
当机器学习遇到数据量不够时,这几个Python技巧为你化解难题
有时候我们在进行模型的训练与优化的时候,是需要基于现有的数据集来操作的,要是数据量比较充足的情况下倒是还好说,但是要是遇到数据量不够的情况,该怎么办呢?今天小编就给大家来介绍几个方法来处理这种情况。
Faker模块
Python当中的Faker模块主要是用来生成伪数据,包括了城市、姓名等等,并且还支持中文,在开始使用该模块之前我们先用pip命令来下载安装完成
pip install faker
我们先随机地生成一些中文数据,代码如下
from faker import Faker
fake = Faker(locale='zh_CN')
## 随机生成一个城市
print(fake.city())
## 随机生成一个地址
print(fake.address())
output
柳州市
吉林省兴安盟县华龙任街P座 540041
要是我们想要生成其他语言或者地区表示的数据,只需要传入相对应的地区值,这里例举几个常用的,代码如下
fr_FR - French
es_ES - Spanish (Spain)
en_US - English (United States)
de_DE - German
ja_JP - Japanese
ko_KR - Korean
zh_CN - Chinese (China Mainland)
zh_TW - Chinese (China Taiwan)
我们可以看到填入的值的模式基本上是语种的缩写加上“_”再加上地区的缩写。
除了可以随机生成例如城市名称以及地址之外等模拟数据,还有很多其他方法可用,这些方法分为以下几类
address: 地址 person:人物类:性别、姓名等等 color: 颜色类 currency:货币 phone_number:手机号码类 等等
具体使用的方法大家可以参考其官网,链接是:faker.readthedocs.io/en/master/providers.html
SDV
另外我们也可以通过机器学习算法在基于真实数据的基础上生成合成数据,将后者应用于模型的训练上,例如由MIT的DAI(Data to AI)实验室推出的合成数据开源系统----Synthetic Data Vault(SDV),该模块可以从真实数据库中构建一个机器学习模型来捕获多个变量之间的相关性,要是原始的数据库中存在着一些缺失值和一些极值,最后在合成的数据集当中也会有一些缺失值与极值。
而测试表明,合成的数据能够较好地取代真实数据。接下来我们来看一下如何使用吧,首先我们先下载该模块
pip install sdv
我们会用到如下的数据集,
import pandas as pd
data = pd.read_csv('data.csv')
data.head()
output
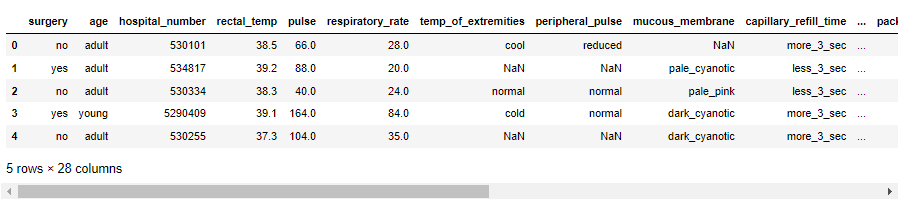
接下来的步骤和我们使用sklearn模块时的步骤是类似的,代码如下
from sdv.tabular import GaussianCopula
model = GaussianCopula()
model.fit(data)
无非就是实例化具体的模型,然后将算法模型拟合到数据集中的数据,我们可以尝试生成一些数据
sample = model.sample(200)
sample.head()
output
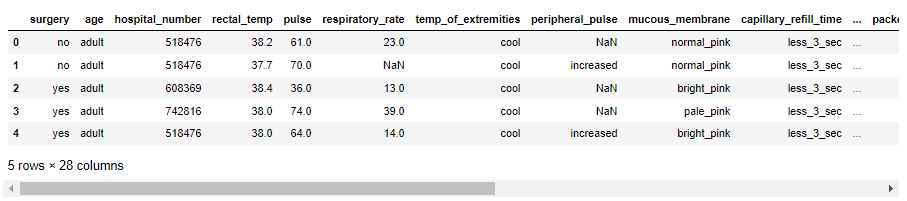
最后我们想要来评估一下模型的性能,看一下新生成的数据和真实数据相比相似性几何,代码如下
from sdv.evaluation import evaluate
print(evaluate(sample, data))
output
0.533
相似性的指标范围是“0-1”,“0”意味着是最差的结果,而“1”意味着是最理想的结果,而针对以上评估出来的结果意味着我们后续还需要进一步的参数调优。
CTGAN
随着相关研究的进一步深入,2019年在温哥华举行的第33届神经信息处理系统会议上,另外的研究员提出了新的神经网络Conditional Tabular Generative Adversarial Networks,简称CTGAN,简而言之就是通过生成对抗网络GAN来建立和完善合成的数据表。
对于生成对抗的神经网络GANs而言,其中第一个网络为生成器,而第二个网络为鉴别器,最后生成器产生出来的数据表并没有被鉴别器分辨出其中的差异。接下来我们来看一下其中的步骤。
import pandas as pd
## 这边用到了和前面不一样的数据集
data = pd.read_csv('train.csv')
data.head()
output
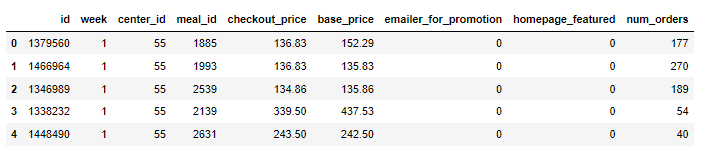
针对离散型的特征变量,CTGAN模型也可以合成类似的数据,代码如下
discrete_columns = ['week',
'Center_id',
'Meal_id',
'Emailer_for_promotion',
'homepage_featured']
ctgan = CTGANSynthesizer(batch_size=50,epochs=5,verbose=False)
ctgan.fit(data,discrete_columns)
## 将训练好的模型保存下来
ctgan.save('ctgan-food-demand.pkl')
## 生成200条数据集
samples = ctgan.sample(200)
samples.head()
output
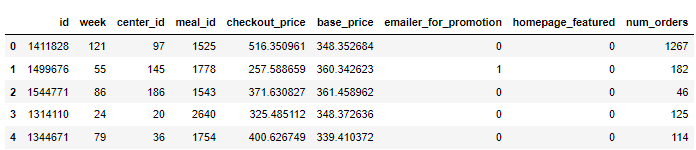
我们罗列出需要最后合成来依照的特征变量,上面的例子当中是罗列出了一系列的离散型特征变量,然后我们设定好batch_size、epochs以及verbose参数进行训练,最后我们还是通过相类似的方法来评估模型的性能
from sdv.evaluation import evaluate
evaluate(new_data, data)
总结
本文主要是立足于在机器学习的过程中存在数据量不足的情况,介绍了Faker模块和SDV模块,以及CTGAN模型,通过机器学习和深度学习等手段来生成一些数据供数据科学家使用。因为这些模型也是近年来刚出来属于较为前沿的内容,小编在对其进行表述的时候存在理解有偏差的情况,这里也是建议读者多去上网进行查阅。
我们的文章到此就结束啦~记得点赞
如何找到我: