
发现conc并发库一个有趣的问题
上周看到一个新库conc,
better structured concurrency for go.
这个库的目标是:
更难出现goroutine泄漏
优雅处理panic
使并发的代码更易读
我们一条条细说
。
Make it harder to leak goroutines
goroutine泄漏还是很常见的。
日常我们使用go的时候直接go func开启一个goroutine,写上对应的逻辑,g会进入到某个p的本地队列,最终由p绑定的m执行这个goroutine。
你能保证一个goroutine在某个时刻一定会结束它的生命周期吗?
搜了下著名开源项目etcd,goroutine leak还真不少
。
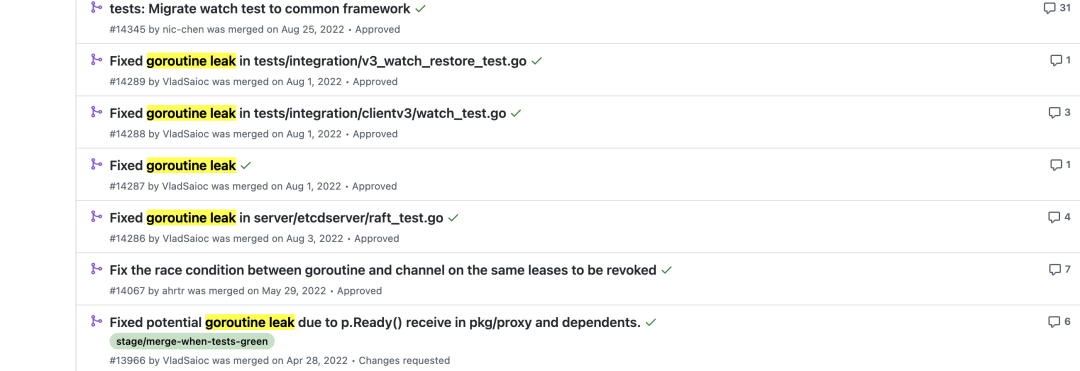
看其中一个简单的泄漏bug
。
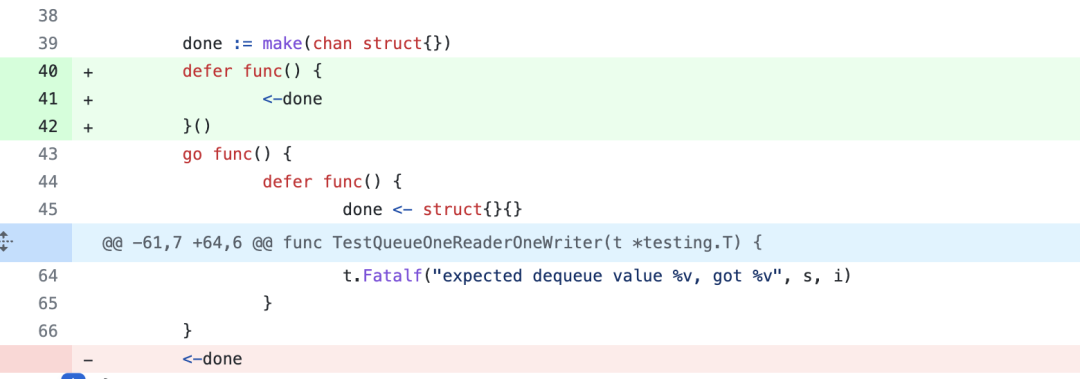
done是一个无缓冲的chan,一开始接收动作在最下面,因为中间还有一些没展开的代码可能会导致程序不会执行到<-done,然后goroutine就会发生泄漏。
解决方法就是通过defer保证一定会执行<-done
。
那么conc是如何做的?
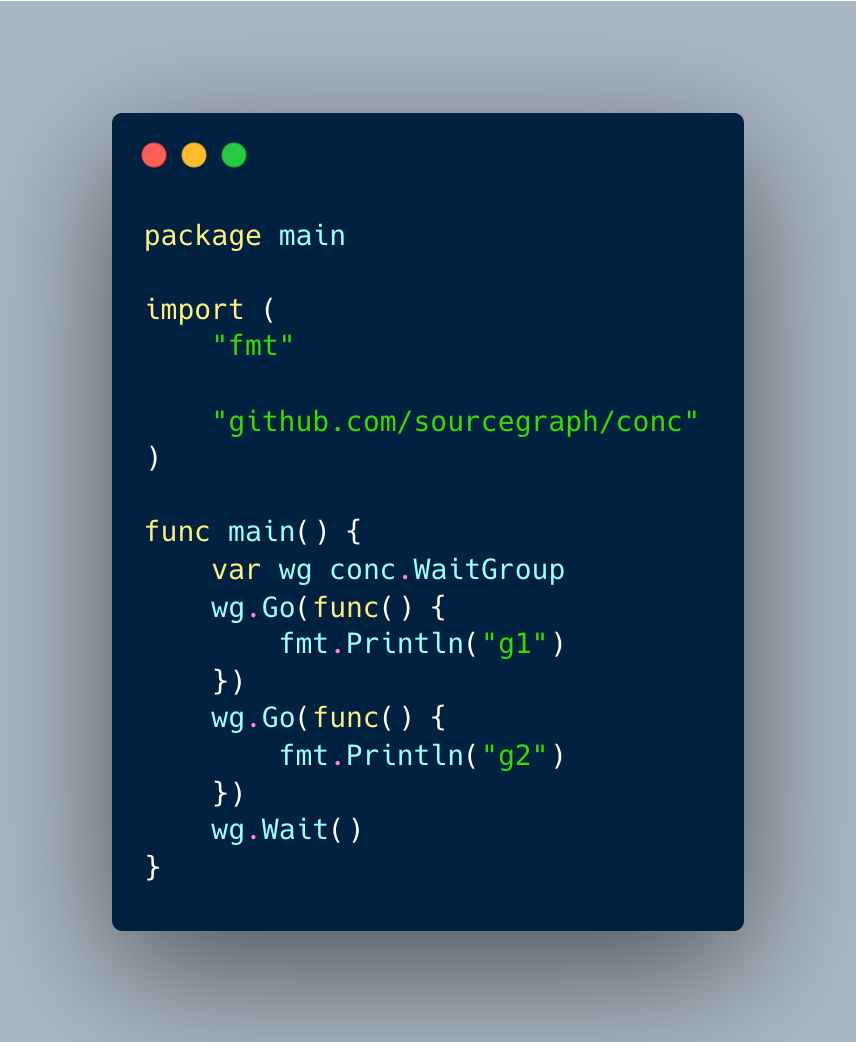
conc的理念是程序中的每一个goroutine由一个owner创建,归属于owner。一个owner确保它拥有的所有goroutine正常退出,这里的owner也就是conc.WaitGroup。ps:这个结构是不是超级熟悉。
但是这真的能像他说的那样Make it harder to leak goroutines吗?
goroutine的泄漏问题取决于用户对goroutine能正确退出的逻辑保证,和你如何封装没关系吧?
在我看来conc和标准库的sync.WaitGroup一样,只是等待所有goroutine执行完毕,用于检测到这个行为。
要是goroutine里面含有泄漏的bug,该泄漏还得泄漏,Wait该等待还得老实等待。
Handle panics gracefully
如果直接使用go func,那么可能每一个goroutine都得写上recover,所以一般我们在使用goroutine的时候,都是自己封装一个GoSafe函数。
这样就可以在里面统一捕获panic,然后打包调用栈一些信息,进一步处理。
在conc中,每个goroutine有owner概念,所以是由owner捕获goroutine的panic。

只会记录第一个panic的goroutine堆栈信息。然后操作Wait的时候
,
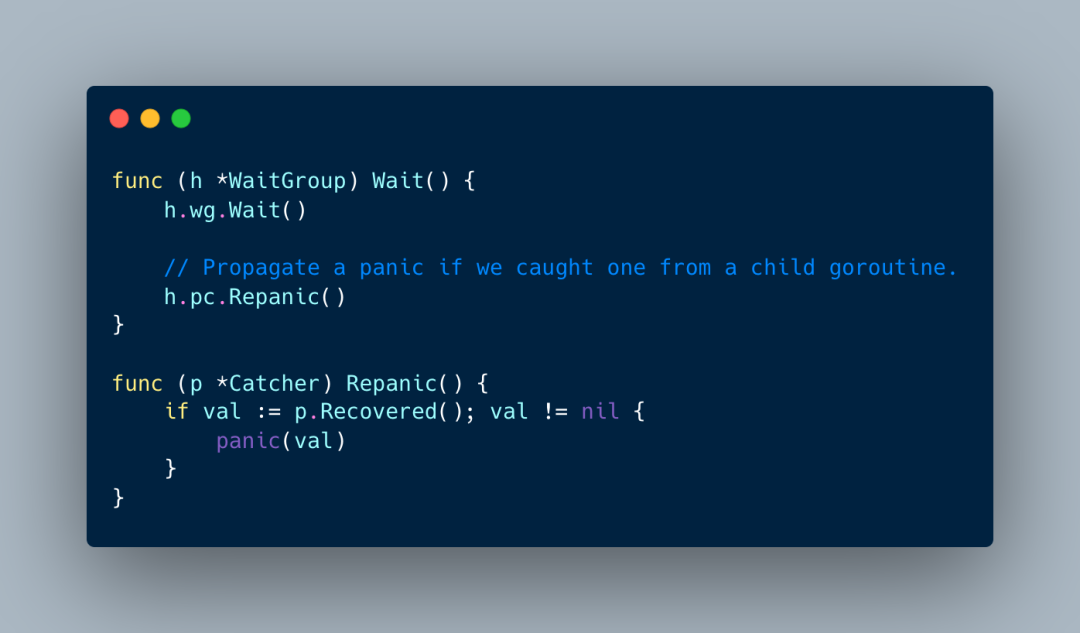
超级粗暴。当conc.WaitGroup里面任何一个goroutine发生panic,调用wg.Wait()的时候就会panic,把goroutine panic的堆栈信息作为panic的值。
写这篇文章的时候看到他们在issue上讨论添加一个类似WaitSafe()函数[1]
。
Make concurrent code easier to read
这个还是节省了一些工作的,作者给了几个例子。
上面我们看到的WaitGroup,不再需要用户执行Add和Done操作了。同时内部捕获panic,虽然处理有点粗暴
。
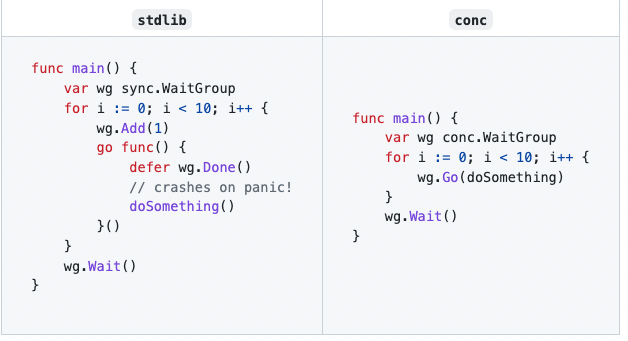
除此之外,控制goroutine数量来并发处理批量数据的例子。

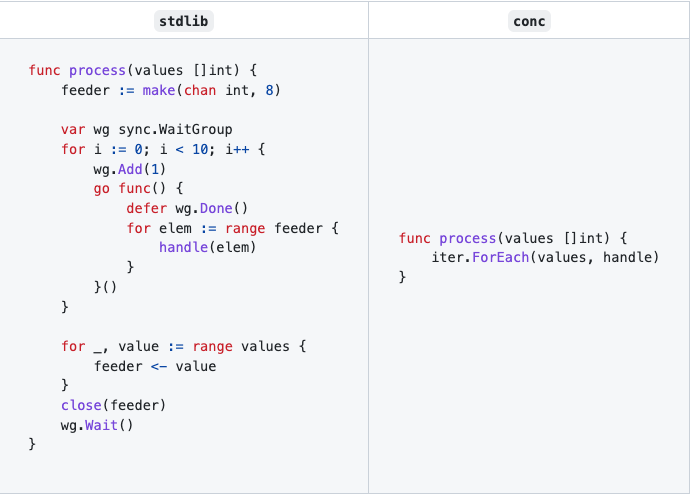
可以看出,确实省了很多的操作,其他例子可以自行查看。
上面我们说到pool,其实就是一个并发执行任务的worker池,之前文章也介绍过这种模式。
conc里面有几个类型的pool:ContextPool,ErrorPool,ResultPool,ResultContextPool,ResultErrorPool。
它们都基于最基础的Pool结构
。

limiter就是一个很简单的用chan控制worker goroutine数量
。

核心逻辑也很简单,
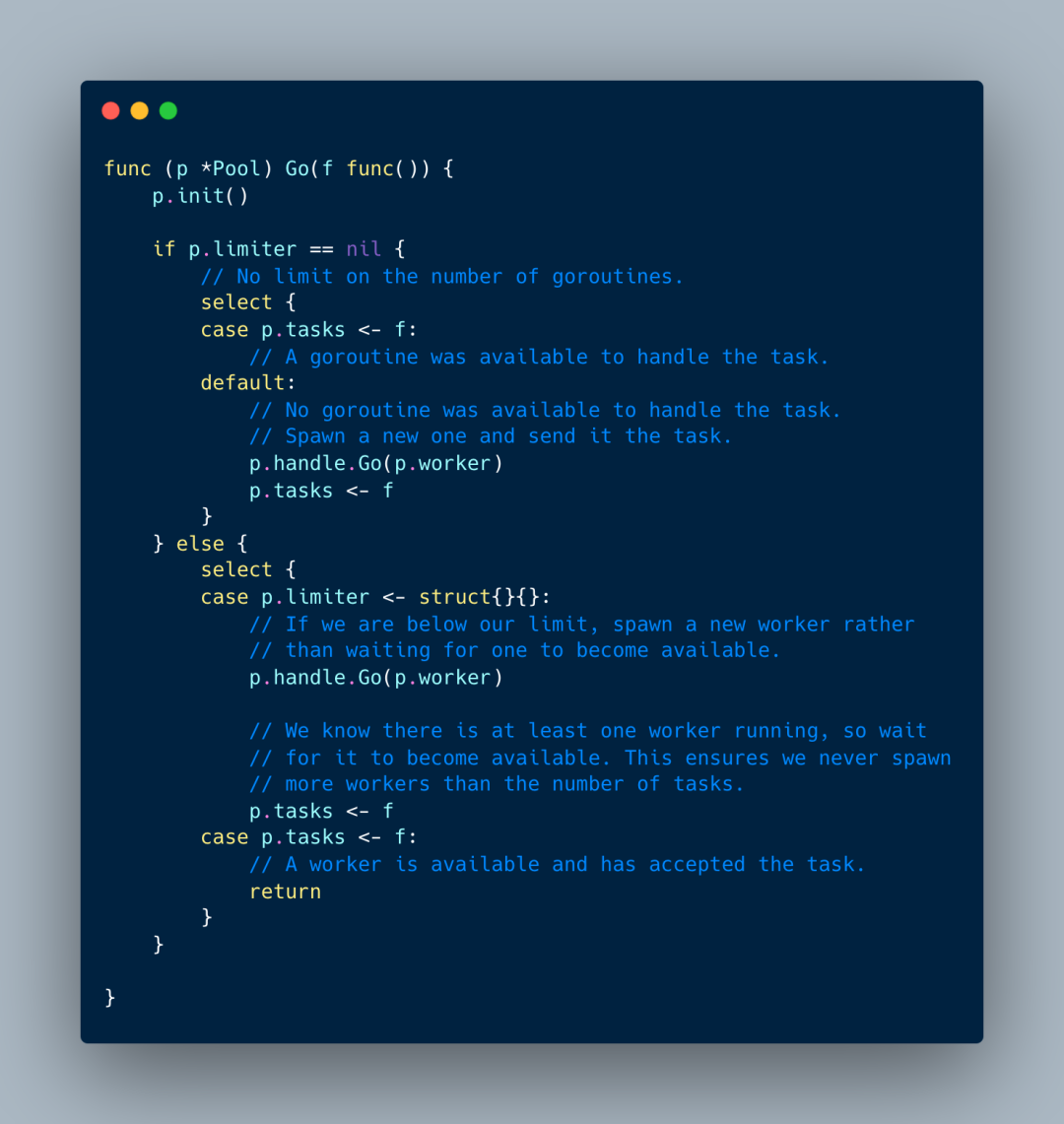
如果没有设置limiter,那么优先找空闲的worker。否则就创建一个新worker,然后投递任务进去。
设置了limiter,
达到了limter worker数量上限,那就只能把任务投递给空闲的worker,没有空闲就阻塞等着。
如果没有达到上限,空闲worker也存在,那就由select随机选择。
否则的话就创建一个新的worker。
彩
蛋
看代码的时候发现这里面有个问题
,

