
实战讲解四种不同爬虫解析数据方法,必须掌握!

1
前言
爬虫解析数据有很多种,爬取不同的数据,返回的数据类型不一样,有html、json、xml、文本(字符串)等多种格式!
掌握这四种解析数据的方式,无论什么样的数据格式都可以轻松应对处理。
这四种方式分别是:1.xpath、2.bs4、3.json、4.正则。
下面以实战方式讲解这四种技术如何使用!!!
2
Xpath
1.请求数据
请求链接如下,以小说网站:新笔趣阁,为案例进行讲解
http://www.xbiquge.la/xuanhuanxiaoshuo/
导入相应的库
import requests
from lxml import etree
开始请求数据
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36',
}
url="http://www.xbiquge.la/xuanhuanxiaoshuo/"
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
text = res.text
2.解析数据
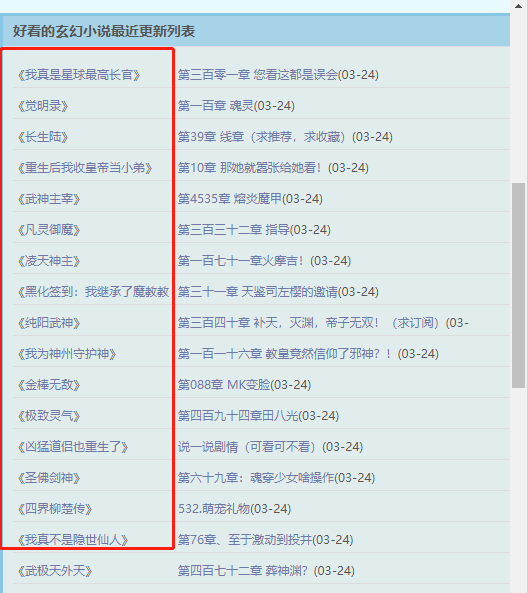
比如我们要获取下面这些数据(小说名称)
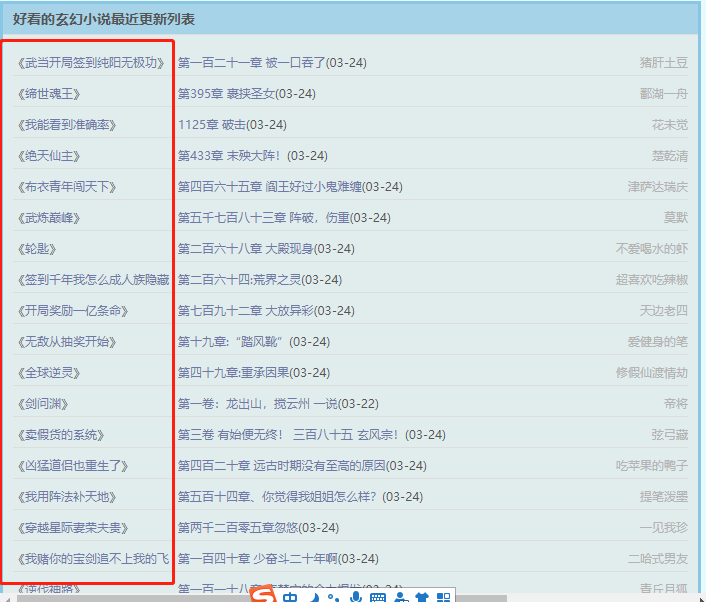
分析网页标签
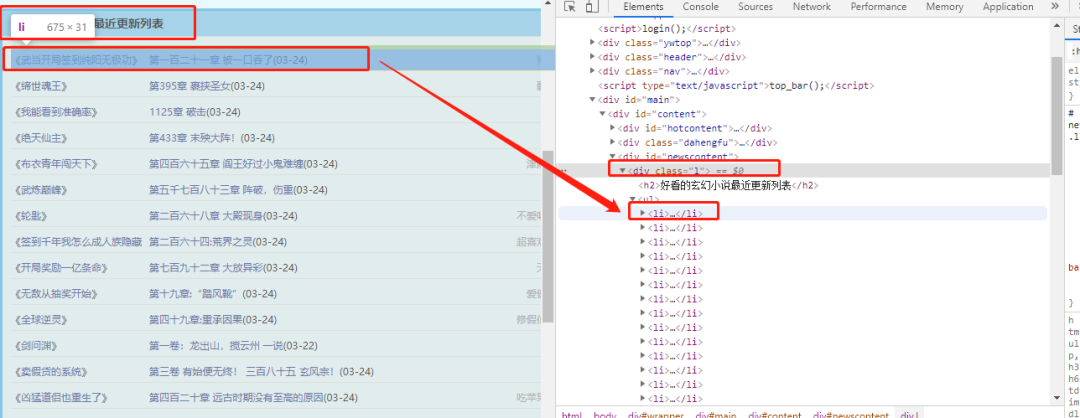
数据在class="l"-> ul ->li标签中
selector = etree.HTML(text)
list = selector.xpath('//*[@class="l"]/ul/li')
解析li中数据
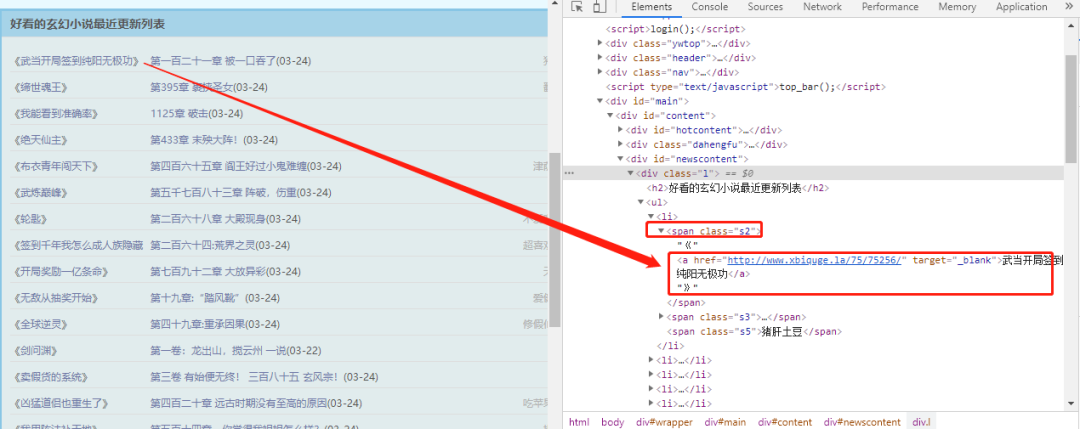
可以看到,数据在li->span->a 标签中
for i in list:
title = i.xpath('.//span/a/text()')
href = i.xpath('.//span/a/@href')
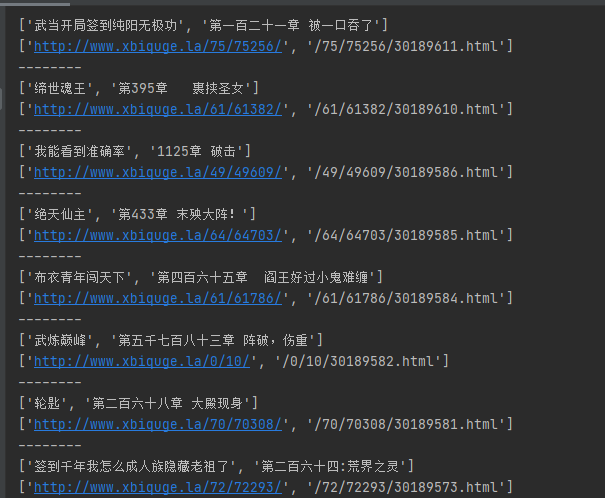
print(title)
print(href)
print("--------")
3
Bs4
1.请求数据
请求链接如下,同样以小说网站:新笔趣阁,为案例进行讲解
http://www.xbiquge.la/xuanhuanxiaoshuo/
导入相应的库
import requests
from bs4 import BeautifulSoup
开始请求数据
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36',
}
url="http://www.xbiquge.la/xuanhuanxiaoshuo/"
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
text = res.text
2.解析数据
比如我们要获取下面这些数据(小说名称)
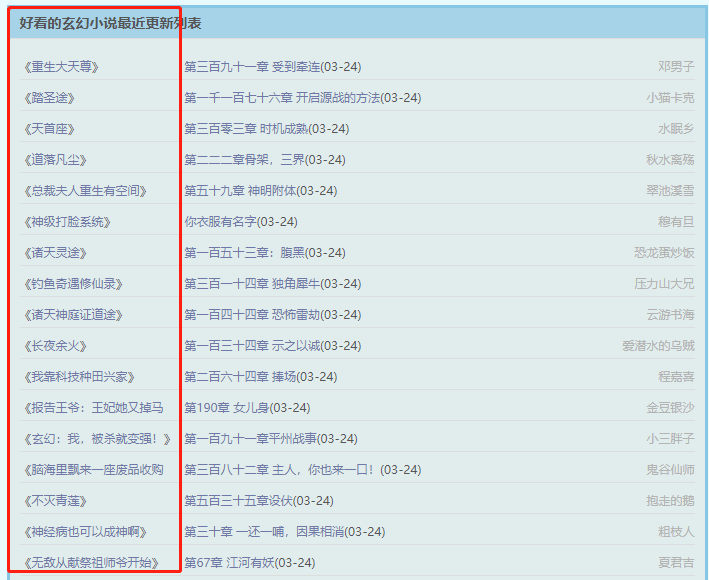
分析网页标签
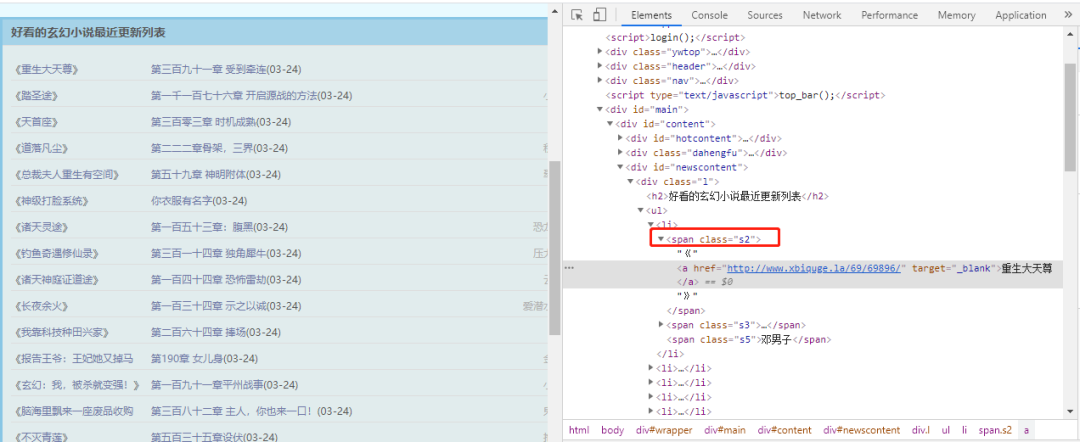
可以看到,数据在span中(class="s2") 标签中
法一
###法一
