
实现一个多人协作在线文档有哪些技术难点?
共 7639字,需浏览 16分钟
·
2022-02-09 17:28
摘抄一个google到的文章:原文连接
实时协同编辑的实现 - FEX浅谈协同编辑的实现:
什么是实时协同编辑
这里所说的实时协同编辑,是指多人同时编辑一个文档,最典型的例子是 Google Docs,你可以实时看到别人做出的修改,不用手动刷新页面。
要实现实时编辑,我们需要解决两个技术点:实时通信问题、编辑冲突问题,其中实时通信问题比较好解决,可以使用 long pull 或 WebSocket,所以这里就不过多讨论了,重点将放在如何解决编辑冲突问题上。
可选方案
接下来将从易至难的顺序来介绍几种可行的方案,分别是:「编辑锁」、「GNU diff-patch」、「Myer’s diff-patch」、「Operational Transformation」和「分布式 Operational Transformation」。
编辑锁
编辑锁这是实现协同编辑最简单的方法,简单来说就是当有人在编辑某个文档时,系统会将这个文档锁定,避免其他人同时编辑,因为实现简单,所以这个方案是应用最广的,比如公司内部常用的 TWiki 系统,采用这种方式虽然可以在一定程度上避免覆盖问题,但它的使用体验不好,也做不到「实时」,所以这里就不讨论了。
GNU diff-patch
Git 等版本管理软件其实也是一种协同编辑工具,因为每个人都可以并行编辑,遇到编辑同一个文件时可以自动合并,因此我们也能使用类似的原理来实现协同编辑,具体可以有两种方法:diff-patch 和 merge。
先说 diff-patch,这里的 diff 和 patch 是指两个 unix 下的命令,diff 能输出两个文本的不同之处,然后用 patch 来更新其它文件,我们只要在 JS 中实现这两个算法,就能通过如下流程来实现协同编辑:
- 每个用户进来时都建立长连接,保存好当前文档副本
- 有人编辑时,如果停顿 5 秒(具体要根据产品策略),就将现有文档和之前的副本进行 diff,将结果传给服务端,更新副本
- 服务端更新文档,然后通过长连接将这个 diff 结果发给同时在编辑的其它用户,这些用户使用 patch 方法来更新 ta 们文档
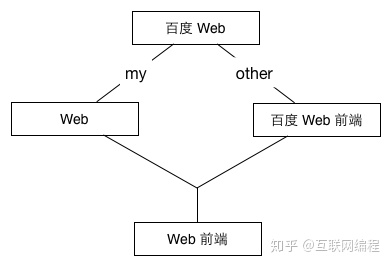
但 GNU diff 有个问题,因为基于行匹配的,所以很容易冲突,让我们测试一下「百度 Web」和「百度 Web 前端」这两段文本的 diff 结果
[nwind@fex ~]$ diff old.txt other-new.txt > old-to-other-new.patch
[nwind@fex ~]$ cat old-to-other-new.patch
1c1
< 百度 Web
---
> 百度 Web 前端在这个 diff 结果中,1c1的第一个「1」代表修改前的第一行,后面的「c」代表「修改」,第二个「1」代表修改后的行,也就是说将第一行的「百度 Web」改成「百度 Web 前端」,修改后的内容放第一行。也就意味着如果两人同时修改一行就会冲突,可以通过下面的测试来确认:
[nwind@fex ~]$ cat my-new.txt
Web
[nwind@fex ~]$ patch my-new.txt < old-to-other-new.patch
patching file b-new.txt
Hunk #1 FAILED at 1.
1 out of 1 hunk FAILED -- saving rejects to file my-new.txt.rej
[nwind@fex ~]$ cat my-new.txt.rej
***************
*** 1
- 百度 Web--- 1 -----
+ 百度 Web 前端其中 my-new.txt 是我修改的版本,我去掉了前面的「百度 」,只留下「Web」,其实这两处修改是不冲突的,它们可以合并成「Web 前端」,如下图所示

但使用 patch 命令部下,它在冲突后会生成一个新文件 my-new.txt.rej 来描述失败原因,这种展现方式不直观,需要打开两个文件比对,我们使用另一种方式来更好地展现,那就是接下来介绍的 merge 命令,它的使用方法如下:
[nwind@fex ~]$ merge my-new.txt old.txt other-new.txt
merge: warning: conflicts during merge
[nwind@fex ~]$ cat my-new.txt
<<<<<<< my-new.txt
Web=======
百度 Web 前端>>>>>>> other-new.txt可以看到它直接将冲突的地方写到 my-new.txt 里了,这点比 patch 看起来要方便些,对于这个结果估计大部分同学都会眼熟,因为 merge 命令和 Git 等工具中的合并算法是一样的。
通过使用我们可以发现 merge 命令有个缺点,那就是需要使用 3 份完整的文本来进行比较,为了避免每次传递所有文本内容,我们可以结合使用 diff 来减小传输体积,在后端 patch 成新的文本。
无论是 diff 还是 merge,由于它们的算法都是基于行进行比较,导致对同一行的编辑必然冲突,为了解决这个问题,我们可以尝试基于字符粒度的 diff 算法,那就是接下来将介绍的 Myer’s diff-patch。
Myer’s diff-patch
Myer 算法是另一种 diff-patch 算法,它有很多语言的开源实现,这里我们就不介绍细节算法了,直接用之前的例子来测试它的效果,首先看一下它的 diff 结果,调用代码如下:
var old_text = "百度 Web";
var new_text = "百度 Web 前端";
var dmp = new diff_match_patch();
var patch_list = dmp.patch_make(old_text, new_text);
patch_text = dmp.patch_toText(patch_list);
console.log(decodeURI(patch_text))输出结果为
@@ -1,6 +1,9 @@
百度 Web
+ 前端其中第一行的 - 和 + 两个符号没有什么意义,这句话表示修改处之前的起始位置为 1(由于数组是从 0 开始的,所以内部计算时会先减一),长度为 6,后面的 1,9,表示修改后的起始位置为 1,长度为 9。在接下来的两段文本代表修改的地方,注意「百度 Web」前面有空格,这代表相等,也就是直接添加这个字符串,而后面的 + 代表添加文本,具体细节可以通过它的实现源码了解。
因此确定它的 diff 策略是基于字符匹配的,这样能否解决我们之前遇到的冲突问题呢?接下来来测试一下,源码如下:
//相关代码同上
var patches = dmp.patch_fromText(patch_text);
var results = dmp.patch_apply(patches, "Web");
console.log(results[0]); //Web 前端这个输出结果是正确的,也就是说它能很好地解决之前的问题,但如果是同一个位置的修改会怎样?我继续做了几个实验:
var old_text = "百度 Web";
var other_new_text = "百度 Web 后端";
var my_new_text = "百度 Web 前端";
...
//结果为「百度 Web 前端 后端」
===
var old_text = "百度 Web 前端";
var other_new_text = "百度 Web 后端";
var my_new_text = "百度 Web 全端";
...
//结果为「百度 Web 后端」
===
var old_text = "百度 Web";
var other_new_text = "Web 前端";
var my_new_text = "百度 FE";
//结果为「FE 前」 第一个例子是在后面添加不同的字符,它的结果是两个添加都生效,第二个例子是在同一处修改成不同的字符,它的结果是别人的修改生效,但最后一个例子出错了,丢失了「端」字,这里看起来还好,但如果内容是富文本就有问题了,比如 少了 > 是不行的。
整体来看 Myer 算法可以低成本地解决大部分问题,所以有些在线编辑器选择它来实现协同编辑功能,比如 codebox,它的客户端代码在这,服务端代码在这。
不过 Myer 在某些情况下会丢字符,是否还有更好的方法?答案是有,那就是接下来介绍的 Operational Transformation 技术。
Operational Transformation
Operational Transformation(下面简称 OT)技术正是 Google Docs 中所采用的方案,因此是经过验证的,值得研究。
最开始我一直觉得 OT 会很复杂,因为它的相关介绍文章都写得很长,比如这篇及维基百科上的介绍,不过看了之后才后发现它的原理并不复杂,我将在这里进行简单的说明。
首先,我们可以将文本内容修改转成以下 3 种类型的操作(Operational):
- retain(n):保持 n 个字符,也就是说这 n 个字符不变
- insert(str):插入字符 str
- delete(str):删除字符 str
举个例子,假设 A 用户将「百度 Web」变成「Web 前端」,相当于产生了如下 3 个操作:
delete('百度 '), //删掉「百度 」
retain(3), //跳过 3 个字符(也就是「Web」)
insert(' 前端') //插入「 前端」提取这些操作可以通过 Levenshtein distance(编辑距离)算法来实现。那它如何解决冲突问题了?比如这时如果 B 用户将「百度 Web」改成了「百度 FE」,B 所生产的操作步骤将会是如下:
retain(3), //跳过 3 个字符(也就是「百度 」)
delete('Web'),
insert('FE')如果我们先应用 A 的操作,将字符串变为「Web 前端」,然后再应用 B 的操作时就会失效,因为在执行 B 的第二个操作 delete('Web')时并没有「Web」,这时从第四个字符开始已经变成了「 前端」。
因此我们需要转换 B 的操作来适应新的字符串,比如调成如下操作:
delete('Web'),
insert('FE'),
retain(3)这个转换算法就是 OT 的核心,实际上 OT 指的是一类技术,而不是具体的算法,这个思路就是首先将编辑转成操作(Operational),如果多人操作同时进行,需要对这些操作进行转换(Transformation),这就是为什么叫 Operational Transformation,而具体应该拆分成哪些操作以及转换算法都是可以自定义的,因此 OT 可以灵活地支持各种协同编辑应用,比如非文本类的编辑。
回到之前 Myer 算法导致丢字符的那个例子,我们看看 OT 是否能解决,这里我使用了一个开源库 changesets,以下是基于它实现合并的例子:
var Changeset = require('changesets').Changeset;
var text = "百度 Web"
, textA = "Web 前端"
, textB = "百度 FE";
var csA = Changeset.fromDiff(text, textA);
var csB = Changeset.fromDiff(text, textB);
var csB_new = csB.transformAgainst(csA); //这里这就是操作转换
var textA_new = csA.apply(text);
console.log(csB_new.apply(textA_new)); //结果是「 前端FE」结果并不正确,正确的应该是「FE 前端」,查看一下csB_new的内容,发现它实际上是转换成了如下操作:
delete(3), //注意 changesets 在这里的参数不是字符串而是数字,它会直接删掉 3 个字符,不够内容是什么
retain(3),
insert('FE')需要注意这并不是 OT 技术本身的问题,而是 changesets 所实现的转换算法问题,虽然不够完美,但和之前的 Myer 算法相比,至少没丢字符,后来我又做了几个测试,发现 OT 技术的准确率比 Myer 高,因此它是最适合用于协同编辑的技术。
分布式 Operational Transformation
如果看完上面的文章你觉得实现实时协同编辑似乎不难,那你就错了,因为我们之前都没有考虑分布式的问题,OT 技术在学术界都研究 20 多年了,至今也没人总结出一个最好的方法,前 Google Wave 工程师在 ShareJS 首页上这样写道:
Unfortunately, implementing OT sucks. There’s a million algorithms with different tradeoffs, mostly trapped in academic papers. The algorithms are really hard and time consuming to implement correctly. I am an ex Google Wave engineer. Wave took 2 years to write and if we rewrote it today, it would take almost as long to write a second time.
