
【论文分享】 作者带你读CVPR2020-MSFSR
[GaintPandaCV导语] 今天带来我自己的一篇CVPR2020论文,这篇论文主要针对于大放大倍率情况下人脸超分辨率网络出现的性能衰减问题进行思考。现有的人脸超分辨率方法尤其是基于结构先验知识的人脸超分辨率算法出现性能衰减原因在于:
1、极低分辨率尺度下,难以直接建模高质量的人脸结构信息;
2、单阶段人脸超分辨率重建方法,难以一步到位直接生成高保真的人脸图像。
本文则针对上述问题,从人脸结构信息建模层面和网络结构层面进行了探究。从人脸结构信息建模层面:采用人脸边缘线对低分辨率人脸结构先验知识进行;从网络结构层面,采用渐进放大的设计,在不同阶段施加不同粒度的人脸结构先验知识,逐级重建人脸图像。
论文链接:https://openaccess.thecvf.com/content_CVPRW_2020/html/w31/Zhang_MSFSR_A_Multi-Stage_Face_Super-Resolution_With_Accurate_Facial_Representation_via_CVPRW_2020_paper.html
0. 视频简介
这里可能大家不一定都阅读完,可以先看一下我Virtual Meeting时做的介绍视频,一分钟了解这篇论文。
1. 前言
这篇文章主要聚焦的是解决大放大倍率(如8倍放大、16倍放大乃至更高)人脸超分辨率(FSR)任务中算法存在的性能下降问题。这篇文章是在Tai Ying等人CVPR2018 Spotlight论文:FSRNet[1]上的进一步思考。FSRNet是基于结构先验知识的人脸超分辨率算法的经典之作。它首次提出采用双分支网络结构,通过常规图像超分辨率放大分支和人脸先验提取分支,从低分辨率图像中挖掘不同层次的特征,帮助网络进行超分辨率放大。通过显式引入外部人脸结构先验知识(人脸解析图和人脸关键点),不仅提升了输出高分辨率人脸图像的分辨率;而且也不需要对人脸图像进行复杂的预对齐工作。受益于上述优点,FSRNet在一段时间内成为基于结构先验知识的FSR算法中最出色的一种。
