
保姆级教程!使用k3d实现K3s高可用!
你是否曾经想尝试使用K3s的高可用模式?但是苦于没有3个“备用节点”,或者没有设置相同数量的虚拟机所需的时间?那么k3d这个方案也许你十分需要噢!
如果你对k3d尚不了解,它的名字或许可以给你一个了解它的切入口:K3s in Docker。k3d是一个轻量级封装程序,用于在Docker中运行k3s。借助k3d,可以轻松在Docker内创建单节点或多节点的k3s集群,用于Kubernetes上的本地开发。
K3d允许你在短时间内启动k3s集群。此外,你可以快速学会其少量但十分有用的命令。K3d运行在Docker内,这意味着你可以扩展或减少节点而不需要进行多余的设置。在本文中,我们将介绍如何使用k3d设置单节点K3s集群以及如何使用k3d在高可用模式下设置k3s。
本文的两个主要目的是介绍k3d作为部署K3s集群的工具,以及展示K3s高可用性如何抵抗“节点退化(nodes degradation)”。而且,我们还将了解k3s默认在集群中部署了哪些组件。
前期准备
在操作系统(Linux、MacOS、Windows)方面,大家都有自己的偏好。所以在我们检查用于本篇文章的设置之前,仅有两个必要的要求:Docker和Linux shell。
如果你使用的系统是MacOS或者Windows,Docker Desktop是Dcoker的首选解决方案。对于Linux来说,你可以获取Docker engine以及CLIs,详细信息如下:
https://www.docker.com/products/docker-desktop
Linux shell、MacOS以及Linux都会有所涉及。对于Windows系统而言,最简单快捷的解决方案是WSL2,我们也会在demo中用到它。
以下是我们将会用到的设置:
OS:Windows 10 version 2004(build:19041)
OS 组件:虚拟化机器平台以及Linux的Windows子系统
安装步骤:
https://docs.microsoft.com/en-us/windows/wsl/install-win10
WLS2发行版:Ubuntu
Windows商店地址:
https://www.microsoft.com/en-us/p/ubuntu/9nblggh4msv6#activetab=pivot:overviewtab
【可选】使用的控制台:Windows Terminal
Windows商店地址:
https://www.microsoft.com/en-us/p/windows-terminal/9n0dx20hk701
Step1:从安装开始
访问下方链接即可了解如何安装k3d:
https://k3d.io/#installation
在本文中,我们将以curl的方式安装。
请注意:直接从URL运行脚本存在很严重的安全问题。所以在运行任意脚本之前,确保源是项目的网站或git在线repository。
以下是安装步骤:
访问:https://k3d.io/#installation
复制“curl“安装命令并且在你的terminal内运行它:
curl -s https://raw.githubusercontent.com/rancher/k3d/main/install.sh | bash
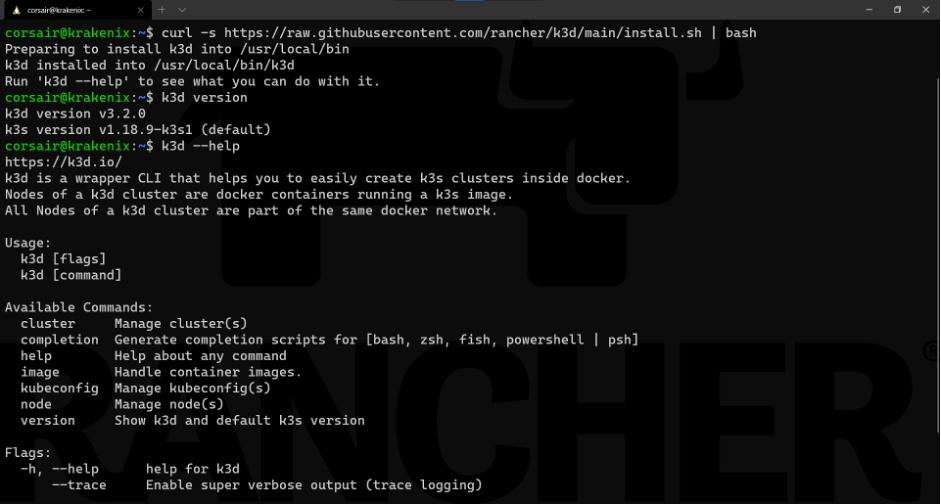
请注意:该截图显示了两个命令:
k3d version:提供已安装的k3d版本
k3d –help:列出可用于k3d的命令
现在k3d已经安装完成并且准备开始使用。
Step2:从单节点集群开始
在我们创建一个HA集群之前,让我们从单节点集群开始以理解命令(“grammar”)并且查看默认情况下k3d部署了什么。
首先,语法。在V3,k3d在命令的使用方式上做了很大的改变。我们不深入研究以前的命令是怎么做的,我们将使用V3的语法。
K3s遵循“名词+动词”的句法。首先指定我们要使用的东西(集群或节点),然后指定我们要应用的操作(create、delete、start、stop)。
创建一个单节点集群
我们将借助k3d使用默认值创建一个单节点集群:
k3d cluster create
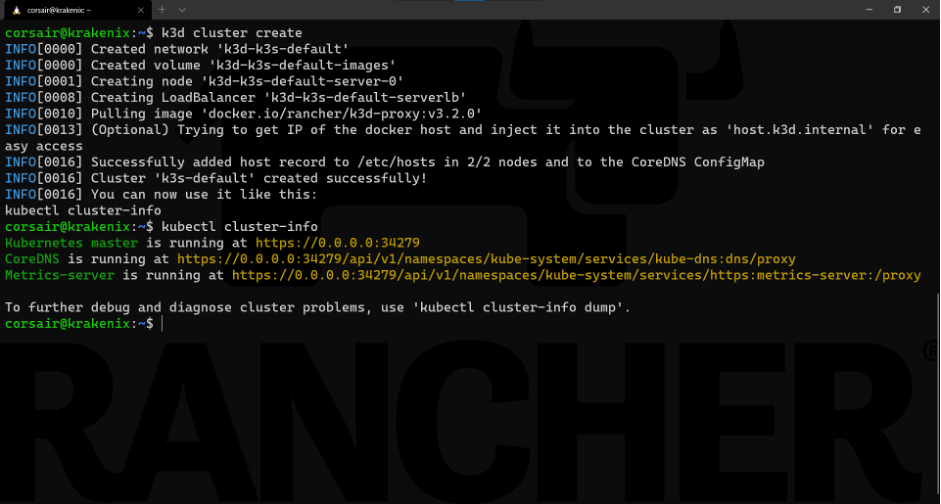
请注意:k3d cluster create命令的输出建议运行另一条命令来检查集群是否在运行并且可以访问:kubectl cluster-info
现在集群已经启动并且在运行啦!
窥视内部结构