所以其实要做好是很难的,这里面最麻烦的就是分布式导致的问题,接下来将介绍 3 个我能想到的问题及解决方法。
1. 顺序问题
首先第一个问题是顺序问题,因为 OT 等算法都是依赖顺序的,不同顺序会导致结果不同,我们通过下面这张图来说明:

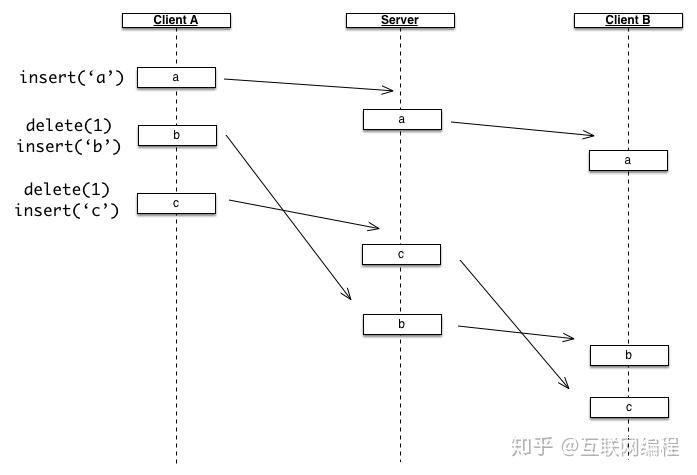
假设 Client A 在做两次修改时发了两个异步请求,可能因为网络延迟导致第二个请求反而先到了,导致最终服务器版本和 Client A 所看到的不一致,同样在服务器发往其它客户端的请求时也会出现乱序的问题,如图中 Client B 也有问题。
这个问题的解决方法很简单,我们可以在客户端和服务器端都加上队列来保证请求顺序,等前一个请求结束后再发下一个请求。
2. 存储的原子操作
如果有多台服务器,或者有多个线程/进程在同时处理请求时就会遇到覆盖问题,因为读写数据库并不是原子操作,比如下面的例子:

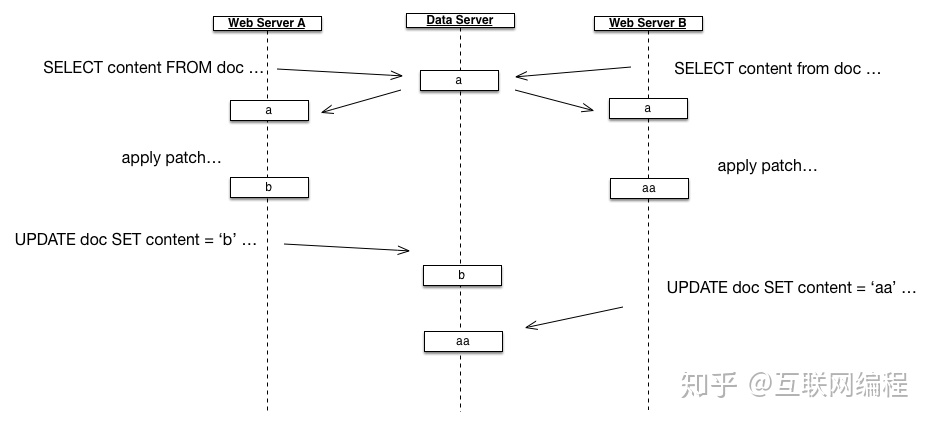
Web Server A 和 Web Server B 同时访问数据库,结果导致 Web Server A 的修改被覆盖了。
好在这种问题还算比较常见,解决办法可以有 3 种:
- 保证操作只在一个线程中执行,比如某个文档的更新只在某个固定的机器,使用 Node 这样的单线程模型提供服务,这样就不可能并行修改了
- 如果数据库支持事务(transaction),可以通过事务来解决
- 如果数据库不支持事务,就只能用分布式锁了,如 ZooKeeper
从实现角度来看,第一和第二种方法都比较简单,而第三种方法会带来很多问题,比如可能导致文档被锁死,假如上锁后由于种种原因没有执行解锁操作,这个文档就会永远被锁住,所以还得加上超时限制等策略。
然而在解决了原子操作后,我们将发现一个新的问题,那就是版本管理问题。
3. 版本管理问题
在前面的例子中,两段新文本的修改都是基于同一个旧版本的,如果旧版本不一样,就有可能出错,具体可以通过下面这张图来解释:

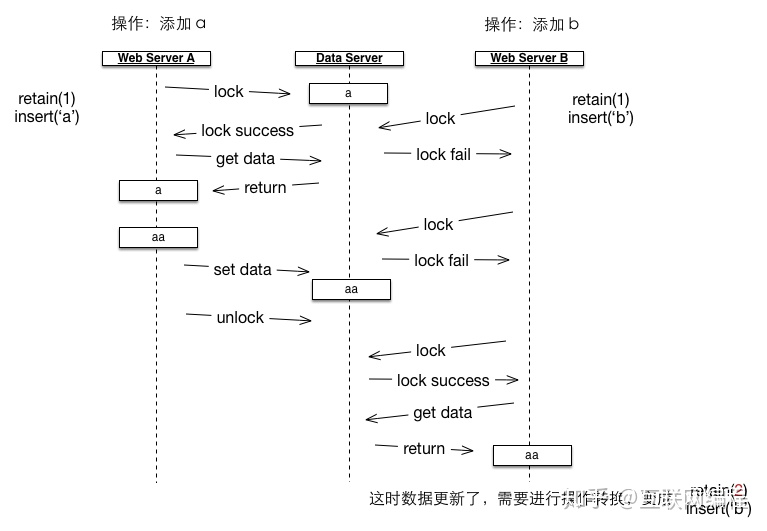
