
看完JDK并发包源码的这个性能问题,我惊了!
这是why的第 144 篇原创文章
你好呀,我是歪歪。
国庆的时候闲来无事,就随手写了一点之前说的比赛的代码,目标就是保住前 100 混个大赛的文化衫就行了。
现在还混在前 50 的队伍里面,稳的一比。

其实我觉得大家做柔性负载均衡那题的思路其实都不会差太多,就看谁能把关键的信息收集起来并利用上了。
由于是基于 Dubbo 去做的嘛,调试的过程中,写着写着我看到了这个地方:
org.apache.dubbo.rpc.protocol.AbstractInvoker#waitForResultIfSync

先看我框起来的这一行代码,aysncResult 的里面有有个 CompletableFuture ,它调用的是带超时时间的 get() 方法,超时时间是 Integer.MAX_VALUE,理论上来说效果也就等同于 get() 方法了。
从我直观上来说,这里用 get() 方法也应该是没有任何毛病的,甚至更好理解一点。
但是,为什么没有用 get() 方法呢?
其实方法上的注释已经写到原因了,就怕我这样的人产生了这样的疑问:
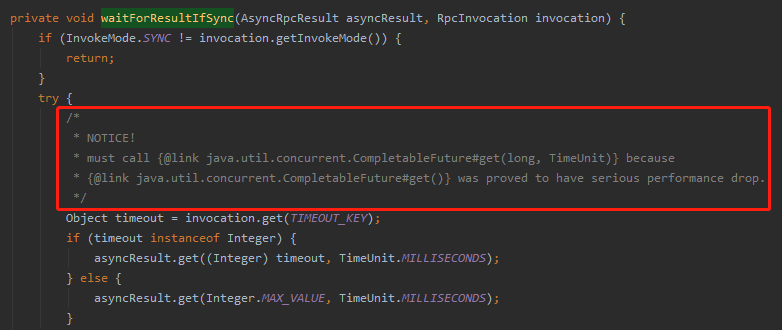
抓住我眼球的是这这几个单词:
have serious performance drop。
性能严重下降。
大概就是说我们必须要调用 java.util.concurrent.CompletableFuture#get(long, java.util.concurrent.TimeUnit) 而不是 get() 方法,因为 get 方法被证明会导致性能严重的下降。
对于 Dubbo 来说, waitForResultIfSync 方法,是主链路上的方法。
我个人觉得保守一点说,可以说 90% 以上的请求都会走到这个方法来,阻塞等待结果。所以如果该方法如果有问题,则会影响到 Dubbo 的性能。
Dubbo 作为中间件,有可能会运行在各种不同的 JDK 版本中,对于特定的 JDK 版本来说,这个优化确实是对于性能的提升有很大的帮助。
就算不说 Dubbo ,我们用到 CompletableFuture 的时候,get() 方法也算是我们常常会用到的一个方法。
另外,这个方法的调用链路我可太熟悉了。
因为我两年前写的第一篇公众号文章就是探讨 Dubbo 的异步化改造的。
当年,这部分代码肯定不是这样的,至少没有这个提示。
因为如果有这个提示的话,我肯定第一次写的时候就注意到了。
果然,我去翻了一下,虽然图片已经很模糊了,但是还是能隐约看到,之前确实是调用的 get() 方法:
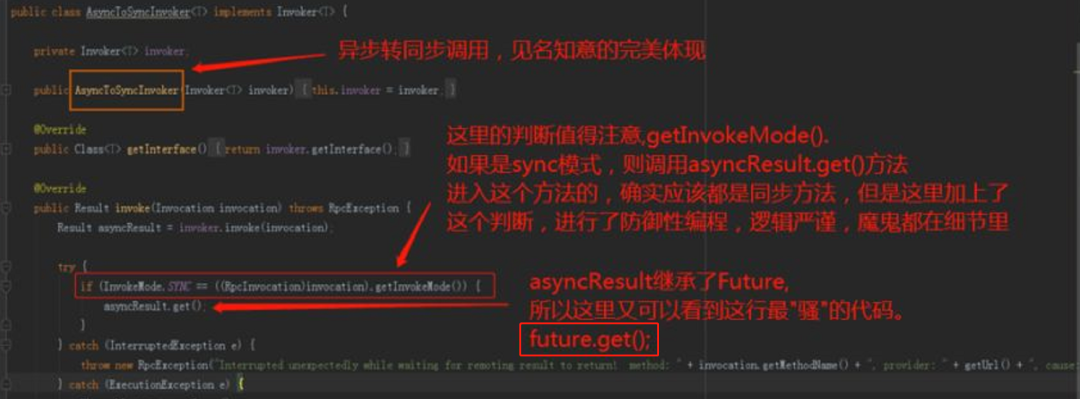
我还称之为最“骚”的一行代码。
因为这一行的代码就是 Dubbo 异步转同步的关键代码。

前面只是一个引子,本文不会去写 Dubbo 相关的知识点。
主要写写 CompletableFuture 的 get() 到底有啥问题。
放心,这个点面试肯定不考。
只是你知道这个点后,恰好你的 JDK 版本是没有修复之前的,写代码的时候可以稍微注意一下。
学 Dubbo 在方法调用的地方加上一样的 NOTICE,直接把逼格拉满。等着别人问起来的时候,你再娓娓道来。
或者不经意间看到别人这样写的时候,轻飘飘的说一句:这里有可能会有性能问题,可以去了解一下。

