
如何用 Python 实现一个图数据库(Graph Database)?
△点击上方“Python猫”关注 ,回复“1”领取电子书

本文章是 重写 500 Lines or Less 系列的其中一篇,目标是重写 500 Lines or Less 系列的原有项目:Dagoba: an in-memory graph database。
背景
Dagoba 是作者设计用来展示如何从零开始自己实现一个图数据库(Graph Database)。该名字似乎来源于作者喜欢的一个乐队,另一个原因是它的前缀 DAG 也正好是有向无环图 (Directed Acyclic Graph) 的缩写。本文也沿用了该名称。
图是一种常见的数据结构,它将信息描述为若干独立的节点(vertex,为了和下文的边更加对称,本文中称为 node),以及把节点关联起来的边(edge)。我们熟悉的链表以及多种树结构可以看作是符合特定规则的图。图在路径选择、推荐算法以及神经网络等方面都是重要的核心数据结构。
既然图的用途如此广泛,一个重要的问题就是如何存储它。如果在传统的关系数据库中存储图,很自然的做法就是为节点和边各自创建一张表,并用外键把它们关联起来。这样的话,要查找某人所有的子女,就可以写下类似下面的查询:
select nodes.* from nodes, edges
on nodes.id=edges.in
where nodes.name='Jack' and edges.type='child'
还好,不算太复杂。但是如果要查找孙辈呢?那恐怕就要使用子查询或者 CTE(Common Table Expression) 等特殊构造了。再往下想,曾孙辈又该怎么查询?孙媳妇呢?
这样我们会意识到,SQL 作为查询语言,它只是对二维数据表这种结构而设计的,用它去查询图的话非常笨拙,很快会变得极其复杂,也难以扩展。针对图而言,我们希望有一种更为自然和直观的查询语法,类似这样:
node('someone').children.children
为了高效地存储和查询图这种数据结构,图数据库(Graph Database)应运而生。因为和传统的关系型数据库存在极大的差异,所以它属于新型数据库也就是 NoSql 的一个分支(其他分支包括文档数据库、列数据库等)。图数据库的主要代表包括 Neo4J 等。本文介绍的 Dagoba 则是具备图数据库核心功能、主要用于教学和演示的一个简单的图数据库。
改写
原文代码是使用 JavaScript 编写的,在定义调用接口时大量使用了原型(prototype)这种特有的语言构造。对于其他主流语言的用户来说,原型的用法多少显得有些别扭和不自然。考虑到本系列其他数据库示例大多是用 Python 实现的,本文也按照传统,用 Python 重写了原文的代码。同样延续之前的惯例,为了让读者更好地理解程序是如何逐步完善的,我们用迭代式的方法完成程序的各个组成部分。
原文在 500lines 系列的 Github 仓库中只包含了实现代码,并未包含测试。按照代码注释说明,测试程序位于作者的另一个代码库中,不过和 500lines 版本的实现似乎略有不同。本文实现的代码参考了原作者的测试内容,但跳过了北欧神话这个例子————我承认确实不熟悉这些神祇之间的亲缘关系,相信中文背景的读者们多数也未必了解,虽然作者很喜欢这个例子,想了想还是不要徒增困惑吧。因此本文在编写测试用例时只参考了原文关于家族亲属的例子,放弃了神话相关的部分,尽管会减少一些趣味性,相信对于入门级的代码来说这样也够用了。
源码
本文实现程序位于代码库的 dagoba 目录下。按照本系列程序的同意规则,要想直接执行各个已完成的步骤,读者可以在根目录下的 main.py 找到相应的代码位置,取消注释并运行即可。
本程序的所有步骤只需要 Python3,测试则使用内置的 unittest, 不需要额外的第三方库。原则上Python3.6 以上版本应该都可运行,但我只在 Python3.8.3 环境下完整测试过。如果读者发现版本兼容性问题的话,也欢迎来信或者发 issue 告知我。
实现
本文实现的程序从最简单的案例开始,通过每个步骤逐步扩展,最终形成一个完整的程序。这些步骤包括:
创建数据模型 管理数据主键 实现主动查询 添加双向关联支持 实验延迟查询 提高访问效率 自定义查询方法
接下来依次介绍各个步骤。
步骤0:创建数据模型
回想一下,图数据库就是一些点(node)和边(edge)的集合。现在我们要做出的一个重大决策是如何对节点/边进行建模。对于边来说,必须指定它的关联关系,也就是从哪个节点指向哪个节点。大多数情况下边是有方向的——父子关系不指明方向可是要乱套的!此外,一个图中通常同时存在多种关联类型,比如家族产品中通常包含父子、兄弟、姐妹、夫妻,而社交产品一般有关注、引用、跟随、成员、兴趣等。至于节点内容,则是根据具体需要而定,各种应用之间往往差别很大,数据库本身是无法预先决定的。