但是FSRNet存在以下缺点:公开人脸数据集中几乎没有提供高质量的人脸解析图,而人脸解析图的标注是昂贵且复杂的,这使得这类方法的研究变得非常困难;尽管我们可以采用公开数据集中普遍提供的人脸关键点作为外部人脸结构先验知识,但是何种密度的人脸关键点能够最大化FSR网络的重建性能也是未知的。
本文给出的解决方案:采用人脸边缘线作为人脸结构表示方式,一方面能够以极低成本扩充人脸数据集规模;另一方面摆脱了关键点密度的约束,直接用轮廓线代替点。
2. 人脸边缘线
在人脸对齐领域,来自清华大学和商汤科技的Wayne Wu等人首次“人脸边缘线”的概念[2],旨在解决人脸对齐任务中各个人脸数据集之间定义不一致的问题。通过建立“人脸边缘线”这一中间表示方式,实现不同数据集之间的关键点的相互转换。
而本文认为,人脸边缘线不仅仅只是一种中间表示方式,其本身就对于人脸几何结构进行了建模,是一种良好的人脸结构表示方式。
一方面,由于边缘线的连续性,无论人脸关键点定义密度如何,表示同一五官特征的关键点都会落在11条人脸边缘线上。此时我们就将一个复杂的预测各个数据集不同人脸关键点的任务转换为了一个相对简单的预测人脸边缘线的任务。
另一方面,人脸边缘线本文就是对人脸结构的一种较为完备的建模。其相较于人脸关键点,包含了更完整的人脸结构信息;相较于人脸解析图,对于五官内部的结构特征(如鼻翼)有更精确的刻画。
本文在Wu等人的“人脸边缘线”的基础上,针对于低分辨率人脸图像的特点,本文对原始的13条人脸边缘线进行了定义的简化,将描述上下眼睑的边缘线合并成了一个完整的闭合回路。本文采用的人脸边缘线定义如下:
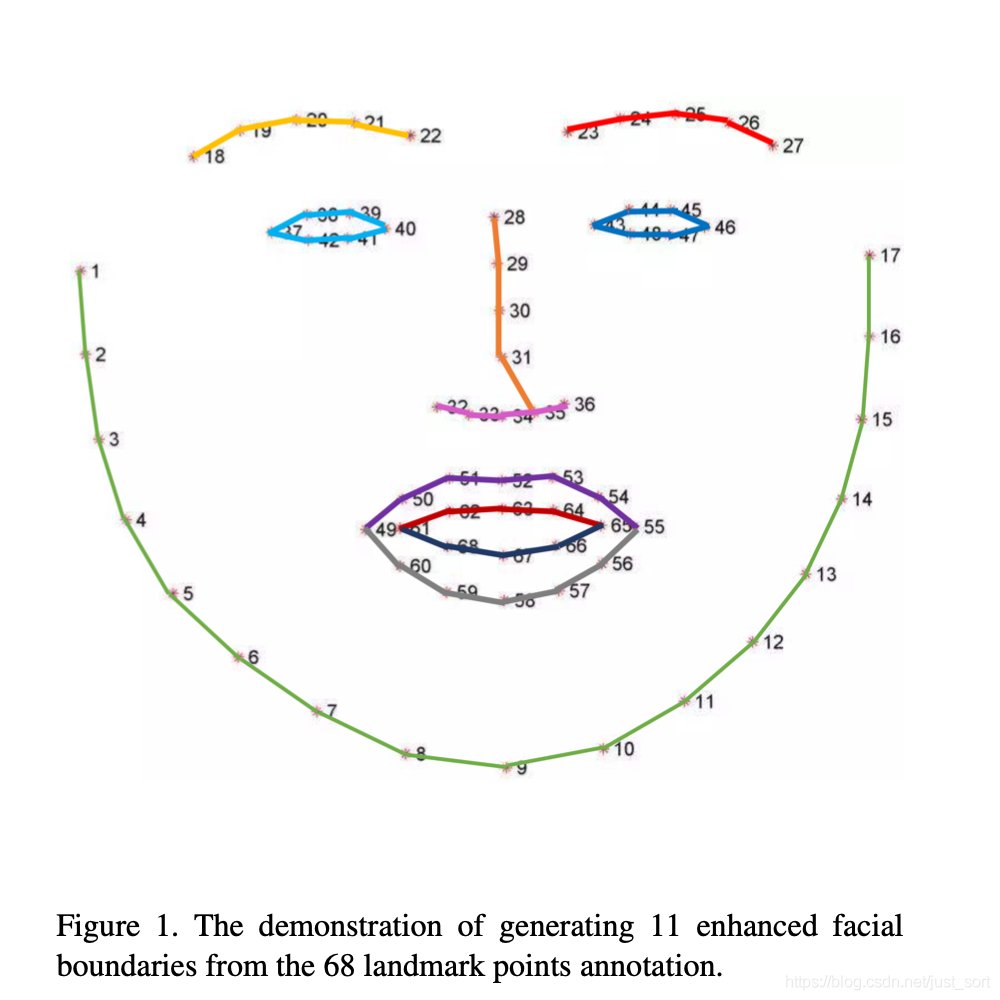
给定一张人脸图片,给出适当密度的L个人脸关键点标注
将S个人脸关键点(本文选取了68个人脸关键点)划分为N个子集合(11条人脸边缘线),并且将每一个子集合内部的关键点按照语义顺序顺次链接,得到二值化图表示的人脸边缘线;
根据二值化人脸边缘线以及标准差为sigma的高斯表达式将人脸边缘线转化为人脸边缘线热力图。
具体的人脸边缘线的生成过程可以参考论文、补充材料,以及对应的相关代码(放心,我把这一块开源在https://github.com/cydiachen/MSFSR/)
3. 重思考FSR网络结构
在有了更优的人脸结构化表示方法之后,我们进一步重思考了人脸超分辨率网络的结构设计。现有的双分支网络设计通过额外分支显式地引入人脸结构先验信息,这种结构不仅直观且有效。但是,双分支网络内部本身耦合较紧密,很难通过对每部分单独优化实现整体的优化。
因此,我们对现有的FSR网络结构进行了重思考,采用三大模块作为基本组件,通过灵活的连接,组成一个完整的FSR网络。
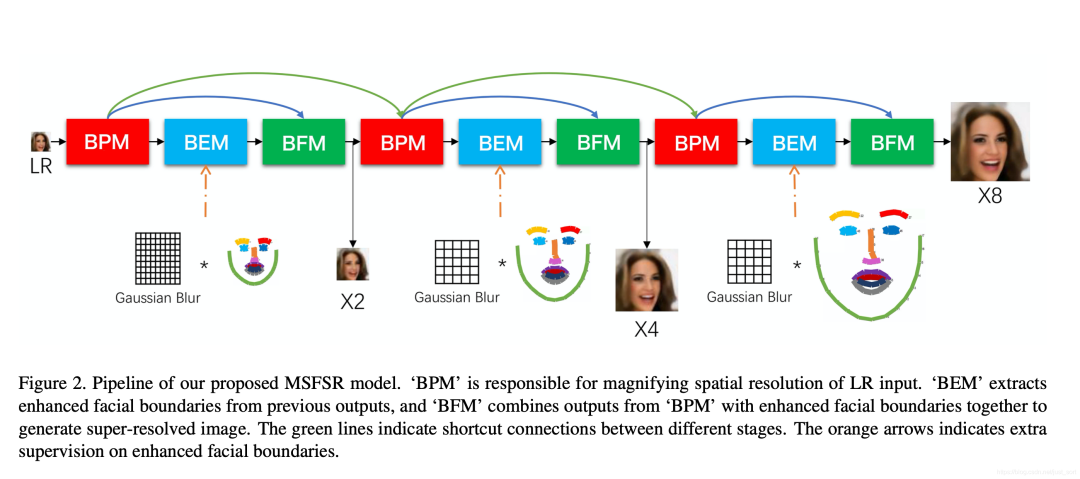
三大基础模块按照功能进行划分:基础上采样模块(Basic Upscale Module,BUM),边缘预测模块(Boundary Estimation Module,BEM),边缘融合模块(Boundary Fusion Module,BFM)。
其中,基础上采样模块将输入的低分辨率图片进行了尺度放大。这里的基础上采样模块可以被替换为任意通用图像超分辨率算法,这样FSR算法就能够充分受益于通用图像超分辨率算法的进化。
边缘预测模块则是采用漏斗结构,将经过了基础上采样模块后的大尺寸图像中人脸边缘线的可能位置进行预测。而边缘融合模块则是将大尺寸图像中的特征信息和边缘预测模块中的人脸边缘线信息进行加权融合,用以最终生成人脸图像。
本文的网络设计中:
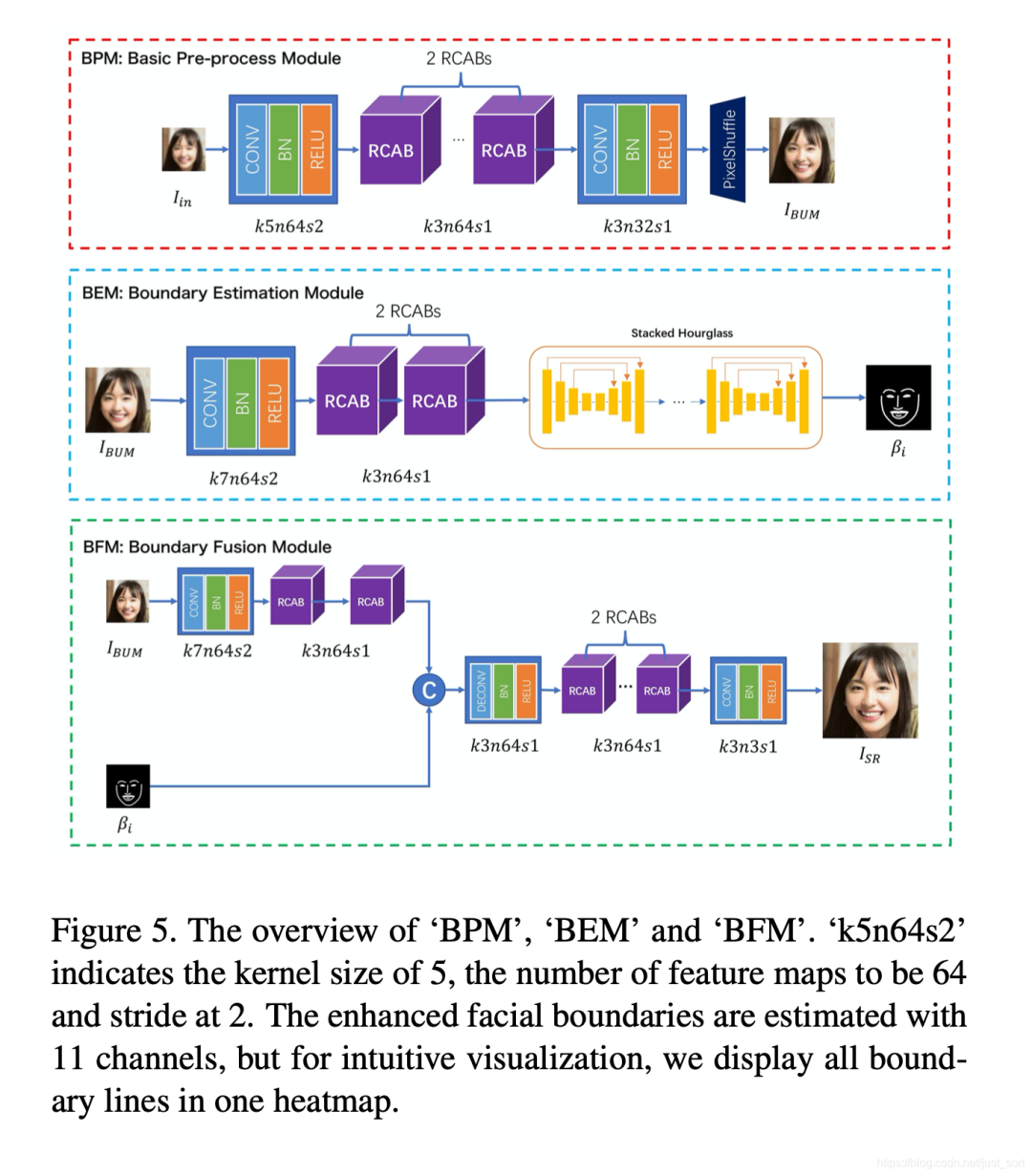
基础上采样模块引入了通道注意力机制以及后置上采样模块的亚像素卷积层,以较低的计算量实现了图像的高效放大;
边缘融合模块则同样通过通道注意力机制,通过对融合后的特征图同样引入通道注意力机制实现了通道权重间的自适应调整,使网络根据最终的重建结果,动态调节不同特征图的融合比例,使网络充分利用不同通道中的信息。
具体的网络结构参照下图:
4. 多阶段FSR网络结构
本文进一步提出,现有的单阶段直接放大的FSR网络在处理超过8倍的上采样操作时,性能会出现明显的下降。正因为在上一步,我们将整个FSR网络的组成分解为了三个模块的组合与连接,我们可以灵活的将一个单阶段直接放大的网络改进为多阶段渐进放大的网络。
多阶段的FSR网络不单单是简单的将模块进行级联链接,同时还需要考虑到不同阶段网络处理的任务难度的差异。
在网络的初始阶段,图像的分辨率较小,边缘预测模块预测精确的人脸边缘线的难度较大,因此直接施加细粒度的人脸边缘线会导致网络难以收敛;伴随着网络的深度增加,图像的尺寸也逐级增大,此时我们需要逐渐的约束人脸边缘线的粒度,从粗粒度的边缘线变为细粒度的人脸边缘线,进一步约束网络进行图像的”精修“。
本文网络设计了一个从粗到细的边缘线监督机制,通过人脸边缘线粒度进行数值控制,探究了不同阶段人脸边缘线的最佳设置,充分提升了多阶段网络的性能。
同时,在多阶段网络重建过程中,我们还尝试了在网络的不同阶段直接使用生成对抗网络结构来逐级优化各个阶段的输出结果。但是,试验效果不如人意。
主要原因在于:网络的前期阶段,图像的分辨率尺寸较小,直接采用生成对抗网络会给重建的图像引入过大的额外噪声,不利于下一级网络的重建。因此,我们只在多阶段网络的最后一个阶段引入生成对抗网络结构,生成更加逼真的人脸图像。
5. 消融实验
我们进行了若干实验验证了前述提出的假设:
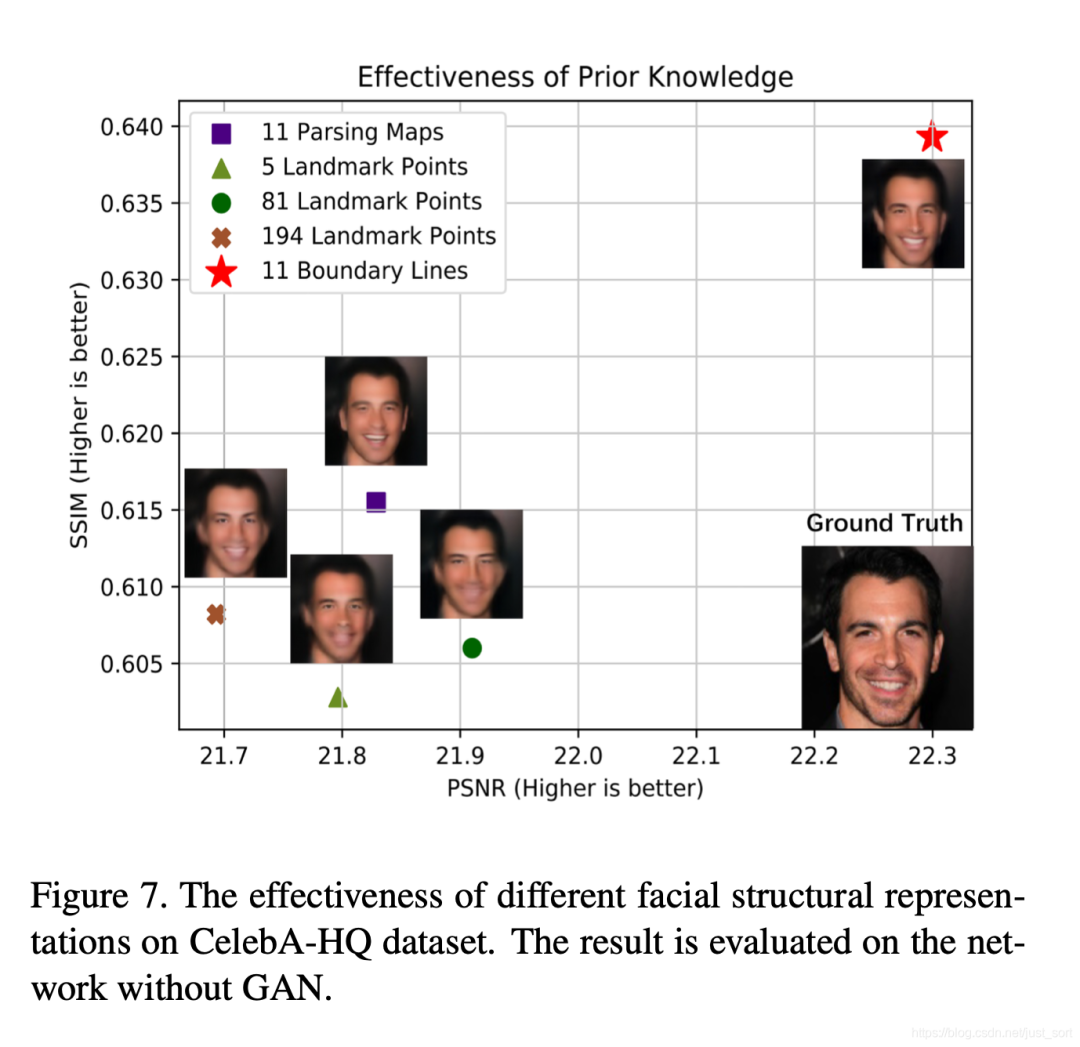
我们首先进行了人脸边缘线有效性试验,在相同的试验设置下,我们对人脸边缘线、人脸解析图和不同标注密度的人脸关键点进行了试验比较。试验结果如图所示。
从结果中体现了一些有趣的结论:
横向对比5个人脸关键点的FSR算法结果和81个人脸关键点的FSR算法结果,可以看出:当人脸关键点的数目增加,FSR网络的性能逐步提升。进一步对比人脸关键点和人脸解析图作为人脸结构先验知识的FSR算法,验证了引入的外部人脸表示所携带的人脸结构语义信息越多,FSR网络的性能越好。
横向对比81个人脸关键点和194个人脸关键点的FSR网络的性能表现,本文发现:更加密集的人脸关键点信息并不能有效提升FSR算法的性能。
笔者认为主要原因可能有两点:
i)输入人脸图像的分辨率低,进行人脸关键点检测时,大量的点会产生漂移,为网络的训练引入了过多的误差;
ii)FSR网络设计时,网络的容量限制,导致进行先验预测的模块无法抽象出密集的关键点表示,因此造成了网络的性能下降。
而我们的人脸边缘线则通过引入了线的连续性,不仅包含了尽可能多的人脸关键点信息,而且对人脸结构信息的描述也更加完备。自然而然,引入了人脸边缘线的FSR网络的重建效果大幅度领先。