啥性能问题?
根据 Dubbo 注释里面的这点信息,我也不知道啥问题,但是我知道去哪里找问题。
这种问题肯定在 openJDK 的 bug 列表里面记录有案,所以第一站就是来这里搜索一下关键字:
https://bugs.openjdk.java.net/projects/JDK/issues/
一般来说,都是一些陈年老 BUG,需要搜索半天才能找到自己想要的信息。
但是,这次运气好到爆棚,弹出来的第一个就是我要找的东西,简直是搞的我都有点不习惯了,这难道是传说中的国庆献礼吗,不敢想不敢想。
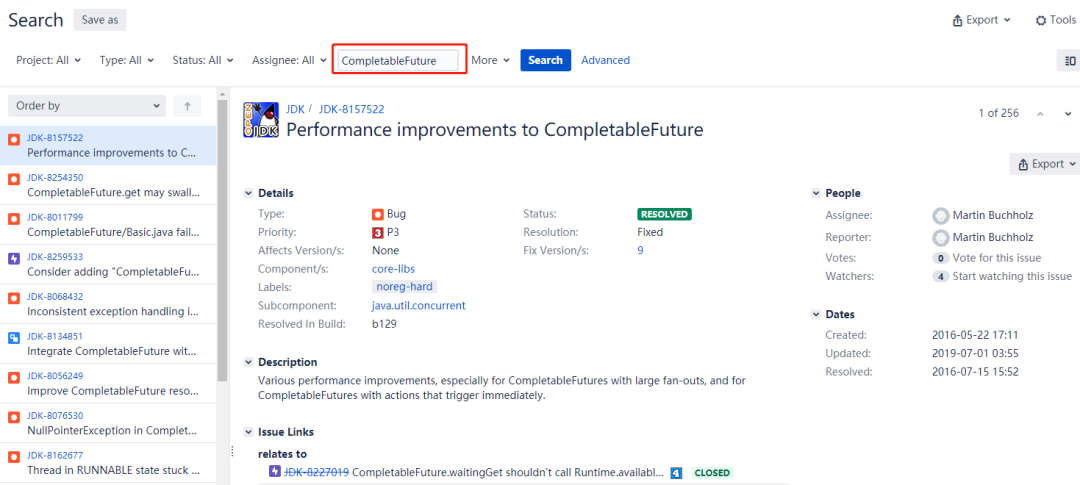
标题就是:对CompletableFuture的性能改进。
里面提到了编号为 8227019 的 BUG。
https://bugs.openjdk.java.net/browse/JDK-8227019
我们一起看看这个 BUG 描述的是啥玩意。
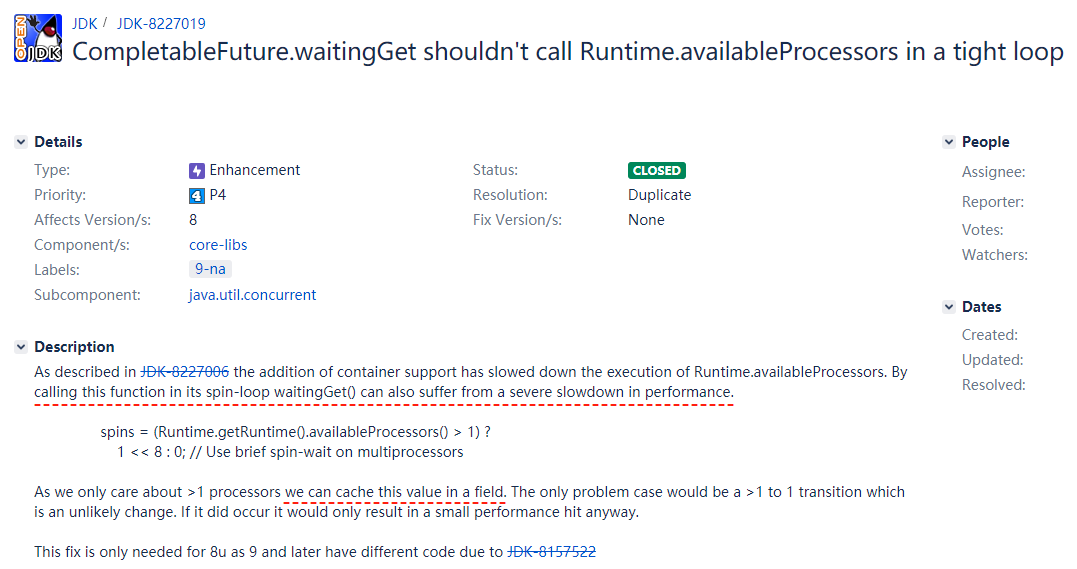
标题翻译过来,大概意思就是说 CompletableFuture.waitingGet 方法里面有一个循环,这个循环里面调用了 Runtime.availableProcessors 方法。且这个方法被调用的很频繁,这样不好。
在详细描述里面,它提到了另外的一个编号为 8227006 的 BUG,这个 BUG 描述的就是为什么频繁调用 availableProcessors 不太好,但是这个我们先按下不表。
先研究一下他提到的这样一行代码:
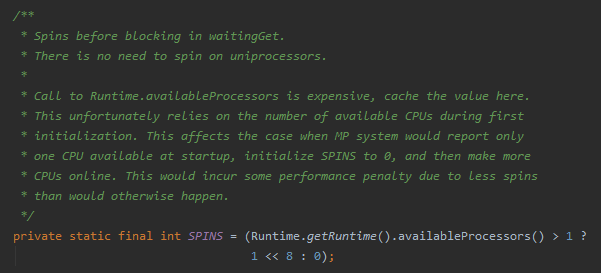
spins = (Runtime.getRuntime().availableProcessors() > 1) ?
1 << 8 : 0; // Use brief spin-wait on multiprocessors
他说位于 waitingGet 里面,我们就去看看到底是怎么回事嘛。
但是我本地的 JDK 的版本是 1.8.0_271,其 waitingGet 源码是这样的:
java.util.concurrent.CompletableFuture#waitingGet
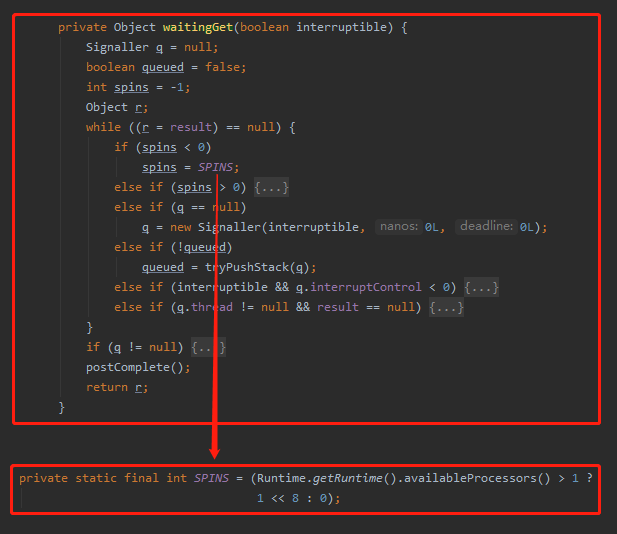
先不管这几行代码是啥意思吧,反正我发现没有看到 bug 中提到的代码,只看到了 spins=SPINS ,虽然 SPINS 调用了 Runtime.getRuntime().availableProcessors() 方法,但是该字段被 static 和 final 修饰了,也就不存在 BUG 中描述的“频繁调用”了。
