
【学术前沿】关键任务中自动化适应的认知建模

声明:本文只是针对个人学习记录,侵权可删。本人自觉遵守《中华人民共和国著作权法》和《伯尔尼公约》等法律,其他个人或组织等转载请保留此声明,并自负法律责任。论文版权与著作权等全归原作者所有。

文章摘要
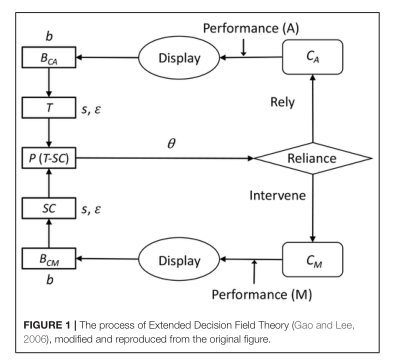
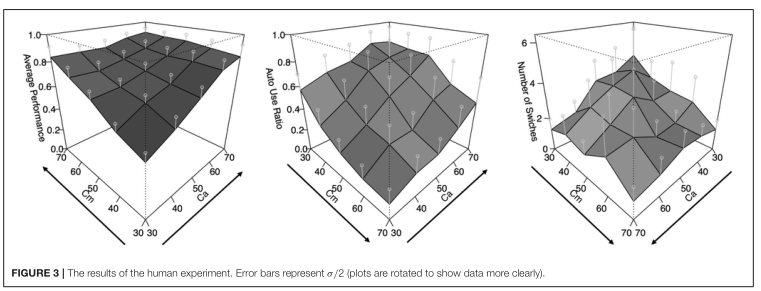
-R(自适应控制的思想理性)开发的。我们还介绍了两种强化学习方法:随着时间的推移奖励的总和和门控机制。这个模型通过控制感知和运动控制的产品来完成这个任务。这些产品的效用价值是基于每个感知-行动循环中的奖励而更新的。该模型的运行模拟了行为数据的总体趋势,如性能(跟踪精度)、汽车使用率和两种模式之间的切换次数,表明我们模型中所做的假设具有一定的有效性。这项工作展示了如何结合不同的认知建模范式,从而产生自动化的实际表现和解决方案,以及对自动化的信任。
引言
自动化技术近年来取得了显著进展,可以部分替代人类的认知功能。虽然这种技术的应用领域是多样的,但最近一个突出的领域是车辆的自动操作。在我们的社会中,船舶和飞机的操作一般都是自动化的。对于汽车,一些功能的自动化,如速度控制(即自适应巡航控制)和制动(防抱死)也已经使用了很长时间。近年来,随着传感技术和机器学习技术的飞速发展,转向自动控制得到了积极的发展。然而,自动驾驶(自动驾驶汽车)的全面应用仍然存在障碍。一段时间以来,人们一直认为,自动控制系统将与驾驶员的监控系统一起,在自动控制系统无法做出正确反应的情况下,随时进行干预。
当引进不限于车辆自动控制的新技术时,这些技术的误用(过度依赖)和废弃(不充分利用)往往成为一个问题。不使用新技术会导致创新减少,而滥用新技术则会导致严重事故。在人为因素领域,这类问题已被反复讨论。
但是,该领域的先前研究并未充分考虑时间因素涉及新技术的适应过程。与人因中研究的其他一些任务不同,车辆的操作是一个感知、判断、行动依次重复的动态连续过程。自动化车辆系统部分地替代了这种人工操作。在一个操作人员可以使用自动操作的情况下,他/她重复感知和判断的周期,同时观察到一个自动化系统执行整个周期。当操作人员注意到自动控制有问题时,需要立即关闭自动控制,恢复手动控制。
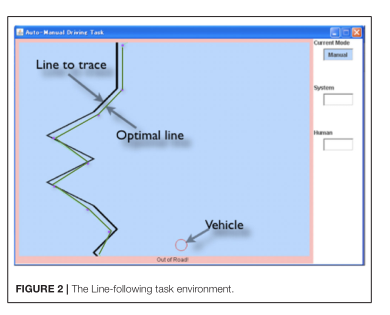
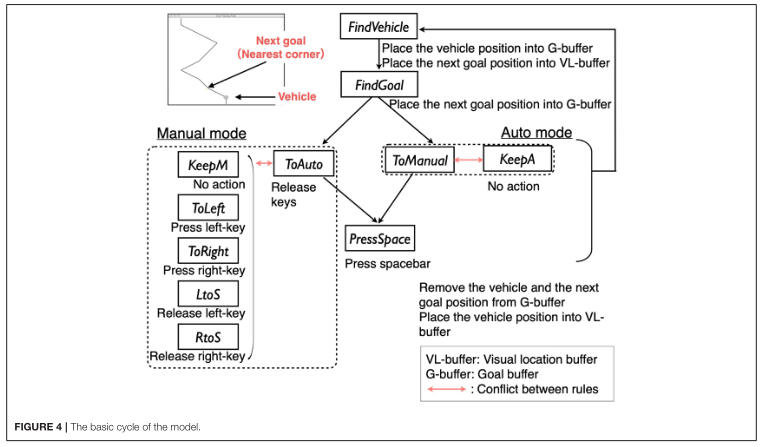
在本文中,我们提出了一个简单的任务,该任务具有带有自动化的车辆连续操作的一些特征,并构建了一个模型来揭示在像车辆自动操作这样的时间关键任务中,什么样的机制可以模拟人类对自动化的适应。我们特别尝试将传统的强化学习算法与认知架构相结合来回答这个问题。使用认知架构,我们将探索这个问题使用适当的时间限制的行为。
主要图表
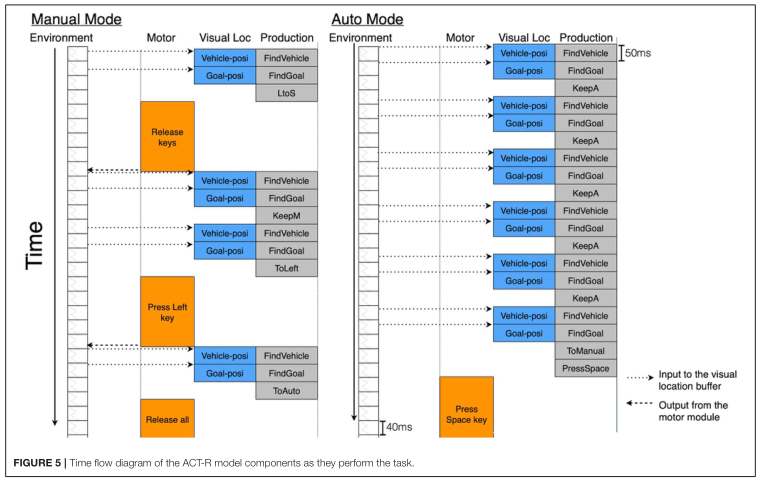