我们还可以从不同的角度看看到底部署了什么。
让我们从头开始,看看K3s集群里面有什么(pods、服务、部署等):
kubectl get all --all-namespaces
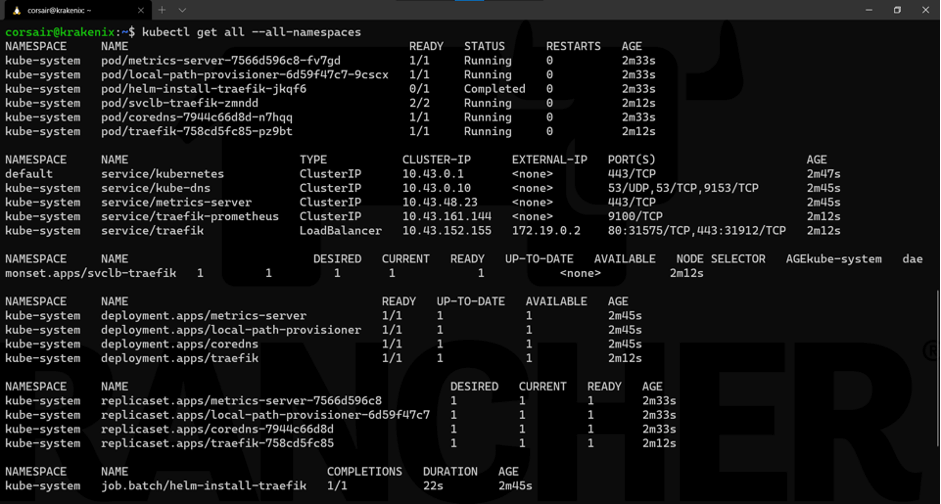
我们可以看到,除了Kubernetes服务外,当我们使用默认值时,K3s还部署了DNS、metrics和ingress(traefik)服务。
现在让我们从不同的视角查看节点。
首先,我们从集群的视角检查它:
kubectl get nodes --output wide
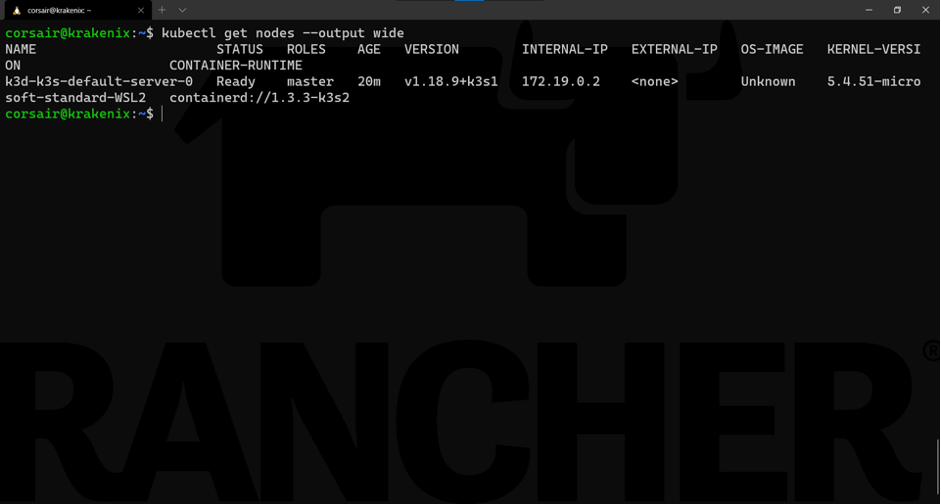
如我们所料,仅看到了一个节点。现在让我们从k3d的视角查看:
k3d node list
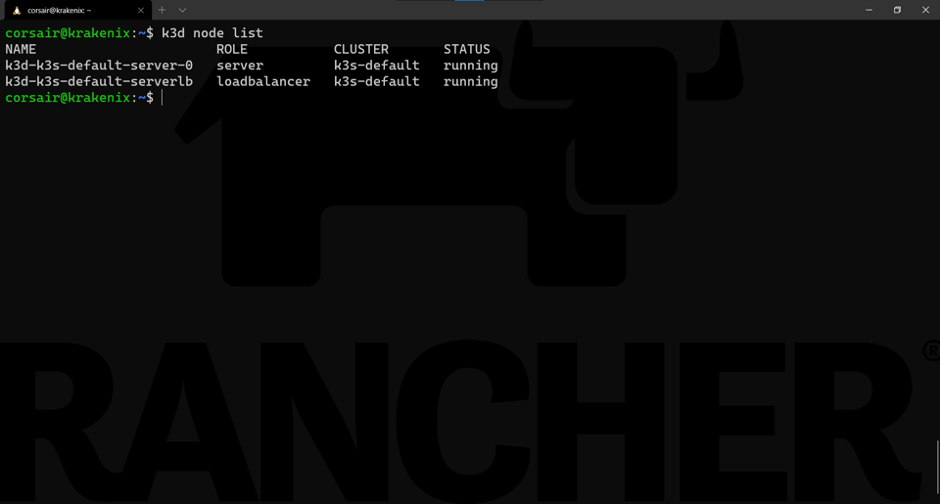
现在我们有两个节点。这里有一个比较智能的实现是,当集群运行在它的节点k3d-k3s-default-server-0上时,有另一个“节点”作为负载均衡器。虽然这可能对单节点集群没有太大作用,但在我们的HA集群中,它将为我们节省很多精力。
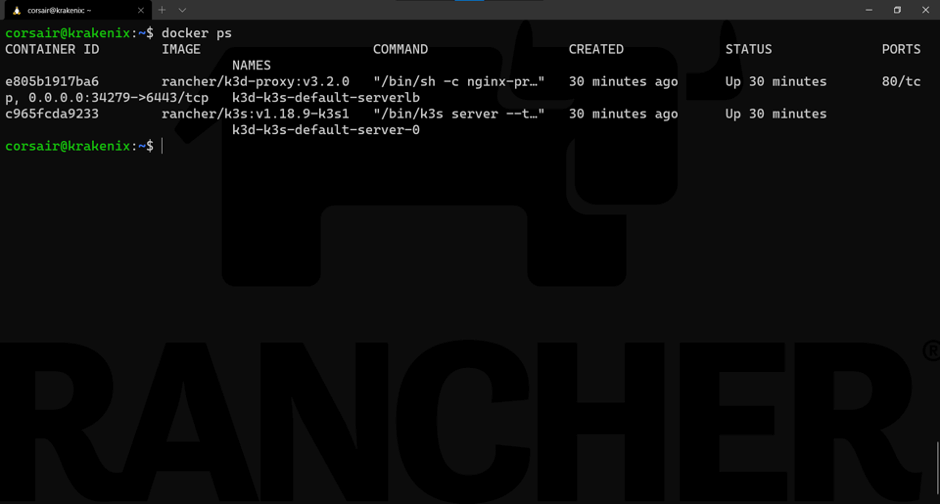
最后,我们从Docker看到两个节点:docker ps
清理资源
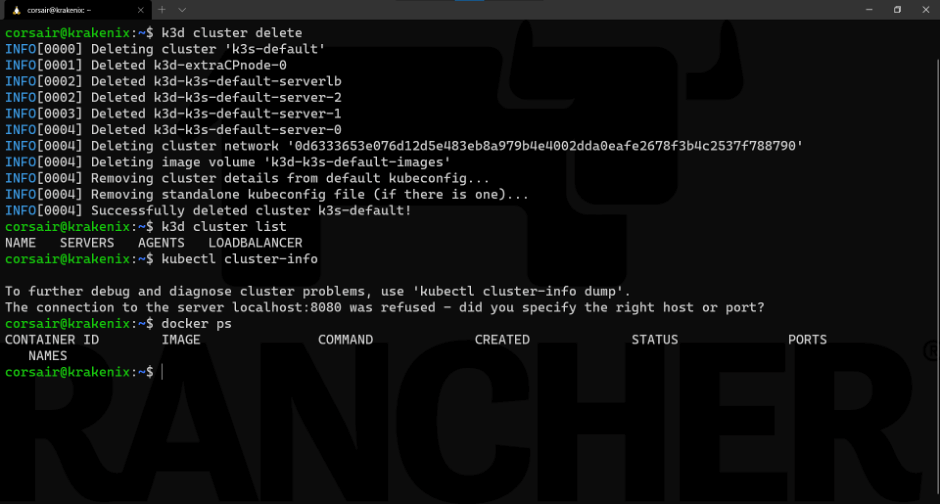