在这个例子中,Web Server A 接收到操作命令是将「a」文本改成「aa」,Web Server B 接收到操作命令是将「a」文本改成「ab」,这里我们加上了锁机制来避免同时读写数据,Web Server A 首先得到了锁,然后修改并更新数据,而 Web Server B 需要先等待数据解锁,等 Web Server B 拿到数据后它已经从「a」变成了「aa」,如果还按照 retain(1), insert('b') 进行修改,数据将变成「ab」,而不是正确的「aab」,引起这个问题的原因就是旧版本不一致,Web Server B 需要根据 Web Server A 的操作进行操作转换,变成 retain(2), insert('b'),然后才能对数据进行修改。
因此想要解决这个问题,就必须引入版本,每次修改后都需要存储下新版本,有了版本我们就能使用 diff 功能来计算不同版本的差异,得到其它人修改的内容,然后通过 OT 合并算法合并两个操作,如下所示:

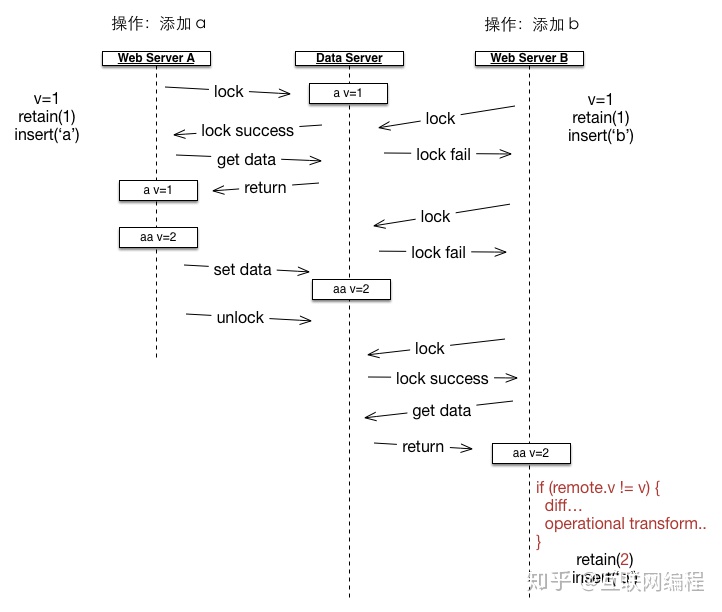
在 Web Server A 操作前数据版本是 v=1,操作后变成了 v=2,等到 Web Server B 处理的时候,它通过版本比较发现不一致,所以就首先通过编辑距离算法算出 Web Server A 所做的操作,然后用这个操作来对自己的操作进行转换,得到正确的新操作,从而避免了覆盖问题。
如果保存所有版本会导致数据量大大增加,所以还需要再优化,比如每个服务器保存一个数据副本,但这里就不再展开了,可以看要支持分布式 还是挺麻烦的,不过目前出现了一些前后端整合的方案,如 ShareJS 和 OpenCoweb Framework,可以参考。
另外之前提到的 Myer’s diff 算法也有分布式解决方案,具体细节可以参考这篇文档。
初步结论
- 如果你只是一个内部小项目,实时性要求不高,但对准确性要求比较高
- 推荐用 merge 或 diff3 工具,出现同一行冲突时由用户来解决,这样能避免自动合并有可能出错的问题
- 如果想具备一定的实时性,流量不大,不想实现太复杂,且对少量的冲突可以忍受
- 推荐用 Myer’s diff,后端只开一个 Node 进程
- 如果想具备实时性,且有多台后端服务同时处理
- 可以用 Operational Transformation 或 Myer’s diff,但需要注意分布式带来的问题
- 如果需要很精细的控制,如支持富文本编辑等非单纯文本格式
- 只能使用 Operational Transformation,但要自己实现操作合并算法,比如 XML 可以参考这篇文章
后续
除了文本合并,真正要做在线编辑还有很多细节处理,感兴趣的同学可以继续研究:
- 支持选区,看到其他人选择的文本段,当然,这也有合并问题
- 指针要更随文本变化移动到正确的位置
- 支持 undo