获得更好的弹性。在云环境中,推荐把各类暂态数据(如session)、结构化和非结构化持久数据都采用云服务来保存,从而实现存储计算分离。但仍然有一些状态如果保存到远端缓存,会造成交易性能的明显下降,比如交易会话数据太大、需要不断根据上下文重新获取等,则可以考虑通过采用 Event Log + 快照(或 Check Point)的方式,实现重启后快速增量恢复服务,减少不可用对业务的影响时长。
1)传统采用XA模式,虽然具备很强的一致性,但是性能差;
2)基于消息的最终一致性(BASE)通常有很高的性能,但是通用性有限,且消息端只能成功而不能触发消息生产端的事务回滚;
3)TCC模式完全由应用层来控制事务,事务隔离性可控,也可以做到比较高效;但是对业务的侵入性非常强,设计开发维护等成本很高;
4)SAGA 模式与TCC模式的优缺点类似但没有 try 这个阶段,而是每个正向事务都对应一个补偿事务,也是开发维护成本高;
5)开源项目 SEATA 的 AT 模式非常高性能且无代码开发工作量,且可以自动执行回滚操作,同时也存在一些使用场景限制。
可观测架构包括Logging、Tracing、Metrics三个方面,其中Logging提供多个级别的详细信息跟踪,由应用开发者主动提供;Tracing 提供一个请求从前端到后端的完整调用链路跟踪,对于分布式场景尤其有用;Metrics则提供对系统量化的多维度度量。
架构决策者需要选择合适的、支持可观测的开源框架(比如OpenTracing、OpenTelemetry),并规范上下文的可观测数据规范(例如方法名、用户信息、地理位置、请求参数等),规划这些可观测数据在哪些服务和技术组件中传播,利用日志和tracing信息中的span id/trace id,确保进行分布式链路分析时有足够的信息进行快速关联分析。
由于建立可观测性的主要目标是对服务 SLO(Service Level Objective)进行度量,从而优化 SLA,因此架构设计上需要为各个组件定义清晰的SLO,包括并发度、耗时、可用时长、容量等。
事件驱动架构(EDA,Event Driven Architecture)本质上是一种应用/ 组件间的集成架构模式,典型的事件驱动架构如下图。
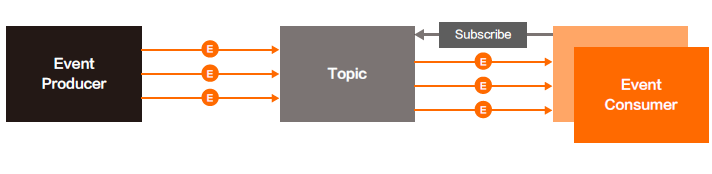
事件和传统的消息不同,事件具有schema,所以可以校验event 的有效性,同时EDA 具备QoS保障机制,也能够对事件处理失败进行响应。事件驱动架构不仅用于(微)服务解耦,还可应用于下面的场景中。
增强服务韧性:由于服务间是异步集成的,也就是下游的任何处理失败甚至宕机都不会被上游感知,自然也就不会对上游带来影响;
CQRS(Command Query Responsibility Segregation):把对服务状态有影响的命令用事件来发起,而对服务状态没有影响的查询才使用同步调用的API 接口;结合 EDA 中的 Event Sourcing 可以用于维护数据变更的一致性,当需要重新构建服务状态时,把EDA 中的事件重新“播放”一遍即可;
数据变化通知:在服务架构下,往往一个服务中的数据发生变化,另外的服务会感兴趣,比如用户订单完成后,积分服务、信用服务等都需要得到事件通知并更新用户积分和信用等级;
构建开放式接口:在 EDA 下,事件的提供者并不用关心有哪些订阅者,不像服务调用的场景 —— 数据的产生者需要知道数据的消费者在哪里并调用它,因此保持了接口的开放性;
事件流处理:应用于大量事件流(而非离散事件)的数据分析场景,典型应用是基于 Kafka 的日志处理;
基于事件触发的响应:在 IoT 时代大量传感器产生的数据,不会像人机交互一样需要等待处理结果的返回,天然适合用EDA来构建数据处理应用。
>>参考来源:云原生技术架构白皮书
>>白皮书下载:
链接:
https://pan.baidu.com/s/1veSg3tpt3uJMWbN4M7B7yA
提取码: yk87
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师技术全联盟书店”相关电子书(35本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“架构师技术全店打包汇总(全)”,后续可享全店内容更新“免费”赠阅,价格仅收188元(原总价290元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