考虑到扩展性及通用性问题,我们可以把数据保存为字典(dict),这样可以方便地添加用户需要的任何数据。某些数据是为数据库内部管理而保留的,为了明确区分,可以这样约定:以下划线开头的特殊字段由数据库内部维护,类似于私有成员,用户不应该自己去修改它们。这也是 Python 社区普遍遵循的约定。
此外,节点和边存在互相引用的关系。目前我们知道边会引用到两端的节点,后面还会看到,为了提高效率,节点也会引用到边。如果仅仅在内存中维护它们的关系,那么使用指针访问是很直观的,但数据库必须考虑到序列化到磁盘的问题,这时指针就不再好用了。为此,最好按照数据库的一般要求,为每个节点维护一个主键(_id),用主键来描述它们之间的关联关系。
我们第一步要把数据库的模型建立起来。为了测试目的,我们使用一个最简单的数据库模型,它只包含两个节点和一条边,如下所示:
按照 TDD 的原则,首先编写测试:
class DbModelTest(TestCase):
nodes = [
{'_id': 1, 'name': 'foo'},
{'_id': 2, 'name': 'bar'},
]
edges = [
{'_from': 1, '_to': 2},
]
def setUp(self):
self.db = Dagoba(self.nodes, self.edges)
与原文一样,我们把数据库管理接口命名为 Dagoba。目前,能够想到的最简单的测试是确认节点和边是否已经添加到数据库中:
def test_nodes(self):
nodes = list(self.db.nodes())
self.assertEqual(2, len(nodes))
self.assert_item(nodes, _id=1, name='foo')
self.assert_item(nodes, _id=2, name='bar')
def test_edges(self):
edges = list(self.db.edges())
self.assertEqual(1, len(edges))
self.assert_item(edges, _from=1, _to=2)
assert_item 是一个辅助方法,用于检查字典是否包含预期的字段。相信大家都能想到该如何实现,这里就不再列出了,读者可参考 Github 上的完整源码。
现在,测试是失败的。用最简单的办法实现数据库:
class Dagoba:
def __init__(self, nodes=None, edges=None):
self._nodes = []
self._edges = []
for node in (nodes or []):
self.add_node(node)
for edge in (edges or []):
self.add_edge(edge)
def add_node(self, node):
self._nodes.append(node.copy())
def add_edge(self, edge):
self._edges.append(edge.copy())
def nodes(self):
return (x.copy() for x in self._nodes)
def edges(self):
return (x.copy() for x in self._edges)
需要注意的是,不管添加节点还是查询,程序都使用了拷贝后的数据副本,而不是直接使用原始数据。为什么要这样做?因为字典是可变的,用户可以在任何时候修改其中的内容,如果数据库不知道数据已经变化,就很容易发生难以追踪的一致性问题,最糟糕的情况下会使得数据内容彻底混乱。拷贝数据可以避免上述问题,代价则是需要占用更多内存和处理时间。对于数据库来说,通常查询次数要远远多于修改,所以这个代价是可以接受的。
现在测试应该正常通过了。为了让它更加完善,我们可以再测试一些边缘情况,看看数据库能否正确处理异常数据,比如:
添加重复(主键相同)的记录 添加指向节点无效的边 获取主键不存在的节点
例如,如果用户尝试添加重复主键,我们预期应抛出 ValueError 异常。因此编写测试如下:
def test_nodes_with_duplicate_id(self):
nodes = [
{'_id': 1, 'name': 'foo'},
{'_id': 1, 'name': 'bar'},
]
with self.assertRaises(ValueError):
Dagoba(nodes, self.edges)
为了满足以上测试,代码需要稍作修改。特别是按照 id 查找主键是个常用操作,通过遍历的方法效率太低了,最好是能够通过主键直接访问。因此在数据库中再增加一个字典:
class Dagoba:
def __init__(self, nodes=None, edges=None):
...
