
基于LDA和baidu-aip的舆情分析项目
概述
本文主要分为数据获取(微博爬虫)、文本分析(主题抽取、情感计算)。项目场景:以微博为数据源,分析新冠疫苗舆情的主题演化和情感波动趋势,结合时事进行验证,从而得出特殊事件对于舆情的特定影响,为突发公共事件的社交媒体舆情合理引导提供建议。
项目代码地址:关注公众号 回复 LDA
1.数据获取
包括微博正文爬虫、评论爬虫和用户信息爬虫。具体是将这三个爬取的结果当做三个相联结的关系表,首先爬取正文,而后用正文的标识符定位到每一个评论,最后用评论的标识符定位到每一个用户的个人信息。接口:
www.weibo.cn
1.博文爬虫
直接用的这个项目,非常好用。
https://github.com/dataabc/weibo-search
2.评论爬虫
输入:微博正文数据。格式如下: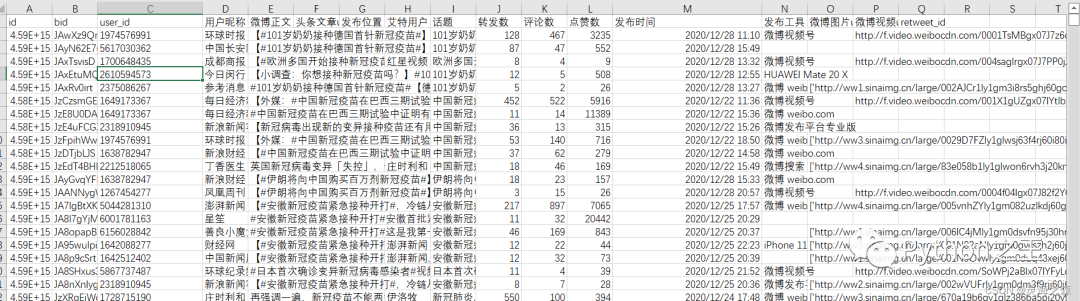 输出:各个博文的评论。格式如下:
输出:各个博文的评论。格式如下: 爬虫代码:
爬虫代码:
#coding='utf-8'
import xlrd
import re
import requests
import xlwt
import os
import time as t
import random
import numpy as np
import datetime
import urllib3
from multiprocessing.dummy import Pool as ThreadPool
urllib3.disable_warnings()
cookie=''
headers = {
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'https://www.baidu.com/',
'Connection': 'keep-alive',
'Cookie': cookie,
}
def require(url):
"""获取网页源码"""
while True:
try:
response = requests.get(url, headers=headers,timeout=(30,50),verify=False)
#print(url)
code_1=response.status_code
#print(type(code_1))
#t.sleep(random.randint(1,2))
if code_1==200:
print('正常爬取中,状态码:'+str(code_1))#状态码
t.sleep(random.randint(1,2))
break
else:
print('请求异常,重试中,状态码为:'+str(code_1))#状态码
t.sleep(random.randint(2,3))
continue
except:
t.sleep(random.randint(2,3))
continue
#print(response.encoding)#首选编码
#response.encoding=response.apparent_encoding
html=response.text#源代码文本
return html
def html_1(url):#返回网页源码和评论页数
html=require(url)
try:
page=re.findall(' 1/(.*?)页',html,re.S)
page=int(page[0])
except:
page=0
#page=re.findall('<input name="mp" type="hidden" value="(.*?)">',html,re.S)
return html,page
def count(alls):
n=0
for all in alls:
for i in all:
n=n+1
return n
def body(h_1):#主体
html_2=re.findall('<div class="c" id="C.*?">(.*?)</div>',str(h_1),re.S)
html_2=str(html_2)
user_ids=re.findall('<a href=".*?&fuid=(.*?)&.*?">举报</a> ',html_2,re.S)#从举报链接入手
names_0=re.findall('<a href=.*?>(.*?)</a>',html_2,re.S)
names=[]#用户名
ma=[ '举报', '赞[]', '回复']
pattern = re.compile(r'\d+')#匹配数字
for i in names_0:
i=re.sub(pattern, "", i)
if i not in ma:
if '@' not in i:
names.append(i)
pattern_0= re.compile(r'回复<a href=.*?</a>:')#匹配回复前缀
pattern_0_1= re.compile(r'<a href=.*?</a>')#匹配回复内容后面的表情图片地址
pattern_0_2= re.compile(r'<img alt=.*?/>')#匹配回复内容的图片地址
contents=[]#评论内容
contents_2=[]#评论内容初步
contents_0=re.findall('<span class="ctt">(.*?)</span>',html_2,re.S)#一级
contents_1=re.findall('<a href=.*?>@.*?</a>(.*?)<a href=.*?>举报</a> ',html_2,re.S)#二级
for i in contents_0:
i=re.sub(pattern_0,'',i)
i=re.sub(pattern_0_1,'',i)
i=re.sub(pattern_0_2,'',i)
i=i.replace(':','')
i=i.strip()
contents_2.append(i)
for i in contents_1:
i=re.sub(pattern_0,'',i)
i=re.sub(pattern_0_1,'',i)
i=re.sub(pattern_0_2,'',i)
i=i.replace('</span>','')
i=i.replace(' ','')
i=i.replace(':','')
i=i.strip()
contents_2.append(i)
for i in contents_2:
i=re.sub('\s','',i)#去除空白
if len(i)==0:
pass
else:
contents.append(i)
times_0=re.findall('<span class="ct">(.*?)</span>',html_2,re.S)
times=[]#时间
pattern_1= re.compile(r'\d{2}月\d{2}日')#匹配日期
for i in times_0:
try:
t_1= re.match(pattern_1, i).group()
except:
a=datetime.datetime.now().strftime('%m%d')
t_1=a[:2]+'月'+a[2:]+'日'#改为当天
times.append(t_1)
all=[]
for i in range(len(user_ids)):#这有问题
try:
al=[user_ids[i],names[i],contents[i],times[i]]
except:
j='空'
contents.append(j)
al=[user_ids[i],names[i],contents[i],times[i]]
all.append(al)
return all
def save_afile(alls,filename):
"""保存在一个excel"""
f=xlwt.Workbook()
sheet1=f.add_sheet(u'sheet1',cell_overwrite_ok=True)
sheet1.write(0,0,'用户ID')
sheet1.write(0,1,'用户名')
sheet1.write(0,2,'评论内容')
sheet1.write(0,3,'时间')
i=1
for all in alls:
for data in all:
for j in range(len(data)):
sheet1.write(i,j,data[j])
i=i+1
f.save(r'今年/'+filename+'.xls')
def extract(inpath,l):
"""取出一列数据"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0]#选定表
nrows = table.nrows#获取行号
ncols = table.ncols#获取列号
numbers=[]
for i in range(1, nrows):#第0行为表头
alldata = table.row_values(i)#循环输出excel表中每一行,即所有数据
result = alldata[l]#取出表中第一列数据
numbers.append(result)
return numbers
def run(ids):
b=ids[0]#bid
u=str(ids[1]).replace('.0','')#uid
alls=[]#每次循环就清空一次
pa=[]#空列表判定
url='https://weibo.cn/comment/'+str(b)+'?uid='+str(u)#一个微博的评论首页
html,page=html_1(url)
#print(url)
if page==0:#如果为0,即只有一页数据
#print('进入页数为0')
try:
data_1=body(html)
except:
data_1=pa
alls.append(data_1)#将首页爬取出来
#print('共计1页,共有'+str(count(alls))+'个数据')
else:#两页及以上
#print('进入两页及以上')
#print('页数为'+str(page))
for j in range(1,page+1):#从1到page
if j>=51:
break
else:
url_1=url+'&rl=1'+'&page='+str(j)
#print(url_1)
htmls,pages=html_1(url_1)
alls.append(body(htmls))
t.sleep(1)
print('共计'+str(page)+'页,共有'+str(count(alls))+'个数据')
save_afile(alls,b)
print('微博号为'+str(b)+'的评论数据文件、保存完毕')
if __name__ == '__main__':
#由于微博限制,只能爬取前五十页的
#里面的文件是爬取到的正文文件
bid=extract('..//1.微博正文爬取//正文_2.xlsx',1)#1是bid,2是u_id
uid=extract('..//1.微博正文爬取//正文_2.xlsx',2)
ids=[]#将bid和uid匹配并以嵌套列表形式加入ids
for i,j in zip(bid,uid):
ids.append([i,j])
#多线程
pool = ThreadPool()
pool.map(run, ids)
再将其进行合并,合并后结果: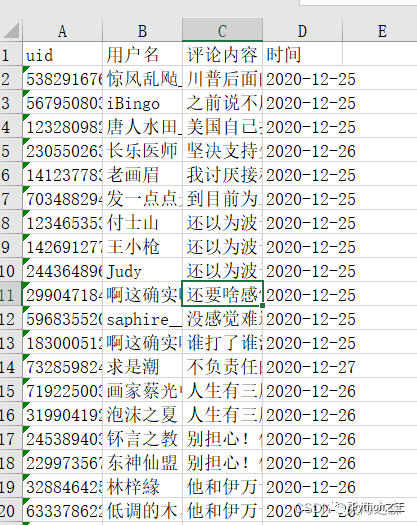 合并文件的代码如下:
合并文件的代码如下:
#coding='utf-8'
import xlrd
import re
import xlwt
import time as t
import openpyxl
import os
def extract(inpath):
"""提取数据"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0]#选定表
nrows = table.nrows#获取行号
ncols = table.ncols#获取列号
numbers=[]
for i in range(1, nrows):#第0行为表头
alldata = table.row_values(i)#循环输出excel表中每一行,即所有数据
result_0 = alldata[0]#id
result_1 = alldata[1]#bid
result_2 = alldata[2]#uid
result_3 = alldata[3]#文本
numbers.append([result_0,result_1,result_2,result_3])
return numbers
def extract_1(inpath):
"""提取数据"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0]#选定表
nrows = table.nrows#获取行号
ncols = table.ncols#获取列号
numbers=[]
for i in range(1, nrows):#第0行为表头
alldata = table.row_values(i)#循环输出excel表中每一行,即所有数据
result_0 = alldata[1]#bid
numbers.append(result_0)
return numbers
def save_file(alls,name):
"""将一个时间段的所有评论数据保存在一个excle
"""
f=openpyxl.Workbook()
sheet1=f.create_sheet('sheet1')
sheet1['A1']='uid'
sheet1['B1']='用户名'
sheet1['C1']='评论内容'
sheet1['D1']='时间'
i=2#openpyxl最小值是1,写入的是xlsx
for all in alls:#遍历每一页
for data in all:#遍历每一行
for j in range(1,len(data)+1):#取每一单元格
#sheet1.write(i,j,data[j])#写入单元格
sheet1.cell(row=i,column=j,value=data[j-1])
i=i+1#往下一行
f.save(str(name))
if __name__ == "__main__":
filenames=os.listdir(r'待合并文件夹')
new_names=[]
for i in filenames:
i=i.replace('.xlsx','')
new_names.append(i)
alls=[]
for i in new_names:
alls.append(extract(r'文件路径//'+i+'.xlsx'))
save_file(alls,'汇总.xlsx')
3.用户信息爬虫
输入:评论数据。输出:个人信息,格式如下: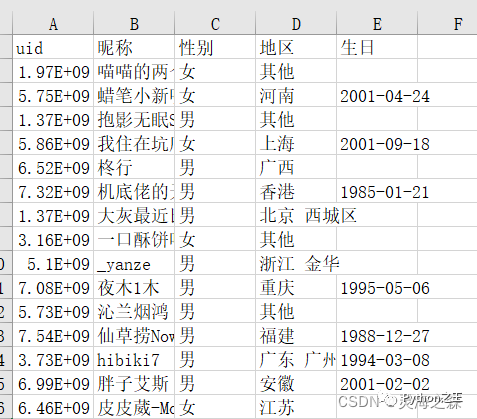 代码如下:
代码如下:
#coding='utf-8'
import xlrd
import re
import requests
import xlwt
import os
import time as t
import random
import numpy as np
import datetime
import urllib3
import sys
from multiprocessing.dummy import Pool as ThreadPool
import openpyxl
urllib3.disable_warnings()
cookie=''
headers = {
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Referer': 'https://weibo.cn/',
'Connection': 'keep-alive',
'Cookie': cookie,
}
def save_file(alls,name):
"""将数据保存在一个excel
"""
f=openpyxl.Workbook()
sheet1=f.create_sheet('sheet1')
sheet1['A1']='uid'
sheet1['B1']='昵称'
sheet1['C1']='性别'
sheet1['D1']='地区'
sheet1['E1']='生日'
i=2#openpyxl最小值是1,写入的是xlsx
for all in alls:#遍历每一页
#for data in all:#遍历每一行
for j in range(1,len(all)+1):#取每一单元格
#sheet1.write(i,j,all[j])#写入单元格
sheet1.cell(row=i,column=j,value=all[j-1])
i=i+1#往下一行
f.save(str(name))
def extract(inpath,l):
"""取出一列数据"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0]#选定表
nrows = table.nrows#获取行号
ncols = table.ncols#获取列号
numbers=[]
for i in range(1, nrows):#第0行为表头
alldata = table.row_values(i)#循环输出excel表中每一行,即所有数据
result = alldata[l]#取出表中第一列数据
numbers.append(result)
return numbers
def require(url):
"""获取网页源码"""
while True:
try:
response = requests.get(url, headers=headers,timeout=(30,50),verify=False)
#print(url)
code_1=response.status_code
#print(type(code_1))
#t.sleep(random.randint(1,2))
if code_1==200:
print('正常爬取中,状态码:'+str(code_1))#状态码
t.sleep(random.randint(1,2))
break
else:
print('请求异常,重试中,状态码为:'+str(code_1))#状态码
t.sleep(random.randint(2,3))
continue
except:
t.sleep(random.randint(2,3))
continue
#print(response.encoding)#首选编码
#response.encoding=response.apparent_encoding
html=response.text#源代码文本
return html
def body(html):
"""单个资料爬取"""
data=re.findall('<div class="tip">基本信息</div>(.*?)<div class="tip">其他信息</div>',html,re.S)#取大
#print(data)
name_0=re.findall('<div class="c">昵称:(.*?)<br/>',str(data),re.S)#用户昵称
#print(name_0)
try:
name_1=re.findall('<br/>性别:(.*?)<br/>',str(data),re.S)#性别
except:
name_1=['无']
try:
name_2=re.findall('<br/>地区:(.*?)<br/>',str(data),re.S)#地区
except:
name_2=['无']
try:
name_3=re.findall('<br/>生日:(\d{4}-\d{1,2}-\d{1,2})<br/>',str(data),re.S)#生日
except:
name_3=['无']
all=name_0+name_1+name_2+name_3
return all
def run(uid):
uid=int(uid)
alls=[]
url='https://weibo.cn/'+str(uid)+'/info'
one_data=[uid]+body(require(url))
#t.sleep(1)
alls.append(one_data)
return alls
if __name__ == '__main__':
#start_time = t.clock()
uids=list(set(extract(r'2.数据处理\评论信息.xlsx',0)))
#print(len(uids))
pool = ThreadPool()
alls_1=pool.map(run, uids)
#print(len(alls_1))
alls_2=[]
for i in alls_1:
alls_2.append(i[0])
#print(len(alls_2))
save_file(alls_2,'我.xlsx')#保存路径
#stop_time = t.clock()
#cost = stop_time - start_time
#print("%s cost %s second" % (os.path.basename(sys.argv[0]), cost))
2.文本分析
1.LDA主题分析
数据源:博文内容 文本处理:去重、剔除字数较少的博文、特殊符号清洗。主题数的确定:使用困惑度和一致性两个判断指标,设置一个区间,判断该主题数区间内容的困惑度和一致性指标的趋势,选择能使二者都取得较高水平的主题数。主题分析:将文本按月切分,分别进行分析。使用gensim库完成。输出内容:1.每个博文的主题标签 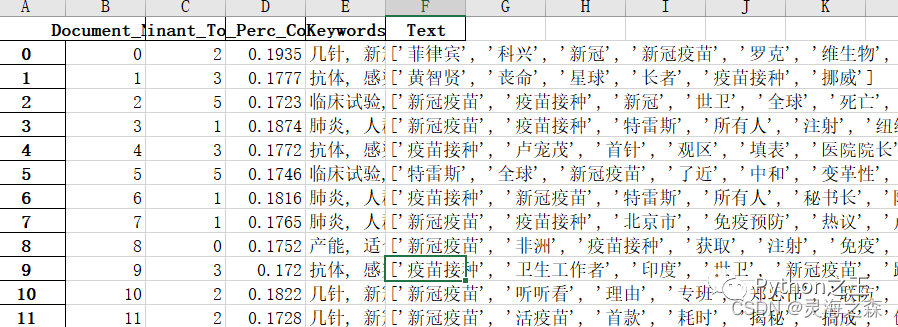 2.每个主题的关键词
2.每个主题的关键词 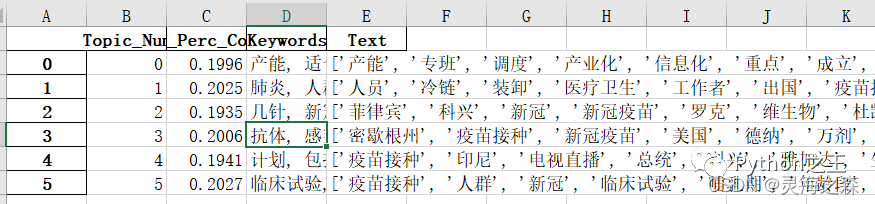 3.每个主题的关键词及占比
3.每个主题的关键词及占比  4.每个主题的博文数量
4.每个主题的博文数量 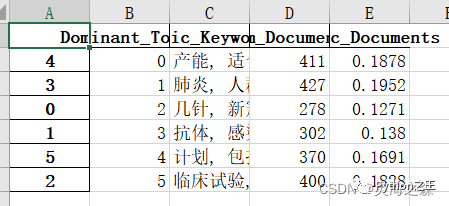 5.主题可视化
