
Pandas教程
Pandas 是为了解决数据分析任务而创建的一种基于 NumPy 的工具包,囊括了许多其他工具包的功能,具有易用、直观、快速等优点。要想成为一名高效的数据科学家,不会 Pandas 怎么行?

import pandas as pd
data = pd.read_csv( my_file.csv )
data = pd.read_csv( my_file.csv , sep= ; , encoding= latin-1 , nrows=1000, skiprows=[2,5])
最常用的功能:read_csv, read_excel
其他一些很棒的功能:read_clipboard, read_sql
data.to_csv( my_new_file.csv , index=None)

Gives (#rows, #columns)
data.describe()
data.head(3)
data.loc[8]
data.loc[8, column_1 ]
data.loc[range(4,6)]
data[data[ column_1 ]== french ]
data[(data[ column_1 ]== french ) & (data[ year_born ]==1990)]
data[(data[ column_1 ]== french ) & (data[ year_born ]==1990) & ~(data[ city ]== London )]
data[data[ column_1 ].isin([ french , english ])]
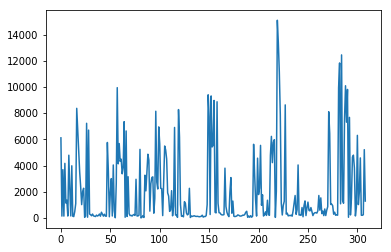
data[ column_numerical ].plot()
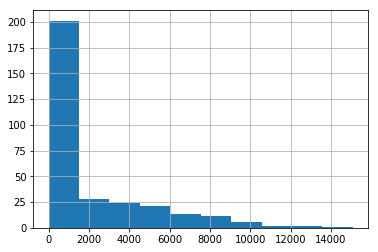
data[ column_numerical ].hist()
%matplotlib inline
data.loc[8, column_1 ] = english 将第八行名为 column_1 的列替换为「english」
data.loc[data[ column_1 ]== french , column_1 ] = French
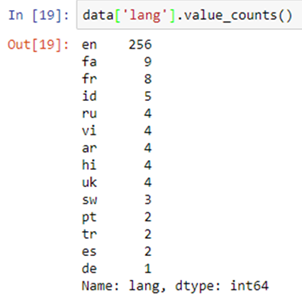
data[ column_1 ].value_counts()
data[ column_1 ].map(len)
data[ column_1 ].map(len).map(lambda x: x/100).plot()
data.apply(sum)
from tqdm import tqdm_notebook
tqdm_notebook().pandas()
data[ column_1 ].progress_map(lambda x: x.count( e ))

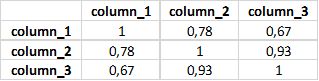
data.corr()
data.corr().applymap(lambda x: int(x*100)/100)
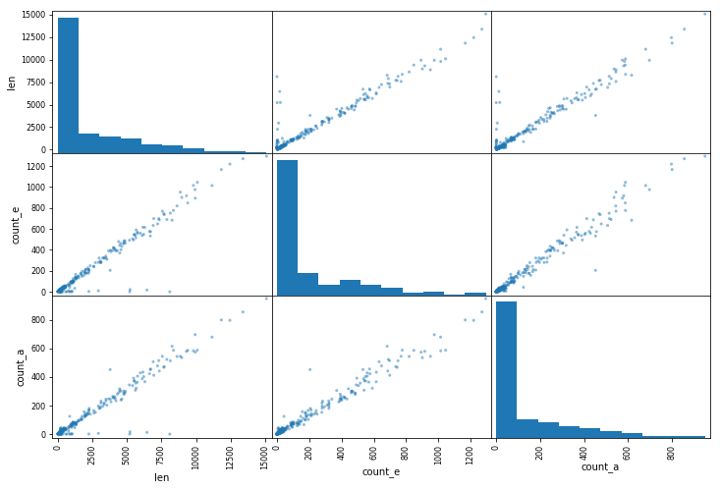
pd.plotting.scatter_matrix(data, figsize=(12,8))
data.merge(other_data, on=[ column_1 , column_2 , column_3 ])
data.groupby( column_1 )[ column_2 ].apply(sum).reset_index()

dictionary = {}
for i,row in data.iterrows():
dictionary[row[ column_1 ]] = row[ column_2 ]
易用,将所有复杂、抽象的计算都隐藏在背后了;
直观;
快速,即使不是最快的也是非常快的。

看完本文有收获?请转发分享给更多人
你想成为数据人才吗?你要找数据工作吗?
关注「数据人才」,找满意数据工作
我们创建了Python语言交流群,
请扫码下方二维码
备注:姓名-Python,邀请你加入群
评论