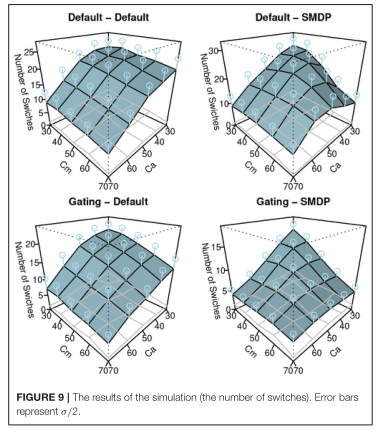
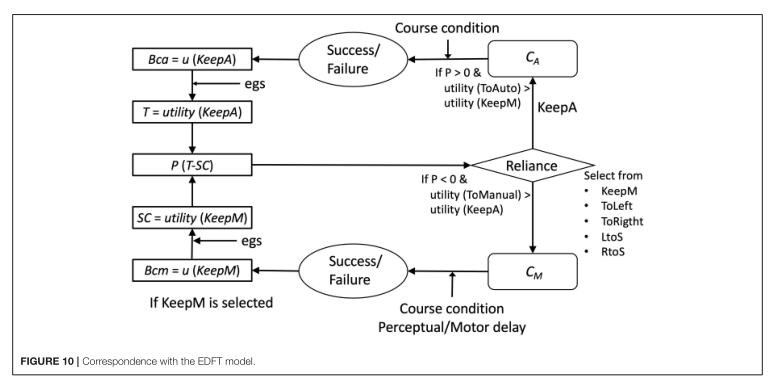
主要结论