5.主题可视化 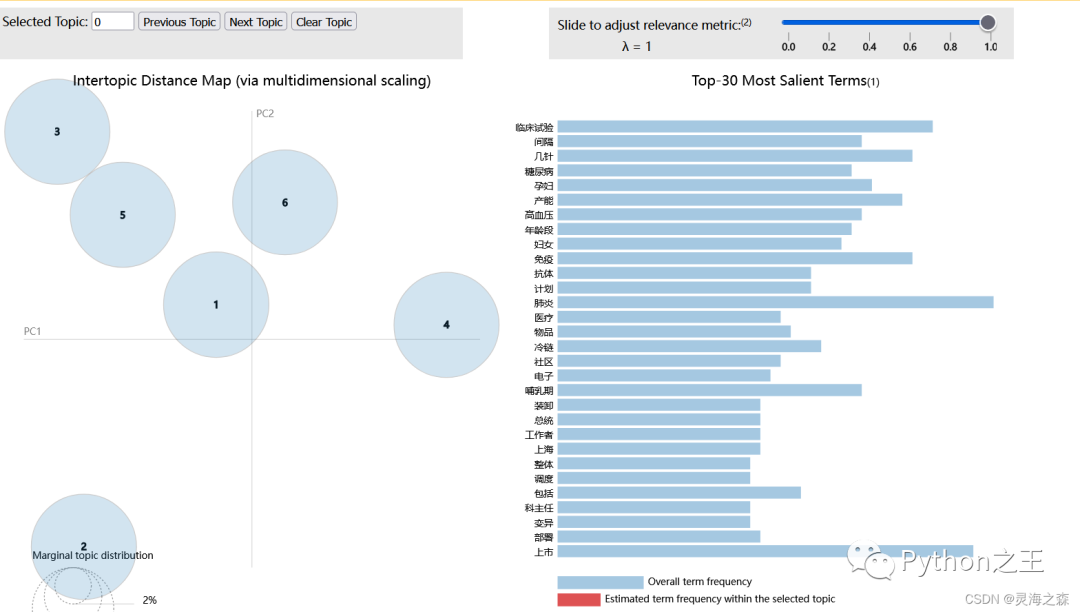 代码见github
代码见github
2.情感分析
输入:评论数据。具体使用参考。
https://blog.csdn.net/qq_43814415/article/details/115054488?spm=1001.2014.3001.5501
输出: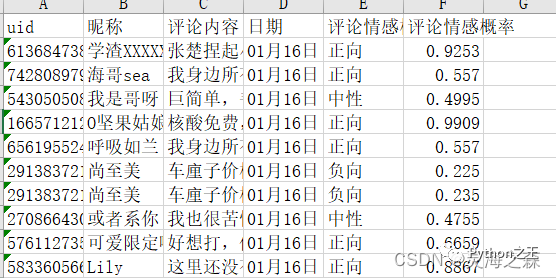 代码如下:
代码如下:
# coding=utf-8
import requests
import json
import xlrd
import re
import xlwt
import time as t
import openpyxl
"""
你的 APPID AK SK
每秒钟只能调用两次
"""
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
# client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
# 获取token
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + API_KEY + '&client_secret=' + SECRET_KEY
response = requests.get(host)
while True:
if response.status_code == 200:
info = json.loads(response.text) # 将字符串转成字典
access_token = info['access_token'] # 解析数据到access_token
break
else:
continue
access_token=access_token
def extract(inpath):
"""提取数据"""
data = xlrd.open_workbook(inpath, encoding_override='utf-8')
table = data.sheets()[0] # 选定表
nrows = table.nrows # 获取行号
ncols = table.ncols # 获取列号
numbers = []
for i in range(1, nrows): # 第0行为表头
alldata = table.row_values(i) # 循环输出excel表中每一行,即所有数据
result_0 = alldata[0] # 取出id
result_1 = alldata[1] # 取出网友名
result_2 = alldata[2] # 取出网友评论
result_3 = alldata[3] # 取出日期
numbers.append([result_0, result_1, result_2, result_3])
return numbers
def emotion(text):
while True: # 处理aps并发异常
url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify_custom?charset=UTF-8&access_token=' + access_token
#headers = {'Content-Type': 'application/json', 'Connection': 'close'} # headers=headers
body = {'text': text[:1024]}
requests.packages.urllib3.disable_warnings()
try:
res = requests.post(url=url, data=json.dumps(body), verify=False)
rc=res.status_code
print(rc)
except:
print('发生错误,停五秒重试')
t.sleep(5)
continue
if rc==200:
print('正常请求中')
else:
print('遇到错误,重试')
t.sleep(2)
continue
try:
judge = res.text
print(judge)
except:
print('错误,正在重试,错误文本为:' + text)
t.sleep(1)
continue
if judge == {'error_code': 18, 'error_msg': 'Open api qps request limit reached'}:
print('并发量限制')
t.sleep(1)
continue
elif 'error_msg' in judge: # 如果出现意外的报错,就结束本次循环
print('其他错误')
t.sleep(1)
continue
else:
break
# print(judge)
judge=eval(judge)#将字符串转换为字典
#print(type(judge))
pm = judge["items"][0]["sentiment"] # 情感分类
#print(pm)
if pm == 0:
pm = '负向'
elif pm == 1:
pm = '中性'
else:
pm = '正向'
pp = judge["items"][0]["positive_prob"] # 正向概率
pp = round(pp, 4)
#print(pp)
np = judge["items"][0]["negative_prob"] # 负向概率
np = round(np, 4)
#print(np)
return pm, pp, np
def run(inpath):
"运行程序,返回一个嵌套小列表的大列表"
alls = []
all = extract(inpath)
for i in all:
id = i[0]
name = i[1]
review = i[2] # 网友评论
# review= emotion(review)
date = i[3]
pm, pp, np = emotion(review)
alls.append([id, name, review, date, pm, pp]) # 只取正向,将所有放置在一个区间
t.sleep(1)
return alls
def save_file(alls, name):
"""将一个时间段的所有评论数据保存在一个excel
"""
f = openpyxl.Workbook()
sheet1 = f.create_sheet('sheet1')
sheet1['A1'] = 'uid'
sheet1['B1'] = '昵称'
sheet1['C1'] = '评论内容'
sheet1['D1'] = '日期'
sheet1['E1'] = '评论情感极性'
sheet1['F1'] = '评论情感概率' # [0,0.5]负向,(0.5,1]正向
i = 2 # openpyxl最小值是1,写入的是xlsx
for all in alls: # 遍历每一页
# for data in all:#遍历每一行
for j in range(1, len(all) + 1): # 取每一单元格
# sheet1.write(i,j,all[j])#写入单元格
sheet1.cell(row=i, column=j, value=all[j - 1])
i = i + 1 # 往下一行
f.save(str(name))
if __name__ == "__main__":
save_file(run( '三.xlsx'), '三情感值.xlsx')
在得到所有评论的情感值之后需要根据其时间或空间维度上卷,以得到时序情感值和地域情感值分布。时序上卷代码如下:
#coding='utf-8'
import xlrd
import xlwt
import datetime
import re
import pandas as pd
import numpy as np
data_1=pd.read_excel(r'情感.xlsx')
data = pd.DataFrame(data_1)#将excel文件读取并转换为dataframe格式
print(data)
data_df=data.groupby(by='日期').mean()#根据日期求均值
data_df.sort_index(ascending=True,inplace=True)#降序
data_df.drop(['uid'],axis=1,inplace=True)#删除id列
print(data_df)
data_df.to_excel('情感降维.xlsx')#将情感值存入excel
最终可以得到情感时序折线图: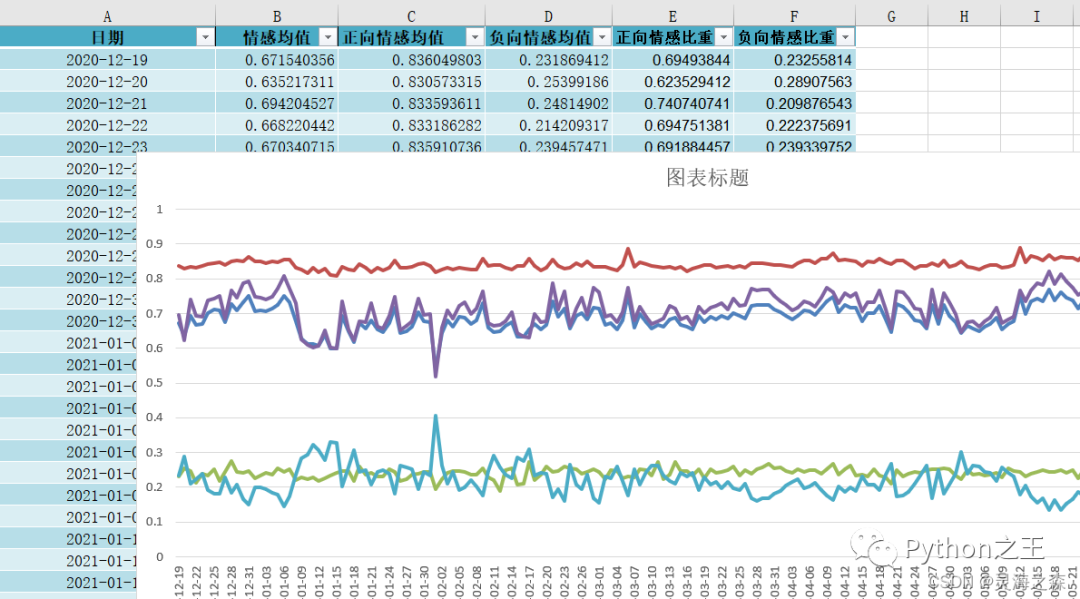
3.主题相似度计算
