
Python抓取了2500多份数据类招聘需求,看看什么岗位才是“真香”
大家好,欢迎来到 Crossin的编程教室 !
随着各行各业都在进行数字化转型,数据方面的人才也成为了各家企业招聘的重点对象,不同数据类型的岗位提供的薪资待遇又是如何的?哪个城市最需要数据方面的人才、未来的发展前景与钱途又是怎么样的?今天我们抓取了某互联网招聘平台上面的招聘信息,来为大家分析分析。
本文主要内容:
数据抓取的流程与步骤 数据清洗的流程与步骤 可视化的结果与分析
数据抓取的步骤
Python当中的requests模块来发送与接收请求,然后用BeautifulSoup模块也解析返回的数据,代码如下@retry(stop=stop_after_attempt(7))
def make_requests(url):
response = requests.get(url=url, headers=headers)
response_1 = BeautifulSoup(response.text, "lxml")
return response_1
解析数据的代码如下
def process_data(index, job_title, response_text):
response_2 = response_text.select("div.list__YibNq")
for resp in response_2[0]:
if resp.select("div.p-top__1F7CL a"):
job_titles = resp.select("div.p-top__1F7CL a")[0].get_text()
else:
job_titles = ""
if resp.select("span.money__3Lkgq"):
payments = resp.select("span.money__3Lkgq")[0].get_text()
else:
payments = ""
.........
然后最后将收集到的数据导出到excel当中,代码如下
df = pd.DataFrame(
{"职位名称": job_titles_list, "薪资待遇": payments_list, "工作年限": work_years_list, "公司名称": company_name_list,
"所处行业": industry_list, "岗位简介": job_title_description_list})
path = "job_files/"
if not os.path.exists(path):
os.makedirs(path)
df.to_excel("./job_files/{}_{}.xlsx".format(job_title, index), index = False)
数据的清洗与处理
我们用到的是Pandas模块,首先先导入所有收集到的数据
import pandas as pd
import os
df_all = pd.DataFrame(columns=["职位名称", "薪资待遇", "工作年限", "公司名称", "所处行业", "岗位简介"])
for file in os.listdir("./job_files"):
df = pd.read_excel("./job_files/" + file)
df_all = df_all.append(df, ignore_index=True)