self._nodes_by_id = {}
def add_node(self, node):
pk = node.get('_id', None)
if pk in self._nodes_by_id:
raise ValueError(f'Node with _id={pk} already exists.')
node = node.copy()
self._nodes.append(node)
self._nodes_by_id[pk] = node
完整代码请参考 Github 仓库。
步骤1:管理主键
在上个步骤,我们在初始化数据库时为节点明确指定了主键。按照数据库设计的一般原则,主键最好是不具有业务含义的代理主键(Surrogate key),用户不应该关心它具体的值是什么,因此让数据库去管理主键通常是更为合理的。当然,在部分场景下————比如导入外部数据————明确指定主键仍然是有用的。为了同时支持这些要求,我们这样约定:字段 _id 表示节点的主键,如果用户指定了该字段,则使用用户设置的值(当然,用户有责任保证它们不会重复);否则,由数据库自动为它分配一个主键。
如果主键是数据库生成的,事先无法预知它的值是什么,而边(edge)必须指定它所指向的节点,因此必须在主键生成后才能添加。由于这个原因,在动态生成主键的情况下,数据库的初始化会略微复杂一些。还是先写一个测试:
class PrimaryKeyTest(TestCase):
def test_nodes(self):
db = Dagoba()
pk1 = db.add_node({'name': 'foo'})
pk2 = db.add_node({'name': 'bar'})
db.add_edge({'_from': pk1, '_to': pk2})
self.assertIsNotNone(db.node(pk1))
self.assertIsNotNone(db.node(pk2))
self.assertTrue(pk1 != pk2)
为支持此功能,我们在数据库中添加一个内部字段 _next_id 用于生成主键,并让 add_node() 方法返回新生成的主键:
class Dagoba:
def __init__(self, nodes=None, edges=None):
...
self._next_id = 1
def add_node(self, node):
...
pk = node.get('_id', None)
if pk in self._nodes_by_id:
raise ValueError(f'Node with _id={pk} already exists.')
if not pk:
pk = self._next_id
node['_id'] = pk
self._next_id += 1
...
return pk
接下来,再确认一下边是否可以正常访问:
def test_edge(self):
edge = self.get_item(self.db.edges(), _from=self.pk1, _to=self.pk2)
self.assertIsNotNone(edge)
运行测试,一切正常。这个步骤很轻松地完成了,不过两个测试(DbModelTest和PrimaryKeyTest)出现了一些重复代码,比如 get_item()。我们可以把这些公用代码提取出来。由于 get_item() 内部调用了 TestCase.assertXXX() 等方法,看起来应该使用继承,但从 TestCase 派生基类容易引起一些潜在的问题,所以我转而使用另一个技巧 Mixin:
class DbModelTest(TestCase, fixtures.TestMixin):
...