我们的单节点集群可以帮助我们理解k3d的机制和命令。现在,我们需要在部署HA集群之前清理资源:k3d cluster delete
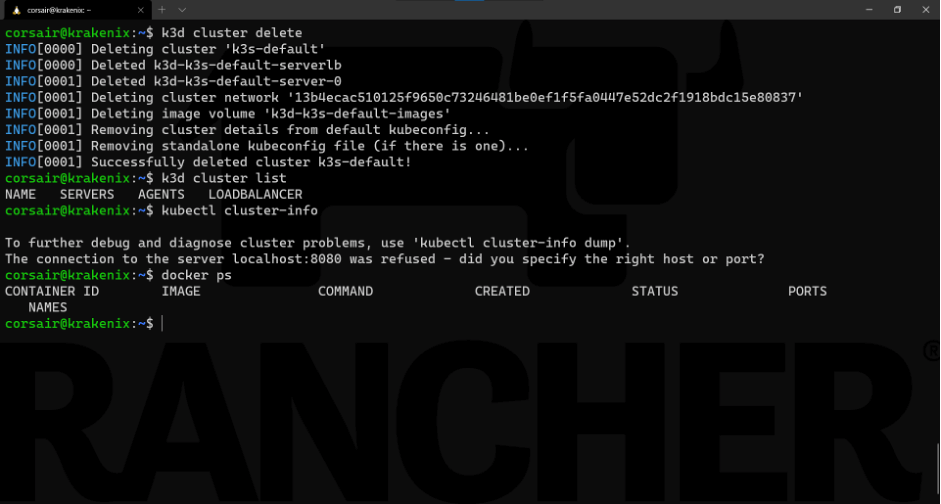
请注意:出于demo的目的,我们在上方截图中添加了以下命令:
k3d cluster list:列出活跃的k3d集群
kubectl cluster-info:检查集群的连接
docker ps:检查活跃的容器
现在,我们已经使用k3d创建、检查并删除了一个单节点集群。下一步,我们开始尝试HA。
Step3:欢迎来到HA的世界
在我们开启命令行之前,让我们对我们即将要部署的东西有一个基本的了解并且了解一些其他额外的要求。
首先,Kubernetes HA有两个可能的设置:嵌入式或外部数据库。我们将采用嵌入式数据库的设置。
其次,K3s有两种不同的技术用于嵌入式数据库的HA:一种是基于dqlite(K3s v1.18),另一种是基于etcd(K3s v1.19+)。
这意味着etcd是当前K3s稳定版中的默认版本,也是本文将使用的版本。Dqlite已经弃用。
在撰写本文时,k3d默认使用k3s v1.18.9-k3s1的版本。你可以通过k3d version来检查:

那么这是否意味着我们需要重新安装支持K3s v1.19的k3d吗?当然不需要!
我们可以使用当前已经安装的k3d版本并且依旧支持K3s v1.19,因为:
k3d可以让我们指定一个特定的k3s docker镜像来使用
所有的k3s版本都是以容器镜像的形式发布的