我们来看一下最终的数据集长什么样子
print(df_all.info())
output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2238 entries, 0 to 2237
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 职位名称 2238 non-null object
1 薪资待遇 2238 non-null object
2 工作年限 2238 non-null object
3 公司名称 2238 non-null object
4 所处行业 2234 non-null object
5 岗位简介 2238 non-null object
dtypes: object(6)
memory usage: 105.0+ KB
删除重复项
drop_duplicates()方法来进行重复项的去除df_all_1 = df_all.drop_duplicates()
df_all_1.info()
output
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2207 entries, 0 to 2237
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 职位名称 2207 non-null object
1 薪资待遇 2207 non-null object
2 工作年限 2207 non-null object
3 公司名称 2207 non-null object
4 所处行业 2203 non-null object
5 岗位简介 2207 non-null object
dtypes: object(6)
memory usage: 120.7+ KB
删除缺失值
df_all_1 = df_all_1.dropna(axis = 0, how = "any")
df_all_1.info()
output
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2203 entries, 0 to 2237
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 职位名称 2203 non-null object
1 薪资待遇 2203 non-null object
2 工作年限 2203 non-null object
3 公司名称 2203 non-null object
4 所处行业 2203 non-null object
5 岗位简介 2203 non-null object
dtypes: object(6)
memory usage: 120.5+ KB
对薪资数据的清洗
接下来为了方便对薪资数据进行统计分析,我们对此也需要进行相对应的处理
df_all_1["薪资待遇"] = df_all_1["薪资待遇"].str.replace("k", "000")
可视化分析结果
薪资的不同
df_all_1[df_all_1["职位名称"].str.contains("产品经理")]['薪资待遇'].value_counts().head(5)
output
20000-40000 66
15000-30000 48
15000-25000 46