步骤2:实现主动查询
实现数据库模型之后,接下来就要考虑如何查询它了。
在设计查询时要考虑几个问题。对于图的访问来说,几乎总是由某个节点(或符合条件的某一类节点)开始,从与它相邻的边跳转到其他节点,依次类推。所以链式调用对查询来说是一种很自然的风格。举例来说,要知道 Tom 的孙子养了几只猫,可以使用类似这样的查询:
node('Tom').children().children().pet('cat')
可以想象,以上每个方法都应该返回符合条件的节点集合。这种实现是很直观的,不过存在一个潜在的问题:很多时候用户只需要一小部分结果,如果它总是不计代价地给我们一个巨大的集合,会造成极大的浪费。比如以下查询:
node('Tom').children().children().take(1)
为了避免不必要的浪费,我们需要另外一种机制,也就是通常所称的“懒式查询”或“延迟查询”。它的基本思想是,当我们调用查询方法时,它只是把查询条件记录下来,而并不立即返回结果,直到明确调用某些方法时才真正去查询数据库。如果读者比较熟悉流行的 Python ORM,比如 SqlAlchemy 或者 Django ORM 的话,会知道它们几乎都是懒式查询的,要调用 list(result) 或者 result[0:10] 这样的方法才能得到具体的查询结果。
在 Dagoba 中把触发查询的方法定义为 run()。也就是说,以下查询执行到 run 时才真正去查找数据:
node('Tom').children().children().take(1).run()
和懒式查询(Lazy Query)相对应的,直接返回结果的方法一般称作主动查询(Eager Query)。主动查询和懒式查询的内在查找逻辑基本上是相同的,区别只在于触发机制不同。由于主动查询实现起来更加简单,出错也更容易排查,因此我们先从主动查询开始实现。
还是从测试开始。前面测试所用的简单数据库数据太少,难以满足查询要求,所以这一步先来创建一个更复杂的数据模型:
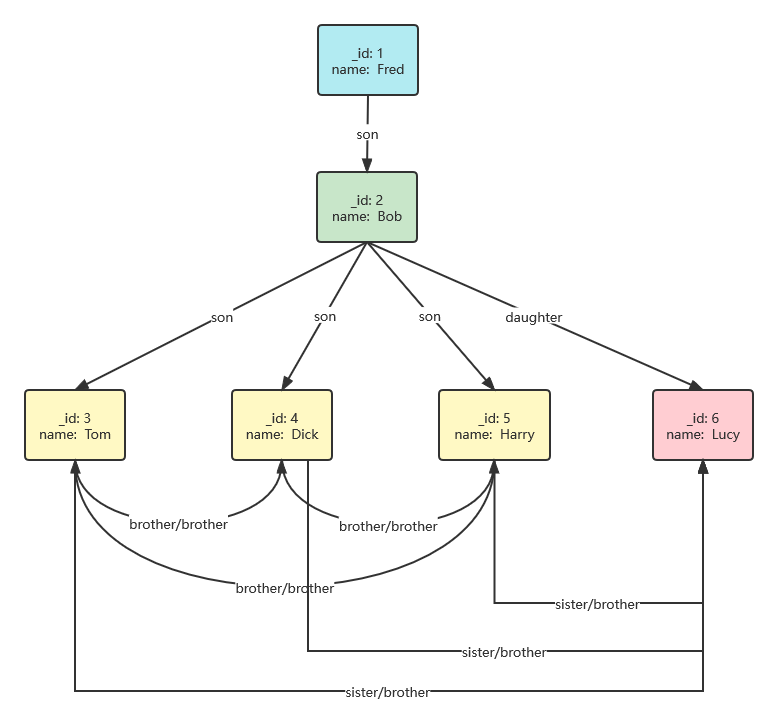
此关系的复杂之处之一在于反向关联:如果 A 是 B 的哥哥,那么 B 就是 A 的弟弟/妹妹,为了查询到他们彼此之间的关系,正向关联和反向关联都需要存在,因此在初始化数据库时需要定义的边数量会很多。当然,父子之间也存在反向关联的问题,为了让问题稍微简化一些,我们目前只需要向下(子孙辈)查找,可以稍微减少一些关联数量。
因此,我们定义数据模型如下。为了减少重复工作,我们通过 _backward 字段定义反向关联,而数据库内部为了查询方便,需要把它维护成两条边:
class EagerQueryTest(TestCase):
nodes = [
{'_id': 1, 'name': 'Fred'},
...
