
深度:全面解析Lustre文件系统(下)

Lustre客户端软件为Linux虚拟文件系统和Lustre服务器之间提供了接口。客户端软件包括一个管理客户端(MGC),一个元数据客户端(MDC)和多个对象存储客户端(OSC)。每个OSC对应于文件系统中的一个OST。
逻辑对象卷(LOV)通过聚合OSC以提供对所有OST的透明访问。因此,挂载了Lustre文件系统的客户端会看到一个连贯的同步名字空间。多个客户端可以同时写入同一文件的不同部分,而其他客户端可以同时读取文件。
与LOV文件访问方式类似,逻辑元数据卷(LMV)通过聚合MDC提供一种对所有MDT透明的访问。这使得了客户端可将多个MDT上的目录树视为一个单一的连贯名字空间,并将条带化目录合并到客户端形成一个单一目录以便用户和应用程序查看。
Lustre Networking(LNet)是一种定制网络API,提供处理Lustre文件系统服务器和客户端的元数据和文件I/O数据的通信基础设施。
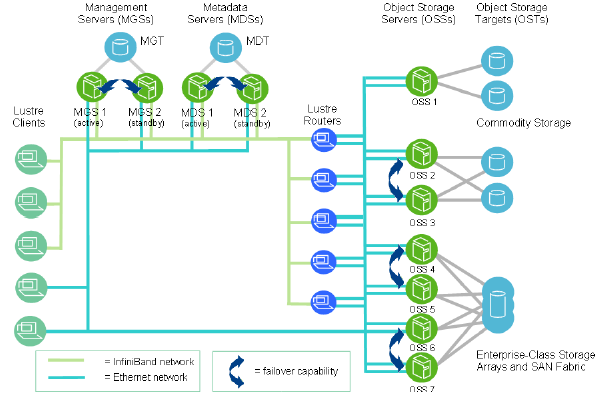
Lustr文件系统在规模上,一个Lustre文件系统集群可以包含数百个OSS和数千个客户端(如下图所示)。Lustre集群中可以使用多种类型的网络,OSS之间的共享存储启用故障切换功能。
Lustre文件系统存储与I/O,在 Lustre 2.0 中引入了Lustre文件标识符(FID)来替换用于识别文件或对象的UNIX inode编号。FID是一个128位的标识符,其中,64位用于存储唯一的序列号,32位用于存储对象标识符(OID),另外32位用于存储版本号。序列号在文件系统(OST和MDT)中的所有Lustre目标中都是唯一的。这一改变使未来支持多种 MDT 和ZFS(均在Lustre 2.4中引入)成为了可能。
同时,在此版本中也引入了一个名为FID-in-dirent(也称为Dirdata)的ldiskfs功能,FID作为文件名称的一部分存储在父目录中。该功能通过减少磁盘I/O显著提高了ls命令执行的性能。FID-in-dirent是在创建文件时生成的。
在 Lustre 2.4 中,LFSCK文件系统一致性检查工具提供了对现有文件启用FID-in-dirent的功能。具体如下:
为1.8版本文件系统上现有文件生成IGIF模式的FID。
验证每个文件的FID-in-dirent,如其无效或丢失,则重新生成FID-in-dirent。
验证每个linkEA条目,如其无效或丢失,则重新生成。linkEA由文件名和父类FID组成,它作为扩展属性存储在文件本身中。因此,linkEA可以用来重建文件的完整路径名。
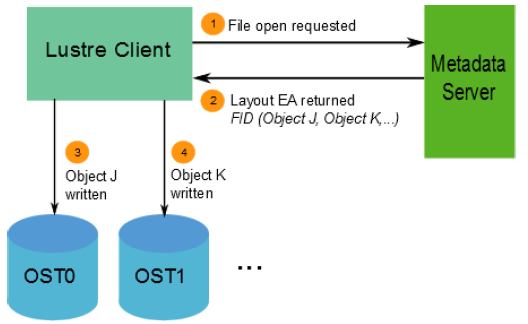
有关文件数据在OST上的位置信息将作为扩展属性布局EA,存储在由FID标识的MDT对象中(具体如下图所示)。若该文件是普通文件(即不是目录或符号链接),则MDT对象1对N地指向包含文件数据的OST对象。若该MDT文件指向一个对象,则所有文件数据都存储在该对象中。若该MDT文件指向多个对象,则使用RAID 0将文件数据划分为多个对象,将每个对象存储在不同的OST上。