这里使用文本相似度计算分析出不同时间段的同一主题的演化联系。使用该篇论文中的计算公式。输出如下:
代码如下:
#coding='utf-8'
from gensim import corpora, models
from gensim.models import Word2Vec
import math
from sklearn.decomposition import PCA
import json
def work(list_1,list_2):
#计算两个词集向量的余弦相似度
#x值
xs=[]
#y值
ys=[]
for i in list_1:
xs.append(i[0])
ys.append(i[1])
for i in list_2:
xs.append(i[0])
ys.append(i[1])
#分子a,分母b,c
a=0
b=0
c=0
for x,y in zip(xs,ys):
a=a+x*y
b=b+x*x
c=c+y*y
#求值
h=a/(math.sqrt(b)*math.sqrt(c))
return h.real
def infile(fliepath):
#输入主题词文件
train = []
fp = open(fliepath,'r',encoding='utf8')
for line in fp:
line = line.strip().split(' ')
train.append(line)
return train
sentences=infile('all.txt')#读取主题特征词
model=Word2Vec.load('w2v.model')#加载训练好的模型
# 基于2d PCA拟合数据
X = model.wv.vectors
pca = PCA(n_components=2)
result = pca.fit_transform(X)
words = list(model.wv.key_to_index)
'''
for i, word in enumerate(words):
if word=='肺炎':
print(word,result[i, 0], result[i, 1])#词和词向量
for sentence in sentences:#每一个主题
print(sentence)
for sen in sentence:#每一个词
print(sen)
'''
list_1=[]#二维向量词袋形式
for sentence in sentences:#每一个主题
list_2=[]
for sen in sentence:#每一个词
for i, word in enumerate(words):
if word==sen:
#print(word,result[i, 0], result[i, 1])#词和词向量
list_2.append((result[i, 0], result[i, 1]))
list_1.append(list_2)
#print(len(list_1))
corpus=list_1
n_12=list(range(0,8))#12月的主题数
n_1=list(range(8,14))#1月的主题数
n_2=list(range(14,20))#2月的主题数
n_3=list(range(20,27))#3月的主题数
n_4=list(range(27,34))#4月的主题数
n_5=list(range(34,41))#5月的主题数
n_6=list(range(41,50))#6月的主题数
#计算相邻时间片主题的余弦相似度
hs={}
for i in n_12:#12月的主题
for j in n_1:#1月的主题
hs['12月的主题'+str(i)+str(sentences[i])+'与'+'1月的主题'+str(j-8)+str(sentences[j])+'的余弦相似度为']=work(corpus[i],corpus[j])
#print(hs)
for key,value in hs.items():#
print(key,'\t',value,'\n')
with open('12-1.json', 'w') as f:
f.write(json.dumps(hs, ensure_ascii=False, indent=4, separators=(',', ':')))
print('保存成功')


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!