{'_id': 6, 'name': 'Lucy'},
]
edges = [
{'_from': 1, '_to': 2, '_type': 'son'},
...
{'_from': 3, '_to': 6, '_type': 'sister', '_backward': 'brother'},
...
]
然后,测试一个最简单的查询,比如查找某人的所有孙辈:
def test_grandkids(self):
nodes = self.q.node(1).outcome().outcome().run()
self.assert_nodes(nodes, [3, 4, 5, 6])
这里 outcome/income() 分别表示从某个节点出发、或到达它的节点集合。在原作者的代码中把上述方法称为 out/in()。当然这样看起来更加简洁,可惜的是 in 在 Python 中是个关键字,无法作为函数名。我也考虑过加个下划线比如 out_().in_() 这种形式,但看起来也有点怪异,权衡之后还是使用了稍微啰嗦一点的名称。
现在我们可以开始定义查询接口了。在前面已经说过,我们计划分别实现两种查询,包括主动查询(Eager Query)以及延迟查询(Lazy Query)。它们的内在查询逻辑是相通的,看起来似乎可以使用继承。不过遵循 YAGNI 原则,目前先不这样做,而是只定义两个新类,在满足测试的基础上不断扩展。以后我们会看到,与继承相比,把共同的逻辑放到数据库本身其实是更为合理的。
class Dagoba:
def query(self, eager=False):
return EagerQuery(self) if eager else LazyQuery(self)
class EagerQuery:
def __init__(self, db):
self._db = db
class LazyQuery:
def __init__(self, db):
self._db = db
接下来实现访问节点的方法。由于 EagerQuery 调用查询方法会立即返回结果,我们把结果记录在 _result 内部字段中。虽然 node() 方法只返回单个结果,但考虑到其他查询方法几乎都是返回集合,为统一起见,让它也返回集合,这样可以避免同时支持集合与单结果的分支处理,让代码更加简洁、不容易出错。此外,如果查询对象不存在的话,我们只返回空集合,并不视为一个错误。
class EagerQuery:
def __init__(self, db):
self._db = db
self._result = None
def node(self, pk: int):
try:
self._result = [self._db.node(pk)]
except KeyError:
self._result = []
return self
查询输入/输出节点的方法实现类似这样:
def outcome(self, type_=None):
result = []
for node in self._result:
pk = Dagoba.pk(node)
result.extend(self._db.outcome(pk, type_))
self._result = result
return self
查找节点的核心逻辑在数据库本身定义:
def to_node(self, edge):
return self.node(edge['_to'])
def outcome(self, pk: int, type_=None):
return [self.to_node(x) for x in self.edges()
if Dagoba.is_edge(x, '_from', pk, type_)]
以上使用了内部定义的一些辅助查询方法。用类似的逻辑再定义 income(),它们的实现都很简单,读者可以直接参考源码,此处不再赘述。
在此步骤的最后,我们再实现一个优化。当多次调用查询方法后,结果可能会返回重复的数据,很多时候这是不必要的。就像关系数据库通常支持 unique/distinct 一样,我们也希望 Dagoba 能够过滤重复的数据。
假设我们要查询某人所有孩子的祖父,显然不管有多少孩子,他们的祖父应该是同一个人。因此编写测试如下:
def test_grandfater_unique(self):
nodes = self.q.node(3).outcome().income('son').income('son').unique().run()
self.assertEqual(1, len(nodes))
self.assertEqual(1, Dagoba.pk(nodes[0]))
现在来实现 unique()。我们只要按照主键把重复数据去掉即可:
def unique(self):
d = {}
for node in self._result:
pk = Dagoba.pk(node)
d.setdefault(pk, node)
self._result = list(d.values())
return self
步骤3:添加双向关联支持
在上个步骤,初始化数据库指定了双向关联,但并未测试它们。因为我们还没有编写代码去支持它们,现在增加一个测试,它应该是失败的:
def test_toms_sisters_brother(self):
nodes =self.q.node(3).outcome('sister').outcome('brother').run()
self.assert_nodes(nodes, [3, 4, 5])
运行测试,的确失败了。我们看看要如何支持它。回想一下,当从边查找节点时,使用的是以下方法:
def outcome(self, pk: int, type_=None):
return [self.to_node(x) for x in self.edges()
if Dagoba.is_edge(x, '_from', pk, type_)]
这里也有一个潜在的问题:调用 self.edges() 意味着遍历所有边,当数据库内容较多时,这是巨大的浪费。为了提高性能,我们可以把与节点相关的边记录在节点本身,这样要查找边只要看节点本身即可。在初始化时定义出入边的集合:
def add_node(self, node):
...