于是我意识到我的版本是不对的,这应该是被修复之后的代码,所以去下载了几个之前的版本。
最终在 JDK 1.8.0_202 版本中找到了这样的代码:
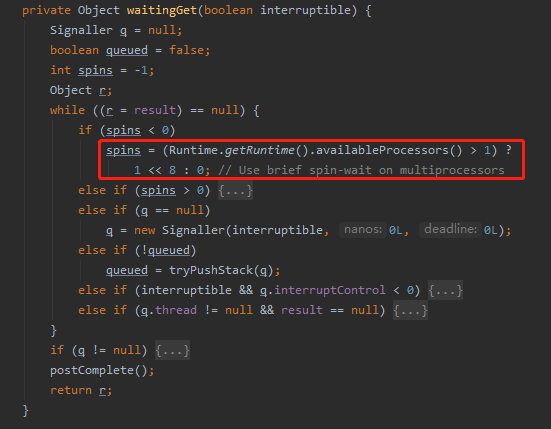
和前面截图的源码的差异就在于前者多了一个 SPINS 字段,把 Runtime.getRuntime().availableProcessors() 方法的返回缓存了起来。
我一定要找到这行代码的原因就是要证明这样的代码确实是在某些 JDK 版本中出现过。
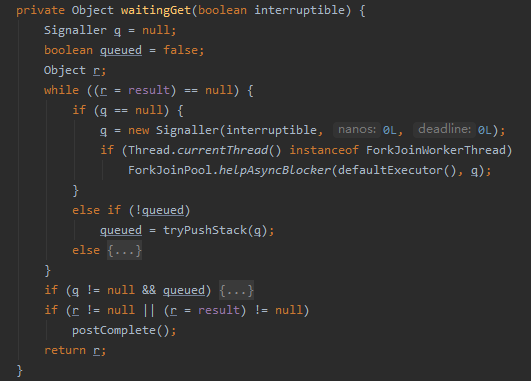
好了,现在我们看一下 waitingGet 方法是干啥的。
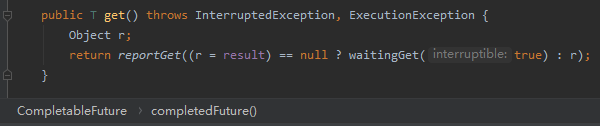
首先,调用 get() 方法的时候,如果 result 还是 null 那么说明异步线程执行的结果还没就绪,则调用 waitingGet 方法:
而来到 waitingGet 方法,我们只关注 BUG 相关这两个分支判断:
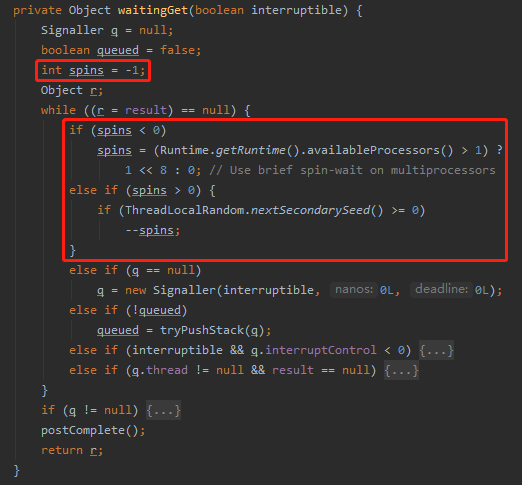
首先把 spins 的值初始化为 -1。
然后当 result 为 null 的时候,就一直进行 while 循环。
所以,如果进入循环,第一次一定会调用 availableProcessors 方法。然后发现是多处理器的运行环境,则把 spins 置为 1<<8 ,即 256。
然后再次进行循环,走入到 spins>0 的分支判断,接着做一个随机运算,随机出来的值如果大于等于 0 ,则对 spins 进行减一操作。
只有减到 spins 为 0 的时候才会进入到后面的这些被我框起来的逻辑中:
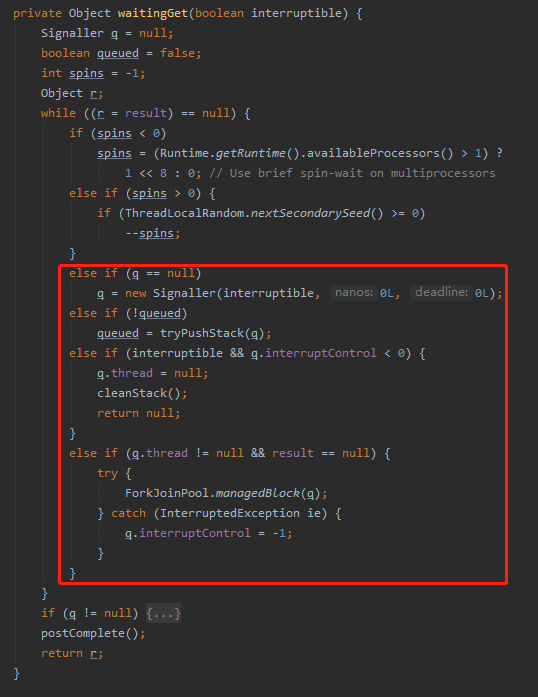
也就是说这里就是把 spins 从 256 减到 0,且由于随机函数的存在,循环次数一定是大于 256 次的。
但是还有一个大前提,那就是每次循环的时候都会去判断循环条件是否还成立。即判断 result 是否还是 null。为 null 才会继续往下减。
所以,你说这段代码是在干什么事儿?
其实注释上已经写的很清楚了:
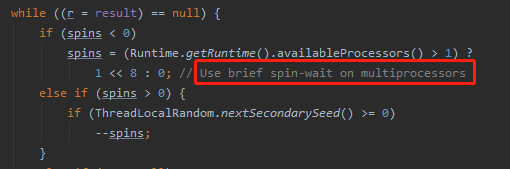
Use brief spin-wait on multiprocessors。
brief,这是一个四级词汇哈,得记住,要考的。就是“短暂”的意思,是一个不规则动词,其最高级是 briefest。
对了,spin 这个单词大家应该认识吧,前面忘记给大家教单词了,就一起讲了,看小黑板:

所以注释上说的就是:如果是多处理器,则使用短暂的自旋等待一下。
从 256 减到 0 的过程,就是这个“brief spin-wait”。
但是仔细一想,在自旋等待的这个过程中,availableProcessors 方法只是在第一次进入循环的时候调用了一次。
那为什么说它耗费性能呢?
是的,确实是调用 get() 方法的只调用了一次,但是你架不住 get() 方法被调用的次数多啊。
就拿 Dubbo 举例,绝大部分情况下的大家的调用方式都用的是默认的同步调用的方案。所以每一次调用都会到异步转同步这里阻塞等待结果,也就说每次都会调用一次 get() 方法,即 availableProcessors 方法就会被调用一次。
那么解决方案是什么呢?
在前面我已经给大家看了,就是把 availableProcessors 方法的返回值找个字段给缓存起来:
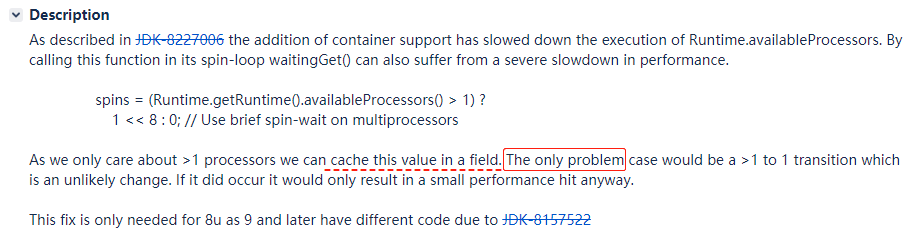
但是后面跟了一个“problem”。
这个“problem”就是说如果我们把多处理器这个值缓存起来了,假设程序运行的过程中出现了从多处理器到单处理器的运行环境变化这个值就不准确了,虽然这是一个不太可能的变化。但是即使这个“problem”真的发生了也没有关系,它只是会导致一个小小的性能损失。
所以就出现了前面大家看到的这样的代码,这就是 “we can cache this value in a field”:
而体现到具体的代码变更是这样的:
http://cr.openjdk.java.net/~shade/8227018/webrev.01/src/share/classes/java/util/concurrent/CompletableFuture.java.udiff.html
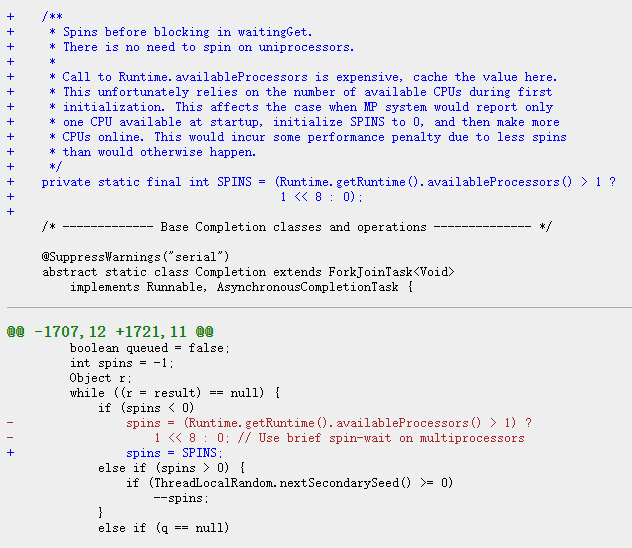
所以,当你去看这部分源码的时候,你会看到 SPINS 字段上其实还有很长一段话,是这样的:
给大家翻译一下:
1.在 waitingGet 方法中,进行阻塞操作前,进行旋转。
2.没有必要在单处理器上进行旋转。
3.调用 Runtime.availableProcessors 方法的成本是很高的,所以在此缓存该值。但是这个值是首次初始化时可用的 CPU 的数量。如果某系统在启动时只有一个 CPU 可以用,那么 SPINS 的值会被初始化为 0,即使后面再使更多的 CPU 在线,也不会发生变化。
当你有了前面的 BUG 的描述中的铺垫之后,你就明白了为什么这里写上了这么一大段话。
有的同学就真的去翻代码,也许你看到的是这样的:
什么情况?根本就看不到 SPINS 相关的代码啊,这不是欺骗老实人吗?

你别慌啊,猴急猴急的,我这不是还没说完嘛?
我们再把目光放到图片中的这句话上:
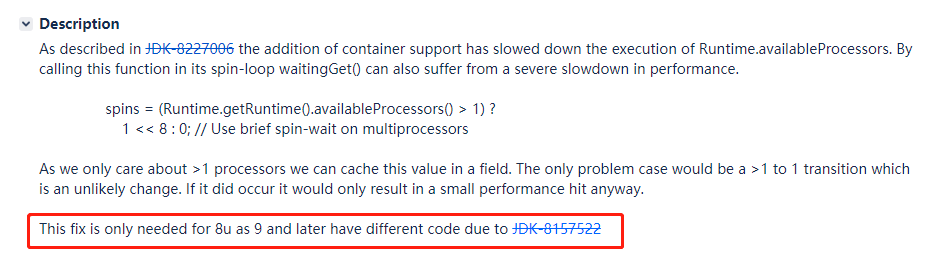
只需要在 JDK 8 中进行这个修复即可,因为 JDK 9 和更高版本的代码都不是这样的写的了。
比如在 JDK 9 中,直接拿掉了整个 SPINS 的逻辑,不要这个短暂的自旋等待了:
http://hg.openjdk.java.net/jdk9/jdk9/jdk/rev/f3af17da360b
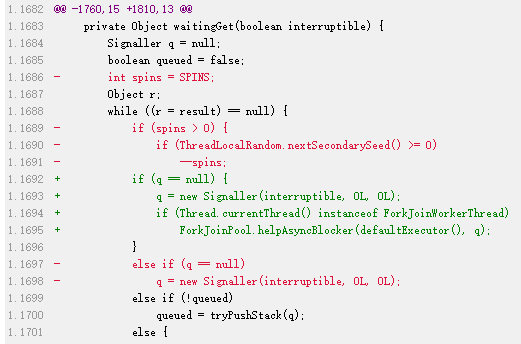
虽然,拿掉了这个短暂的自旋等待,但是其实也算是学习了一个骚操作。
比如怎么在不引入时间的前提下,做出一个自旋等待的效果?
答案就是被拿掉的这段代码。
但是有一说一,我第一次看到这个代码的时候我就觉得别扭。这一个短短的自旋能延长多少时间呢?
加入这个自旋,是为了稍晚一点执行后续逻辑中的 park 代码,这个稍重一点的操作。但是我觉得这个 “brief spin-wait” 的收益其实是微乎其微的。
所以我也理解为什么后续直接把这一整坨代码拿掉了。而拿掉这一坨代码的时候,其实作者并没有意识到这里有 BUG。
这里提到的作者,其实就是 Doug Lea 老爷子。
我为什么敢这样说呢?
那必然是有证据的呀。