同时,我们还对从粗到细的监督机制有效性进行了试验验证。从表中可以看出:在网络的初始阶段,采用更粗粒度的人脸边缘线能够有效提升网络的重建效果;伴随网络重建的图像分辨率尺度渐进增大,人脸边缘线的粒度也应该变得愈加精细。
6. 与其他方法比较
我们将我们的方法与近两年的其他网络进行了比较。为了全面展示我们算法的性能,我们选取了【通用图像超分辨率算法】EDSR[3], EnhanceNet[4], ESRGAN[5];【FSR算法】URDGN[6], FSRNet[1], PFSR[7]作为比较。


这里我简单对于几个客观指标进行一下简单介绍:几个客观评价指标中,PSNR,SSIM指标都是越高越好;PI(Perception Index)指标是越低越好。从结果中可以看出,我们的算法在客观指标上,也优于其他竞争对手。
同时,我们还首次在评估人脸图像重建效果的过程中采用了公开的人脸对比API(这里用的是旷场的Face++人脸对比API)。
我们的算法不仅在通用图像质量评估指标上领先,同时重建的图像与真实人脸图像的身份相似度也保持了极高的相似度,证明我们的算法在身份保真度上也遥遥领先。

7. 算法泛化性结果展示
我们在补充材料中还加入了我们算法泛化性结果的展示。这里,我们选择在CelebA-HQ数据集上训练的MSFSR算法,在WebFace数据集上展示了算法的重建效果。

8. 算法的Failure Cases
当然,我们的方法也并不全能,我们同样在补充材料中提供了我们算法重建效果不理想的结果。
我们其实从这些重建效果不理想的图片中,能够发现一些失败cases的共性:
本文的方法对于大偏转角度的人脸图像的重建效果不佳。这是未来方法可以努力的方向,也是人脸超分辨率一个难啃的硬骨头。
本文的方法在恢复婴儿人脸图像时,效果也不够好。这可能是和数据集中婴幼儿人脸的比例不均衡有关,婴幼儿人脸的几何结构特征还是与成年人存在差异的,因此对成年人效果较好的FSR算法可能在婴儿图像上性能表现就存在下降。

9. 总结
这次的总结想谈一谈我写文章时的一些心得体会。这篇文章之前BB就一直和我约稿,最近由于工作原因一直一拖再拖,终于完成了整篇介绍文章的工作。