node['_out'] = []
node['_in'] = []
self._nodes.append(node)
self._nodes_by_id[pk] = node
return pk
在添加边时,我们要同时把它们对应的关系同时更新到节点,此外还要维护反向关联。这涉及对字典内容的部分复制,先编写一个辅助方法:
def copy_dict(src: dict, *excludes) -> dict:
return {k: v for k, v in src.items() if k not in excludes}
然后,将添加边的实现修改如下:
def add_edge(self, edge):
from_id = edge.get('_from', None)
to_id = edge.get('_to', None)
try:
from_node = self.node(from_id)
to_node = self.node(to_id)
forward = copy_dict(edge, '_backward')
self._edges.append(forward)
from_node['_out'].append(forward)
to_node['_in'].append(forward)
if '_backward' in edge.keys():
backward = copy_dict(edge, '_backward')
backward['_type'] = edge['_backward']
backward['_from'] = edge['_to']
backward['_to'] = edge['_from']
self._edges.append(backward)
from_node['_in'].append(backward)
to_node['_out'].append(backward)
except KeyError:
raise ValueError(f'Invalid edge: node(_id={from_id}/{to_id}) not exists.')
这里的代码同时添加正向关联和反向关联。有的朋友可能会注意到代码略有重复,是的,但是重复仅出现在该函数内部,本着“三则重构”的原则,暂时不去提取代码。
实现之后,前面的测试就可以正常通过了。
步骤4:实现延迟查询
在这个步骤中,我们来实现延迟查询(Lazy Query)。
延迟查询的要求是,当调用查询方法时并不立即执行,而是推迟到调用特定方法,比如 run() 时才执行整个查询,返回结果。
延迟查询的实现要比主动查询复杂一些。为了实现延迟查询,查询方法的实现不能直接返回结果,而是记录要执行的动作以及传入的参数,到调用 run() 时再依次执行前面记录下来的内容。如果你去看作者的实现,会发现他是用一个数据结构记录执行操作和参数,此外还有一部分逻辑用来分派对每种结构要执行的动作。这样当然是可行的,但数据处理和分派部分的实现会比较复杂,也容易出错。本文的实现则选择了另外一种不同的方法:使用 Python 的内部函数机制,把一连串查询变换成一组函数,每个函数取上个函数的执行结果作为输入,最后一个函数的输出就是整个查询的结果。由于内部函数同时也是闭包,尽管每个查询的参数形式各不相同,但是它们都可以被闭包“捕获”而成为内部变量,所以这些内部函数可以采用统一的形式,无需再针对每种查询设计额外的数据结构,因而执行过程得到了很大程度的简化。
首先还是来编写测试。LazyQueryTest 和 EagerQueryTest 测试用例几乎是完全相同的(是的,两种查询只在于内部实现机制不同,它们的调用接口几乎是完全一致的)。因此我们可以把 EagerQueryTest 的测试原样不变拷贝到 LazyQueryTest 中。当然拷贝粘贴不是个好注意,对于比较冗长而固定的初始化部分,我们可以把它提取出来作为两个测试共享的公共函数。读者可参考代码中的 step04_lazy_query/tests/test_lazy_query.py 部分。
程序把查询函数的串行执行称为管道(pipeline),用一个变量来记录它:
class LazyQuery:
def __init__(self, db):
self._db = db
self._pipeline = []