依据就在这个 BUG 链接里面提到的编号为 8227018 的 BUG 中,它们其实描述的是同一个事情:

这里面有这样一段对话,出现了 David Holmes 和 Doug Lea:
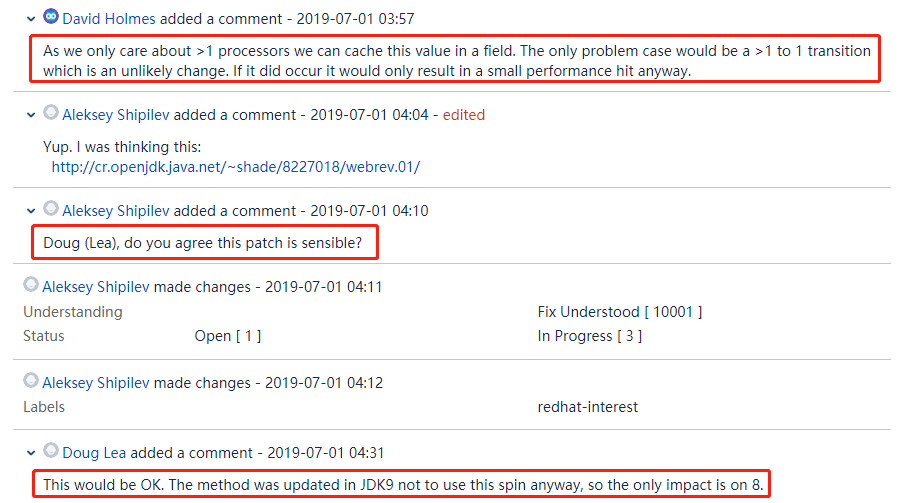
Holmes 在这里面提到了 “cache this value in a field” 的解决方案,并得到了 Doug 的同意。
Doug 说:JDK 9 已经不用 spin 了。
所以,我个人理解是 Doug 在不知道这个地方有 BUG 的情况下,拿掉了 SPIN 的逻辑。至于是出于什么考虑,我猜测是收益确实不大,且代码具有一定的迷惑性。还不如拿掉之后,理解起来直观一点。
Doug Lea 大家都耳熟能详, David Holmes 是谁呢?

《Java 并发编程实战》的作者之一,端茶就完事了。

而你要是对我以前的文章印象足够深刻,那么你会发现早在《Doug Lea在J.U.C包里面写的BUG又被网友发现了。》这篇文章里面,他就已经出现过了:

老朋友又出现了,建议铁汁们把梦幻联动打在公屏上。
到底啥原因?
前面噼里啪啦的说了这么大一段,核心思想其实就是 Runtime.availableProcessors 方法的调用成本高,所以在 CompletableFuture.waitingGet 方法中不应该频繁调用这个方法。
但是 availableProcessors 为什么调用成本就高了,依据是啥,得拿出来看看啊!
这一小节,就给大家看看依据是什么。
依据就在这个 BUG 描述中:
https://bugs.openjdk.java.net/browse/JDK-8157522
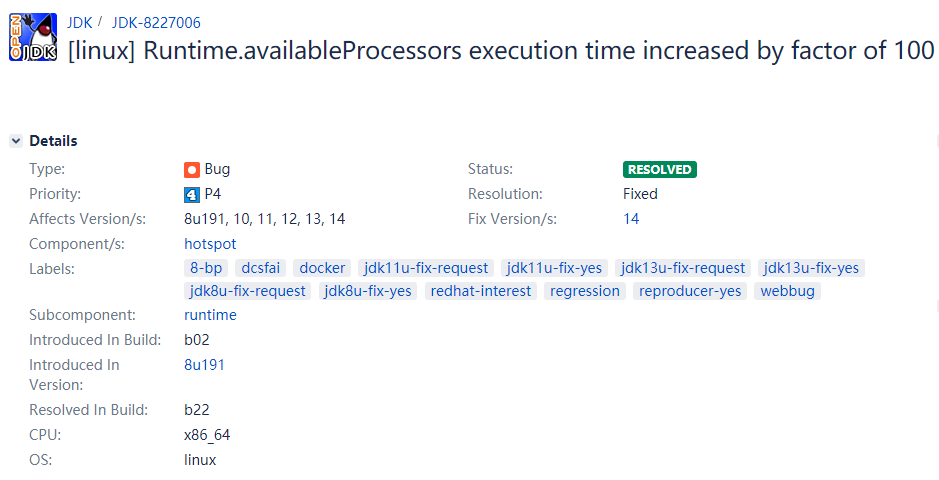
标题上说:在 linux 环境下,Runtime.availableProcessors 执行时间增加了 100 倍。
增加了 100 倍,肯定是有两个不同的版本的对比,那么是哪两个版本呢?