其实很多人很好奇,怎么样才能够发表一篇优质的论文。其实我的经历很简单:首先,你需要大量阅读已有的顶会的论文,就和CNN一样,只有有了高质量的输入后,才能够有高质量的输出。其次,Coding能力在现阶段还是非常重要的。你会在顶会上看到一些非常优秀的工作,但是由于各种原因,作者没有提供完整的源代码,这时候你就需要自己对照着文章进行复现。
我的这篇文章的大部分改进思路都来源于我复现FSRNet论文时踩坑填坑的过程。更多的,还需要积极的和其他朋友(网友就很不错)一起交流分享。
在这里我也借这个机会感谢在我写论文过程中提了很多意见的好友,无论是最初带我打比赛的武大的丁新博士,去年暑期实习的同事,来自某独角兽的阿帆学长,港中文的浩哥,我的这篇文章的产出离不开你们各位的帮助。
当然未来,我们还有GiantPandaCV这个平台,通过分享论文解读,代码思路,希望大家能够一起交流,一起进步。
10. 参考文献
[1] Fsrnet: End-to-end learning face super-resolution with facial priors.
[2] Look at boundary: A boundary-aware face alignment algorithm.
[3] Enhanced deep residual networks for single image super-resolution.
[4] Enhancenet: Single image super-resolution through automated texture synthesis.
[5] Esrgan: Enhanced super-resolution generative adversarial networks.
[6] Ultra-resolving face images by discriminative generative networks.
[7] Progressive face super-resolution via attention to facial landmark.
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。