然后依次实现各个调用接口。每种接口的实现都是类似的:用内部函数执行真正的查询逻辑,再把这个函数添加到 pipeline 调用链中。比如 node() 的实现类似下面:
def node(self, pk: int):
def func(arg):
try:
result = self._db.node(pk)
return [result]
except KeyError:
return []
self._pipeline.append(func)
return self
其他接口的实现也与此类似。最后,run() 函数负责执行所有查询,返回最终结果;
def run(self):
input_, output_ = None, None
for step in self._pipeline:
output_ = step(input_)
input_ = output_
return list(output_)
完成上述实现后执行测试,确保我们的实现是正确的。
步骤5:测试访问效率
在前面我们说过,延迟查询与主动查询相比,最大的优势是对于许多查询可以按需要访问,不需要每个步骤都返回完整结果,从而提高性能,节约查询时间。比如说,对于下面的查询:
q.node(1).outcome('son').outcome('son').take(1)
以上查询的意思是从孙辈中找到一个符合条件的节点即可。对该查询而言,主动查询会在调用 outcome('son') 时就遍历所有节点,哪怕最后一步只需要第一个结果。而延迟查询为了提高效率,应在找到符合条件的结果后立即停止。
目前我们尚未实现 take() 方法。老规矩,先添加测试:
def test_take(self):
nodes = self.q.node(1).outcome('son').outcome('son').take(1).run()
pk = Dagoba.pk(nodes[0])
self.assertIn(pk, [3, 4, 5])
主动查询的 take() 实现比较简单,我们只要从结果中返回前 n 条记录:
def take(self, count: int):
self._result = self._result[:count]
return self
延迟查询的实现要复杂一些。为了避免不必要的查找,返回结果不应该是完整的列表(list),而应该是个按需返回的可迭代对象,我们用内置函数 next() 来依次返回前 n 个结果:
def take(self, count: int):
def func(arg):
return [next(arg) for i in range(count)]
self._pipeline.append(func)
return self
写完后运行测试,确保它们是正确的。
从外部接口看,主动查询和延迟查询几乎是完全相同的,所以用单纯的数据测试很难确认后者的效率一定比前者高,用访问时间来测试也并不可靠。为了测试效率,我们引入一个节点访问次数的概念,如果延迟查询效率更高的话,那么它应该比主动查询访问节点的次数更少。
为此,编写如下测试:
def test_node_visits(self):
self.db.reset_visits()
eager_query = self.db.query(eager=True)
eager_query.node(1).outcome('son').outcome('son').take(1).run()
eager_visits = self.db.node_visits()
self.db.reset_visits()
lazy_query = self.db.query(eager=False)
lazy_query.node(1).outcome('son').outcome('son').take(1).run()
lazy_visits = self.db.node_visits()
self.assertTrue(lazy_visits < eager_visits)
我们为 Dagoba 类添加一个成员来记录总的节点访问次数,以及两个辅助方法,分别用于获取和重置访问次数:
class Dagoba:
def __init__(self, nodes=None, edges=None):
...