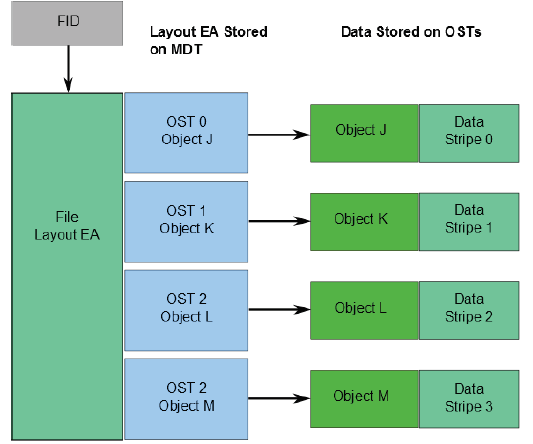
当客户端读写文件时,首先从文件的MDT对象中获取布局EA,然后使用这个信息在文件上执行I / O,直接与存储对象的OSS节点进行交互。具体过程如下图所示。
网络带宽等于OSS到目标的总带宽。
磁盘带宽等于存储目标(OST)的磁盘带宽总和,受网络带宽限制。
总带宽等于磁盘带宽和网络带宽的最小值。
可用的文件系统空间等于所有OST的可用空间总和。
Lustre文件系统高性能的主要原因之一是能够以轮询方式跨多个OST将数据条带化。用户可根据需要为每个文件配置条带数量,条带大小和OST。当单个文件的总带宽超过单个OST的带宽时,可以使用条带化来提高性能。同时,当单个OST没有足够的可用空间来容纳整个文件时,条带化也能发挥它的作用。
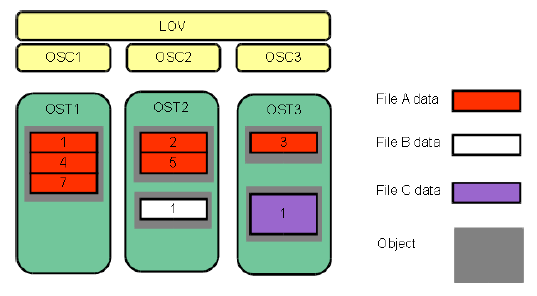
如图下图所示,条带化允许将文件中的数据段或“块”存储在不同的OST中。在Lustre文件系统中,通过RAID 0模式将数据在一定数量的对象上进行条带化。一个文件中处理的对象数称为stripe_count。每个对象包含文件中的一个数据块,当写入特定对象的数据块超过stripe_size时,文件中的下一个数据块将存储在下一个对象上。stripe_count和stripe_size的默认值由为文件系统设置的,其中,stripe_count为1,stripe_size为1MB。用户可以在每个目录或每个文件上更改这些值。
下图中,文件C的stripe_size大于文件A的stripe_size,表明更多的数据被允许存储在文件C的单个条带中。文件A的stripe_count为3,则数据在三个对象上条带化。文件B和文件C的stripe_count是1。OST上没有为未写入的数据预留空间。
最大文件大小不受单个目标大小的限制。在Lustre文件系统中,文件可以跨越多个对象(最多2000个)进行分割,每个对象可使用多达16 TB的ldiskfs,多达256PB的ZFS。也就是说,ldiskfs的最大文件大小为31.25 PB,ZFS的最大文件大小为8EB。Lustre文件系统上的文件大小受且仅受OST上可用空间的限制,Lustre最大可支持2 ^ 63字节(8EB)的文件。
注意: Lustre 2.2之前,单个文件的最大条带数为160个OST。尽管一个文件只能被分割成2000个以上的对象,但是Lustre文件系统可以有数千个。
实际上前面已经提到,Lustre并不适合小文件I/O应用,性能表现非常差。因此,建议不要将Lustre应用于LOSF场合。不过,Lustre操作手册仍然给出了一些针对小文件的优化措施。
Lustre提供了强大的系统监控与控制接口用于进行性能分析与调优,对于小文件I/O,也可以通过调整一些系统参数进行优化。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕。
获取方式:点击“阅读原文”即可查看182页 PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