20000-30000 27
25000-50000 26
Name: 薪资待遇, dtype: int64
较多的是集中在20K-40K这个范围当中,具体我们可以通过下面这个可视化的结果来看
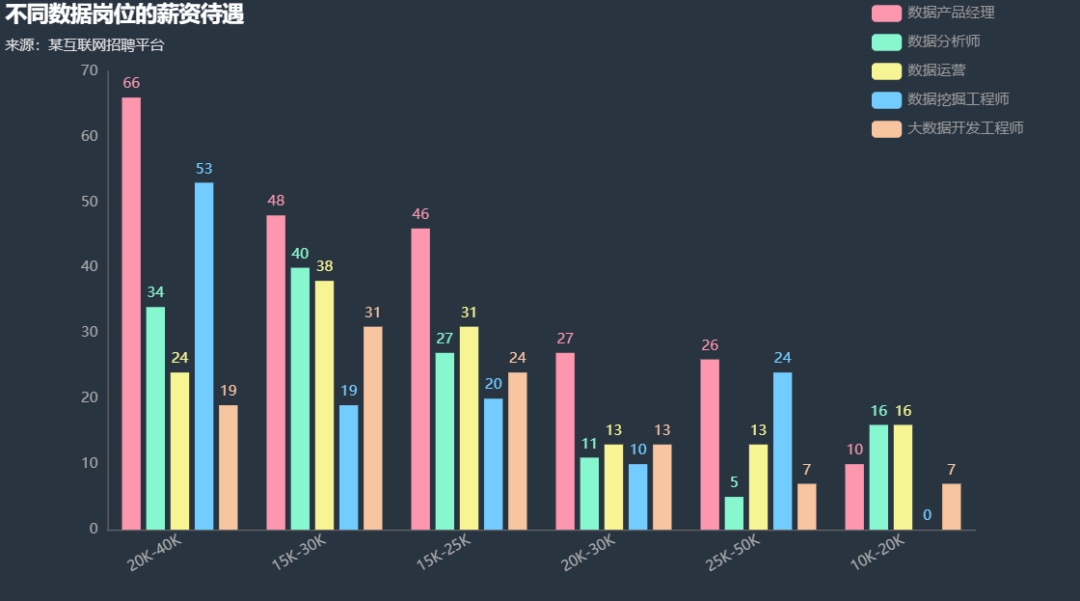
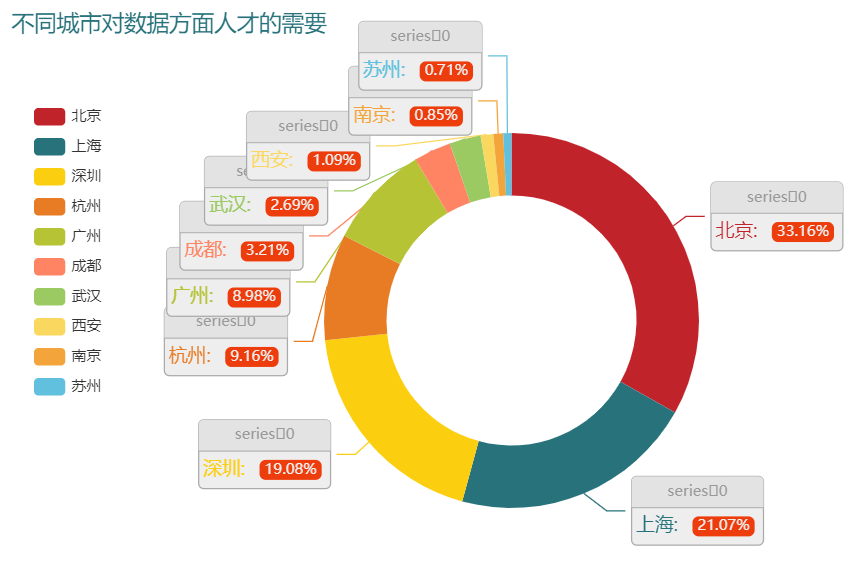
哪个城市的需求最多
接下来我们来看一下哪些城市对数据方面的人才需求是最多的,
df_all_1["城市分布"] = df_all_1["职位名称"].apply(lambda x: x.split("[")[1].split("·")[0])
df_all_1["城市分布"].value_counts().head(10)
output
北京 702
上海 446
深圳 404
杭州 194
广州 190
成都 68
武汉 57
西安 23
南京 18
苏州 15
Name: 城市分布, dtype: int64
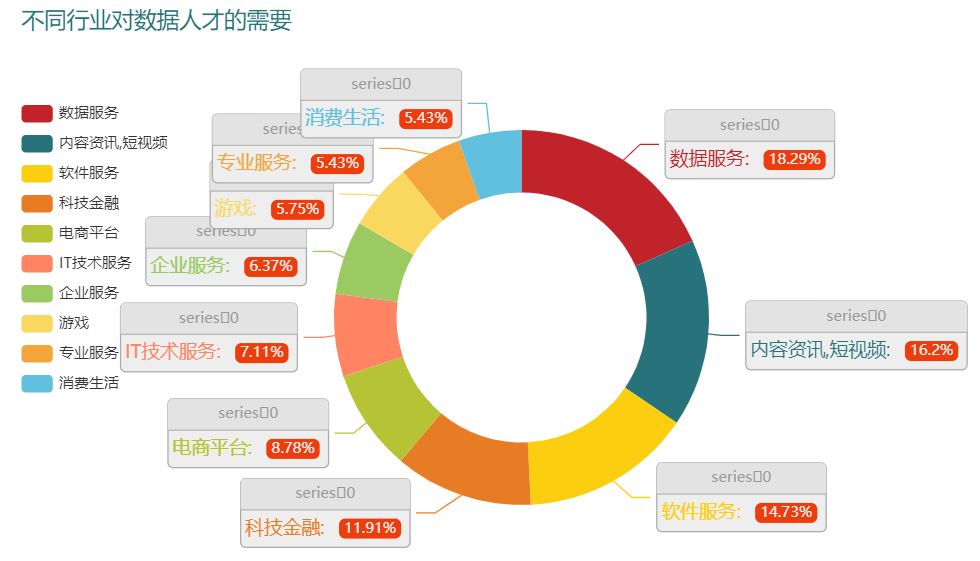
哪个行业所需要的数据岗位最多呢?
接下来我们来看一下哪个行业所需要的数据方面的人才最多,
df_all_1["行业"] = df_all_1["所处行业"].apply(lambda x: x.split("|")[0].split("/")[0])
df_all_1["行业"].value_counts().head(10)
output
数据服务 175
内容资讯,短视频 155
软件服务 141
科技金融 114
电商平台 84
IT技术服务 68
企业服务 61
游戏 55
专业服务 52
消费生活 52
Name: 行业, dtype: int64
对于学历的要求是什么样的呢?
我们来看一下各家公司对于数据方面的人才,在学历上又有何种要求呢?
df_all_1["学历要求"] = df_all_1["工作年限"].apply(lambda x: x.split("/")[-1])
df_all_1["学历要求"].value_counts()
output
本科 1922
硕士 119
不限 77
大专 73
博士 12
Name: 学历要求, dtype: int64
岗位的简短介绍
jieba模块对文本数据进行分词word_num = jieba.lcut(text, cut_all = False)
rule = re.compile(r"^[\u4e00-\u9fa5]+$")
word_num_selected = [word for word in word_num if word not in stop_words and
re.search(rule, word) and len(word) >= 2]
接着我们使用stylecloud模块来进行词云图的绘制
stylecloud.gen_stylecloud(text=" ".join(review_list), max_words=100, collocations=False,
font_path="KAITI.ttf", icon_name="fab fa-apple", size=653,
output_name="4.png")
output

以上就是我们对数据类工作岗位招聘需求的数据采集和分析。
如果文章对你有帮助,欢迎转发/点赞/收藏~
作者:俊欣
_往期文章推荐_
评论