self._node_visits = 0
def node_visits(self) -> int:
return self._node_visits
def reset_visits(self):
self._node_visits = 0
然后,在访问节点时增加计数。需要注意的是,我们关注的是查询效率,初始化时也需要访问节点,但此时没有必要关注访问数量。因此我们有条件地增加访问计数:
def node(self, pk: int, visit=False):
if visit:
self._node_visits += 1
return self._nodes_by_id[pk]
然后浏览代码,查找修改点。增加计数主要在从边查找节点的时候,因此修改部分如下:
def from_node(self, edge):
return self.node(edge['_from'], visit=True)
def to_node(self, edge):
return self.node(edge['_to'], visit=True)
此外还有 income/outcome 方法,修改都很简单,这里就不再列出。
实现后再次运行测试。测试通过,表明延迟查询确实在效率上优于主动查询。
步骤6:自定义查询方法
以上步骤中,我们实现了图数据库的存储结构以及查询方法。最后这个步骤主要关注有关接口和扩展性的问题。
不像关系数据库的结构那样固定,图的形式可以千变万化,查询机制也必须足够灵活。从原理上讲,所有查询无非是从某个节点出发按照特定方向搜索,因此用 node/income/outcome 这三个方法几乎可以组合出任意所需的查询。但对于复杂查询,写出的代码有时会显得较为琐碎和冗长,对于特定领域来说,往往存在更为简洁的名称,例如:母亲的兄弟可简称为舅舅。对于这些场景,如果能够类似 DSL(领域特定语言)那样允许用户根据专业要求自行扩展,从而简化查询,方便阅读,无疑会更为友好。
如果读者去看原作者的实现,会发现他是用一种特殊语法 addAlias 来定义自己想要的查询,调用方法时再进行查询以确定要执行的内容,其接口和内部实现都是相当复杂的。而我希望有更简单的方法来实现这一点。所幸 Python 是一种高度动态的语言,允许在运行时向类中增加新的成员,因此做到这一点可能比预想的还要简单。
为了验证这一点,编写测试如下:
def test_custom_pipeline_grandkids(self):
def grandkids(self_):
self_.outcome().outcome()
return self_
LazyQuery.grandkids = grandkids
nodes = self.q.node(1).grandkids().run()
self.assert_nodes(nodes, [3, 4, 5, 6])
无需 Dagoba 的实现做任何改动,测试就可以通过了!其实我们要做的就是动态添加一个自定义的成员函数,按照 Python 对象机制的要求,成员函数的第一个成员应该是名为 self 的参数,但这里已经是在 UnitTest 的内部,为了和测试类本身的 self 相区分,新函数的参数增加了一个下划线。此外,函数应返回其所属的对象,这是为了链式调用所要求的。我们看到,动态语言的灵活性使得添加新语法变得非常简单。
总结
到此,一个初具规模的图数据库就形成了。
和原文相比,本文还缺少一些内容,比如如何将数据库序列化到磁盘。不过相信读者都看到了,我们的数据库内部结构基本上是简单的原生数据结构(列表+字典),因此序列化无论用 pickle 或是 JSON 之类方法都应该是相当简单的。有兴趣的读者可以自行完成它们。
我们的图数据库实现为了提高查询性能,在节点内部存储了边的指针(或者说引用)。这样做的好处是,无论数据库有多大,从一个节点到相邻节点的访问是常数时间,因此数据访问的效率非常高。但一个潜在的问题是,如果数据库规模非常大,已经无法整个放在内存中,或者出于安全性等原因要实现分布式访问的话,那么指针就无法使用了,必须要考虑其他机制来解决这个问题。分布式数据库无论采用何种数据模型都是一个棘手的问题,在本文中我们没有涉及。有兴趣的读者也可以考虑 500lines 系列中关于分布式和集群算法的其他一些文章。
Python 作为实现语言,而原作者使用的是 JavaScript,这应该和作者的背景有关。我相信对于大多数开发者来说,Python 的对象机制比 JavaScript 基于原型的语法应该是更容易阅读和理解的。当然,原作者的版本比本文版本在实现上其实是更为完善的,灵活性也更好。如果想要更为优雅的实现,我们可以考虑使用 Python 元编程,那样会更接近于作者的实现,但也会让程序的复杂性大为增加。如果读者有兴趣,不妨对照着去读读原作者的版本。
还不过瘾?试试它们
▲Python 3.10 版本 match-case 尝鲜体验!