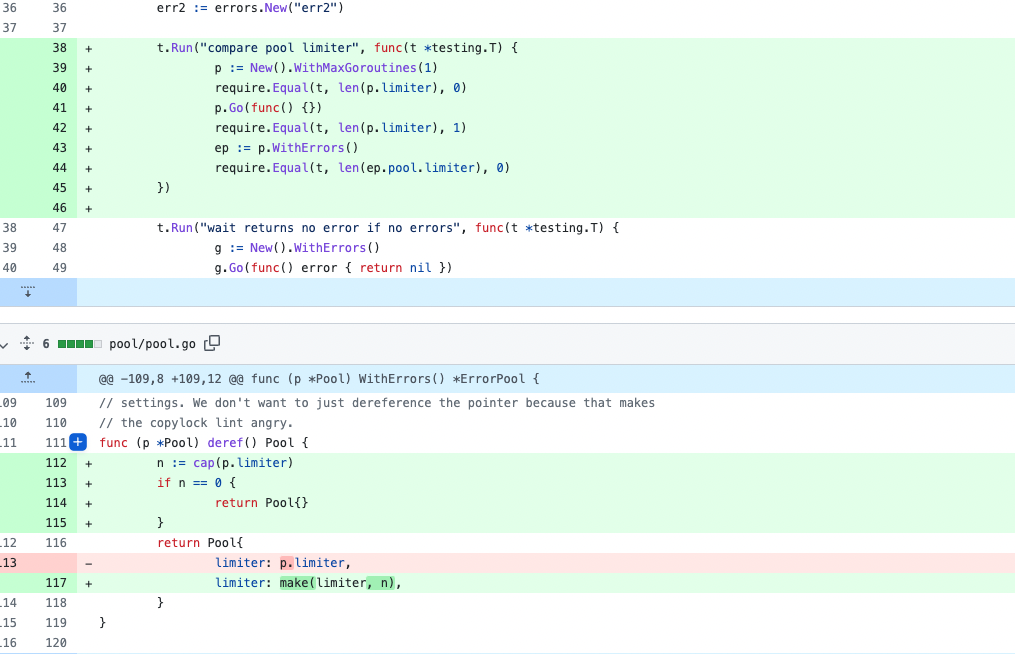
这个函数会返回一个新的Pool,上面我说过limiter是一个chan结构,在go中chan是一个引用类型,所以这里对limiter就是一个浅拷贝。
因此,下面这段代码
,
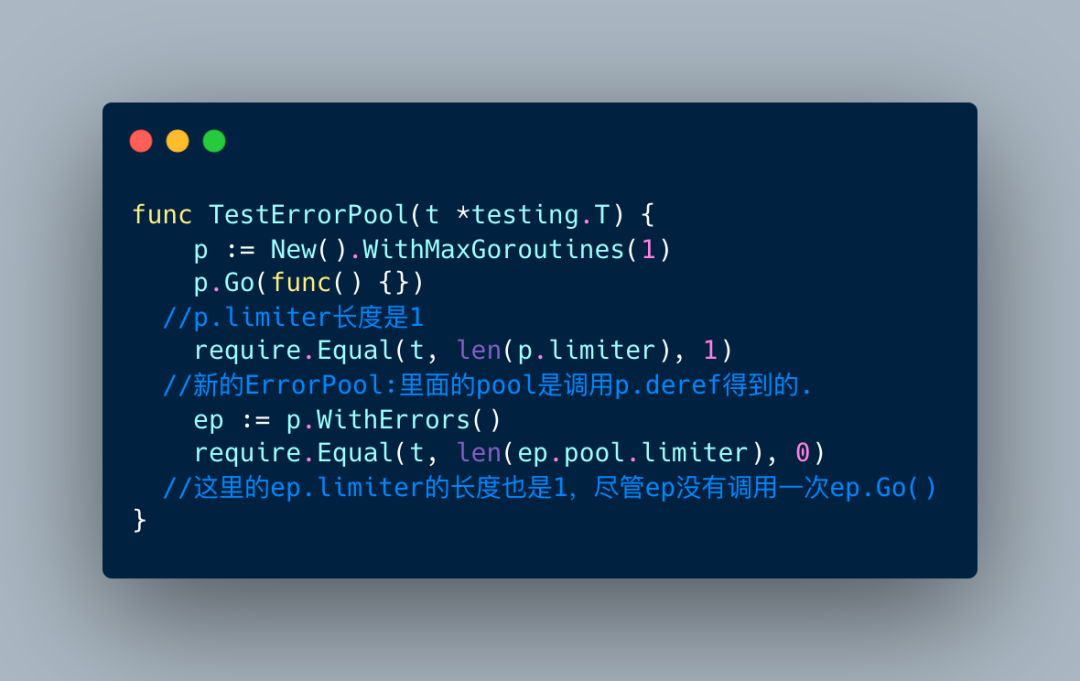
正因为这种“特性”,如果我们写了下面的代码,
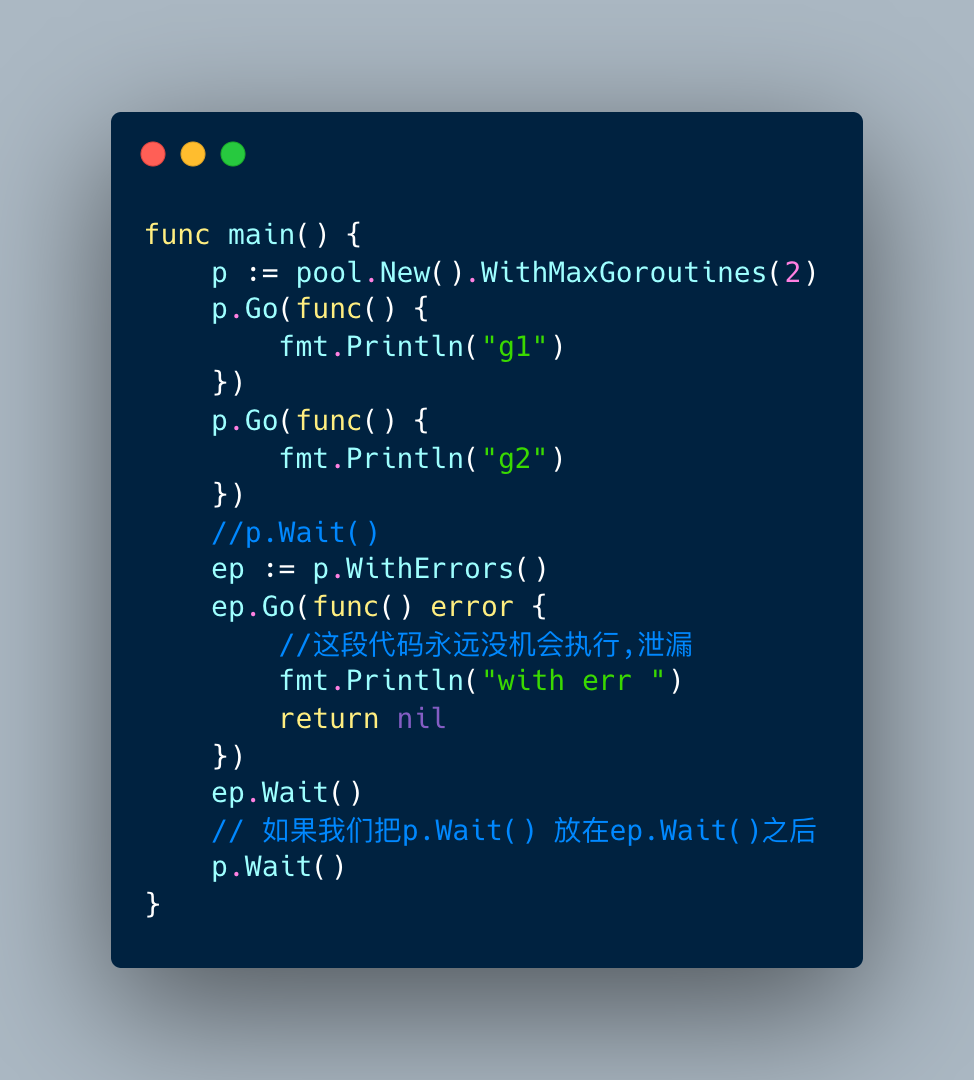
ep.Go里面的逻辑永远都没机会执行。
原因就在于,第一个loop创建的时候限制了goroutine数量。然后执行两次p.Go,这样就会创建两个只属于p的workers,同时也让limiter到达限制数。
当ep想要执行ep.Go的时候,只能执行p.tasks <- f,但是这时候ep还没有机会创建属于自己的worker,所以会阻塞到死。
我提了一个pr[2],其实就是把上面的浅拷贝换成深拷贝
。
但是作者回复说,
Currently calling any configuration methods on the pool after calling pool.Go() is unsupported because the configuration methods take ownership of and mutate the pool. This might not be ideal though since ownership can't actually be enforced with Go. It would be less of a foot
gun to just return a fully copy each time.
我理解的意思就是不支持我这么玩,简单的说不支持在执行pool.Go()后调用这些操作
😂。
[1]
https://github.com/sourcegraph/conc/issues/29
[2]
https://github.com/sourcegraph/conc/issues/43
推荐阅读
福利
我为大家整理了一份
从入门到进阶的Go学习资料礼包
,包含学习建议:入门看什么,进阶看什么。
关注公众号 「polarisxu」,回复
ebook
获取;还可以回复「进群」,和数万 Gopher 交流学习。