list = soup.find_all(attrs={'class':'s2'})
for i in list:
print(i.a.get_text())
print(i.a.get("href"))
print("--------")
print(len(list))
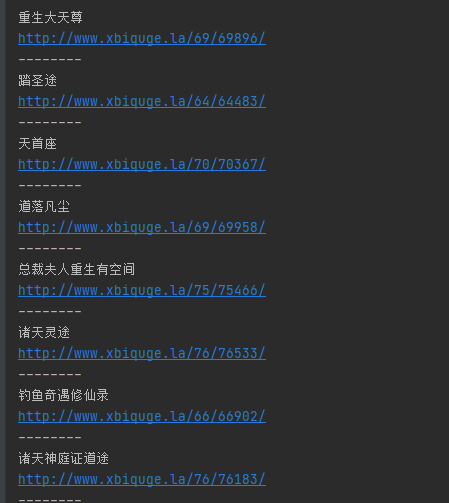
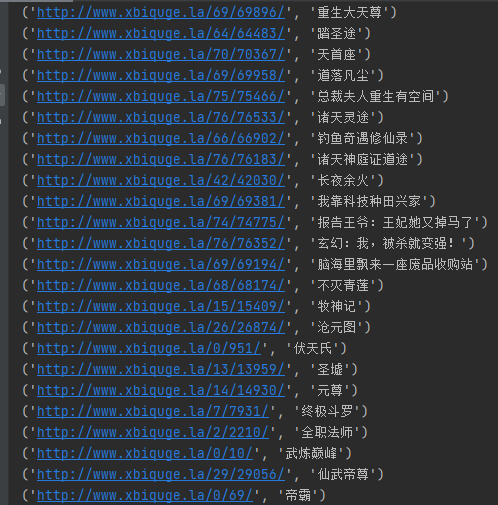
法二
####法二
# 获取所有的链接
all_link = [(link.a['href'], link.a.get_text()) for link in soup.find_all('li')]
for i in all_link:
print(i)
4
json
1.请求数据
请求链接如下,获取ip定位,为案例进行讲解
https://restapi.amap.com/v3/ip?key=0113a13c88697dcea6a445584d535837&ip=123.123.123.123
导入相应的库
import requests
import json
开始请求数据
ip = "123.123.123.123"
url="https://restapi.amap.com/v3/ip?key=0113a13c88697dcea6a445584d535837&ip="+str(ip)
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
text = res.text

2.解析数据
比如我们要获取下面这些数据(省份和城市)

text = res.text