在 1.8b191 之前的 JDK 版本上,下面的示例程序可以实现每秒 400 多万次对 Runtime.availableProcessors 的调用。
但在 JDK build 1.8b191 和所有后来的主要和次要版本(包括11)上,它能实现的最大调用量是每秒4万次左右,性能下降了100倍。
这就导致了 CompletableFuture.waitingGet 的性能问题,它在一个循环中调用了 Runtime.availableProcessors。因为我们的应用程序在异步代码中表现出明显的性能问题,waitingGet 就是我们最初发现问题的地方。
测试代码是这样的:
public static void main(String[] args) throws Exception {
AtomicBoolean stop = new AtomicBoolean();
AtomicInteger count = new AtomicInteger();
new Thread(() -> {
while (!stop.get()) {
Runtime.getRuntime().availableProcessors();
count.incrementAndGet();
}
}).start();
try {
int lastCount = 0;
while (true) {
Thread.sleep(1000);
int thisCount = count.get();
System.out.printf("%s calls/sec%n", thisCount - lastCount);
lastCount = thisCount;
}
}
finally {
stop.set(true);
}
}
按照 BUG 提交者的描述,如果你在 64 位的 Linux 上,分别用 JDK 1.8b182 和 1.8b191 版本去跑,你会发现有近 100 倍的差异。
至于为什么有 100 倍的性能差异,一位叫做 Fairoz Matte 的老哥说他调试了一下,定位到问题出现在调用 “OSContainer::is_containerized()” 方法的时候:
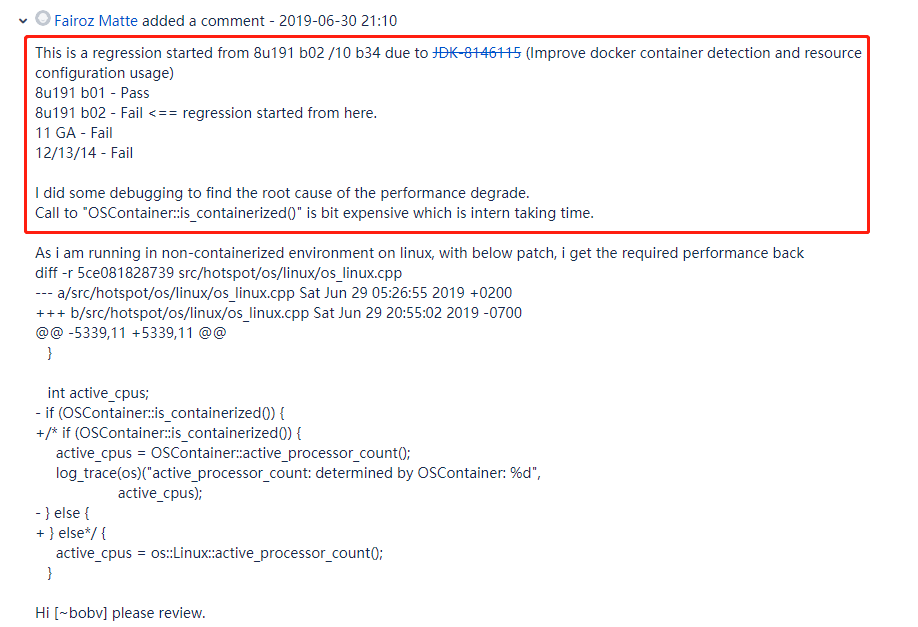
而且他也定位到了问题出现的最开始的版本号是 8u191 b02,在这个版本之后的代码都会有这样的问题。
带来问题的那次版本升级干的事是改进 docker 容器检测和资源配置的使用。
所以,如果你的 JDK 8 是 8u191 b02 之前的版本,且系统调用并发非常高,那么恭喜你,有机会踩到这个坑。
然后,下面几位大佬基于这个问题给出了很多解决方案,并针对各种解决方案进行讨论。
有的解决方案,听起来就感觉很麻烦,需要编写很多的代码,我就不一一解读了。
最终,大道至简,还是选择了实现起来比较简单的 cache 方案,虽然这个方案也有一点瑕疵,但是出现的概率非常低且是可以接受的。

再看get方法
现在我们知道了这个没有卵用的知识点之后,我们再看看为什么调用带超时时间的 get() 方法,没有这个问题。
java.util.concurrent.CompletableFuture#get(long, java.util.concurrent.TimeUnit)
首先可以看到内部调用的方法都不一样了:

有超时时间的 get() 方法,内部调用的是 timedGet 方法,入参就是超时时间。
点进 timedGet 方法就知道为什么调用带超时时间的 get() 方法没有问题了:
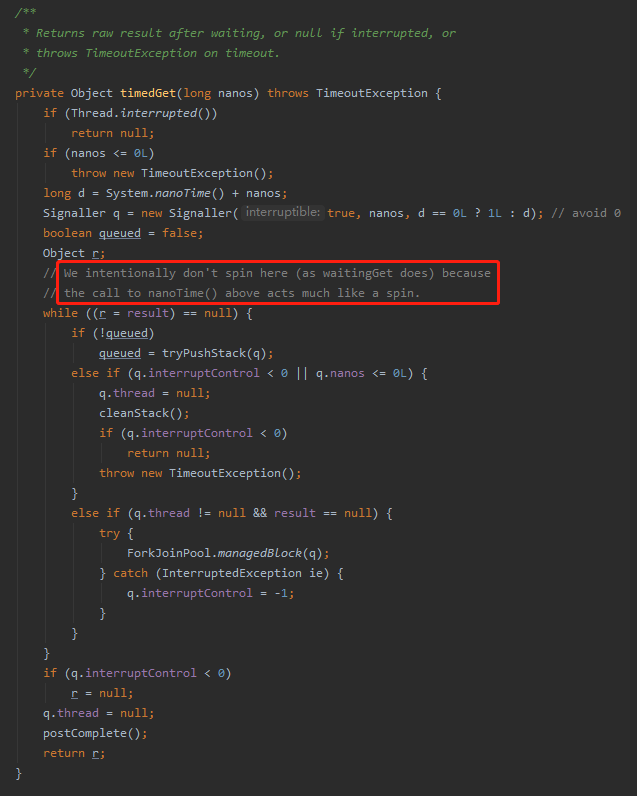
在代码的注释里面已经把答案给你写好了:我们故意不在这里旋转(像waitingGet那样),因为上面对 nanoTime() 的调用很像一个旋转。
可以看到在该方法内部,根本就没有对 Runtime.availableProcessors 的调用,所以也就不存在对应的问题。
现在,我们回到最开始的地方:
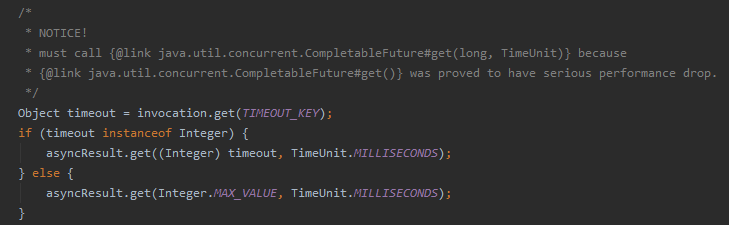
那么你说,下面的 asyncResult.get(Integer.MAX_VALUE, TimeUnit.MILLISECONDS) 如果我们改成 asyncResult.get() 效果还是一样的吗?
肯定是不一样的。
再说一次:Dubbo 作为开源的中间件,有可能会运行在各种不同的 JDK 版本中,且该方法是它主链路上的核心代码,对于特定的 JDK 版本来说,这个优化确实是对于性能的提升有很大的帮助。
所以写中间件还是有点意思哈。
最后,再送你一个为 Dubbo 提交源码的机会。
在其下面的这个类中:
org.apache.dubbo.rpc.AsyncRpcResult
还是存在这两个方法:
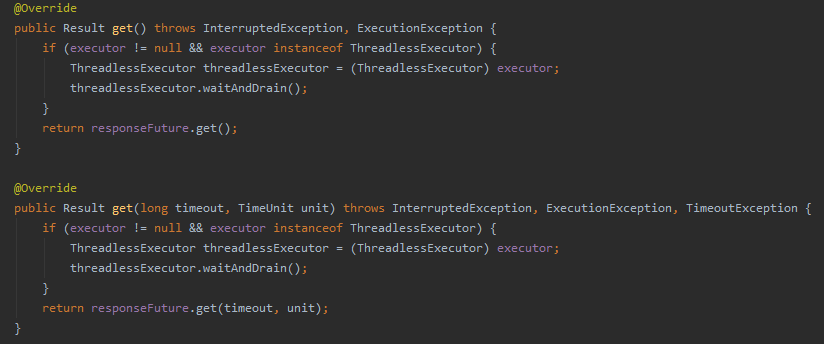
但是上面的 get() 方法只有测试类在调用了:
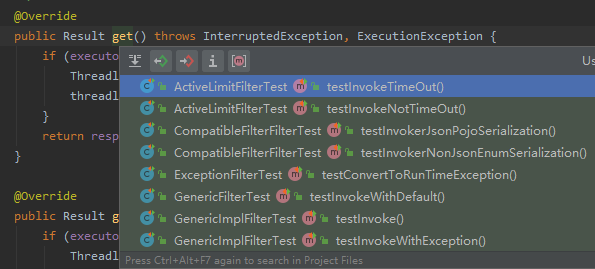
完全可以把它们全部改掉调用 get(long timeout, TimeUnit unit) 方法,然后把 get() 方法直接删除了。
我觉得肯定是能被 merge 的。
如果你想为开源项目做贡献,熟悉一下流程,那么这是一个不错的小机会。
被 merge 后你就可以去吹牛了,毕竟是为 Apache 顶级开源项目贡献过源码的人,说话音调都可以加高点。

好了,本文的技术部分就到这里啦。
下面这个环节叫做[荒腔走板],技术文章后面我偶尔会记录、分享点生活相关的事情,和技术毫无关系。我知道看起来很突兀,但是我喜欢,因为这是一个普通博主的生活气息。
你要不喜欢,退出之前记得文末点个“在看”哦。
荒腔走板

国庆节期间我去看了《长津湖》,实话实话电影是三个导演执导,有些地方拍的还是很有割裂感的。
但是瑕不掩瑜,算得上是一部国产佳片。
与我个人而言,还是非常有教育意义的。
所有和我一样的年轻人都知道抗美援朝战争,知道唇亡齿寒的道理、知道鸭绿江、知道三八线、知道上甘岭、知道黄继光...
但是在这之前,我不知道长津湖战役,我是通过这部电影才了解到了如此悲壮的、伟大的战役。
而之后,我想我永远也不会忘记:长津湖战役,志愿军第 9 兵团此役战斗伤亡 19202 人,冻伤 28954 人,冻死 4000 余人。
看《长津湖》的时候我就在想,肯定会出现《我的祖国》的 BGM。
我听不得这首歌,每次听到的时候都会有一种热泪盈眶的感觉。
果然,在雷爹牺牲之前,响起了非常短暂且小声的《我的祖国》的 BGM,即使它那么小声,却还是被我捕捉到了。
随之替代的 BGM 是雷爹唱的他家乡的歌《沂蒙山小调》。
彼时,坐在旁边的女朋友已经泣不成声。
雷爹说:别把我一个人留在这。
让我想起了前段时间的新闻,接在朝鲜战场上牺牲的革命烈士回家的重大意义。
看完《长津湖》之后,我又去 B 站看了纪录片《冰血长津湖》,更加的真实和震撼,推荐给你。
人民英雄,永垂不朽。
最后说一句
好了,看到了这里了,转发、在看、点赞随便安排一个吧,要是你都安排上我也不介意。写文章很累的,需要一点正反馈。
给各位读者朋友们磕一个了:

本文已收录自个人博客,欢迎大家来玩。点击[阅读原文]即可直达。
https://www.whywhy.vip/