print(text)
##text不是json类型的话,则转为json类型
text = json.loads(text)
print("省份="+text['province']+",城市="+text['city'])

5
正则表达式
1.请求数据
请求链接如下,以小说网站:新笔趣阁,为案例进行讲解
http://www.xbiquge.la/xuanhuanxiaoshuo/导入相应的库
import requests
import re
开始请求数据
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36',
}
url="http://www.xbiquge.la/xuanhuanxiaoshuo/"
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
text = res.text2.解析数据
比如我们要获取下面这些数据(小说名称)
分析网页html
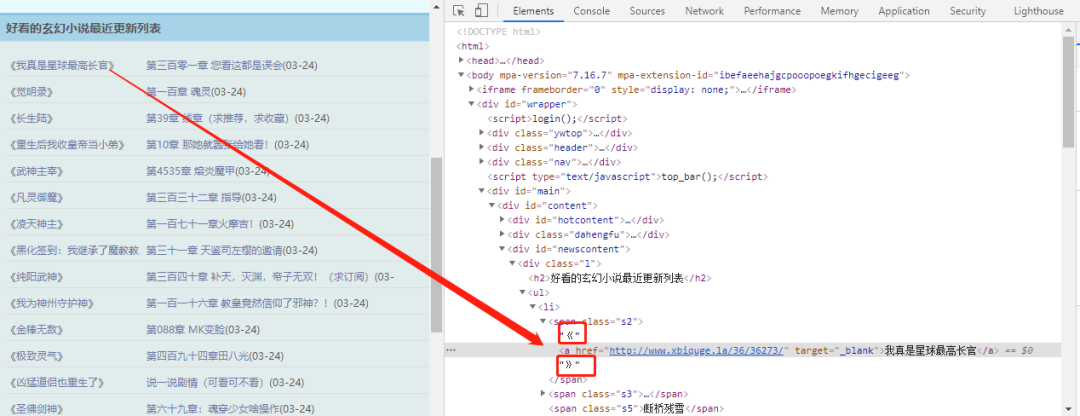
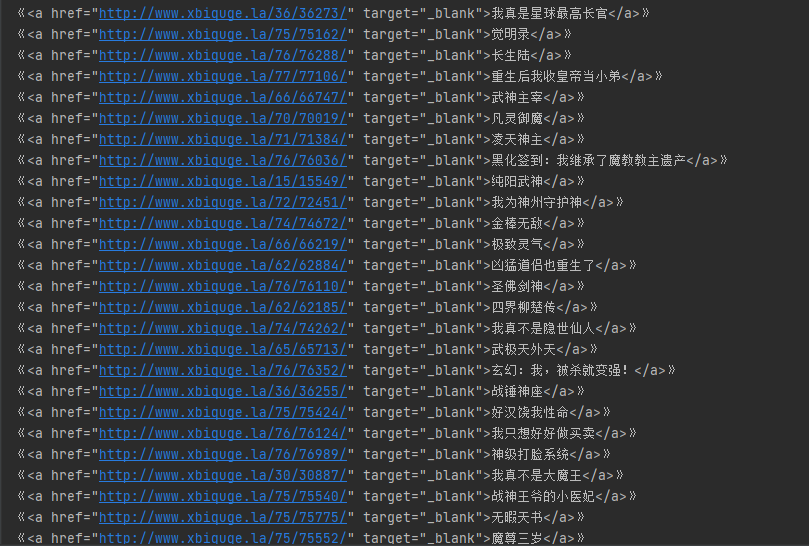
可以看到,数据在li->span->a 标签中,a标签前有“《”,后有“》”
pattern = re.compile('《.*?》')
items = re.findall(pattern, text)
for i in items:
print(i)
6
总结
1.以实战方式讲解了四种不同解析数据的方式
2.讲解过程一步一步截图说明,方便小白入门学习!
3.本文干货满满,推荐收藏!收藏!收藏!
评论