基于以上原因,我们可以假设一个K3s v1.19作为一个容器镜像存储在Docker Hub中:
https://hub.docker.com/r/rancher/k3s/tags?page=1&name=v1.19
现在,让我们用k3d创建第一个K3s HA集群。
三个控制平面
根据Kubernetes HA的最佳实践,我们应该使用至少3个控制平面来创建一个HA集群。
在k3d中我们使用以下命令即可:
k3d cluster create --servers 3 --image rancher/k3s:v1.19.3-k3s2
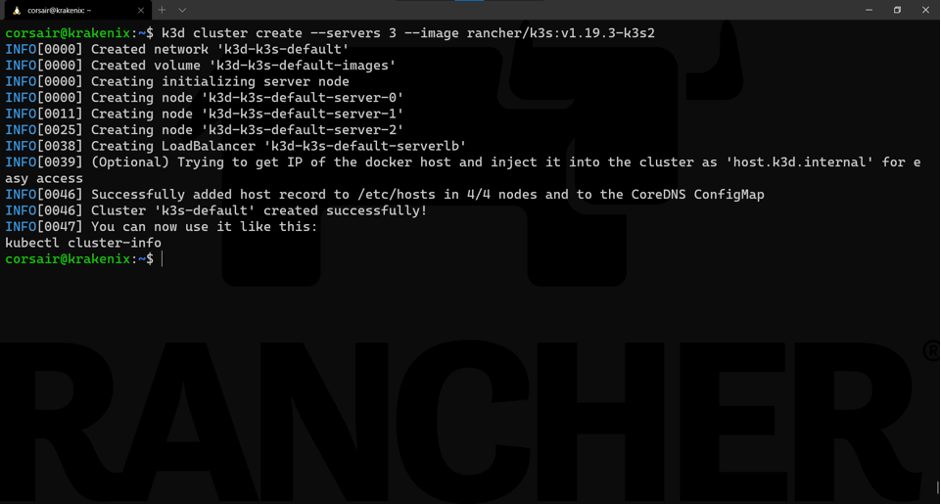
了解命令:
基础命令:k3d cluster create
选项:
-server 3:请求用角色服务器创建三个节点。
-image rancher/k3s:v1.19.3-k3s2:指定要使用的K3S镜像
现在我们可以从不同的角度检查我们已经创建的集群:
kubectl get nodes --output wide
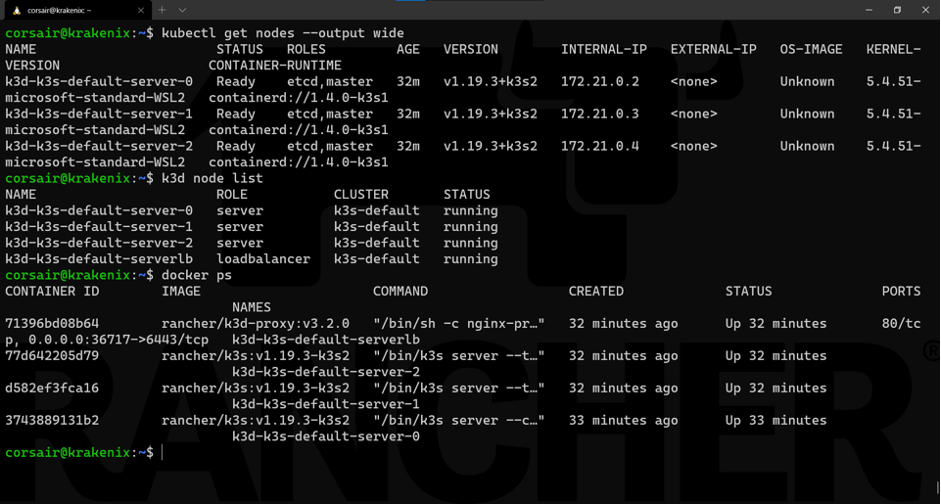
如你所见,我们从不同方面进行检查以确保我们的节点正常运行。
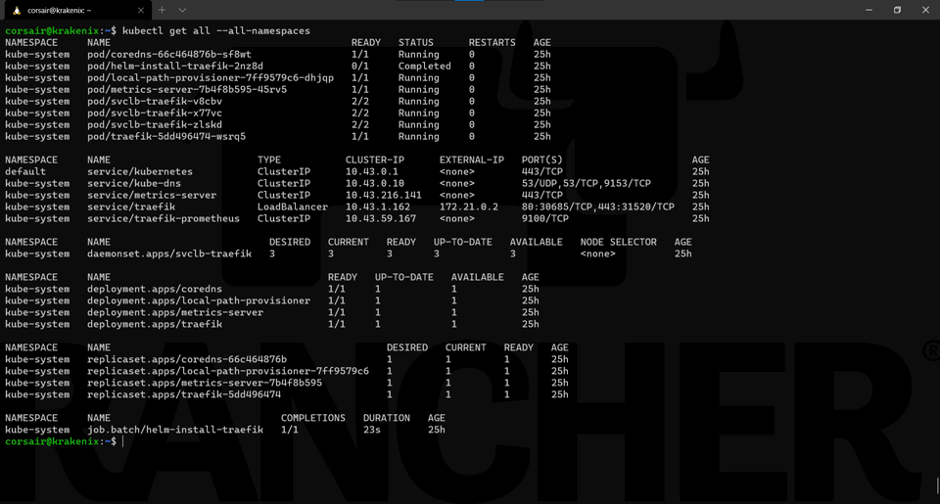
如果我们看到组件已经部署完成,那么我们的daemonset现在有3个副本,而不是1个:
kubectl get all --all-namespaces
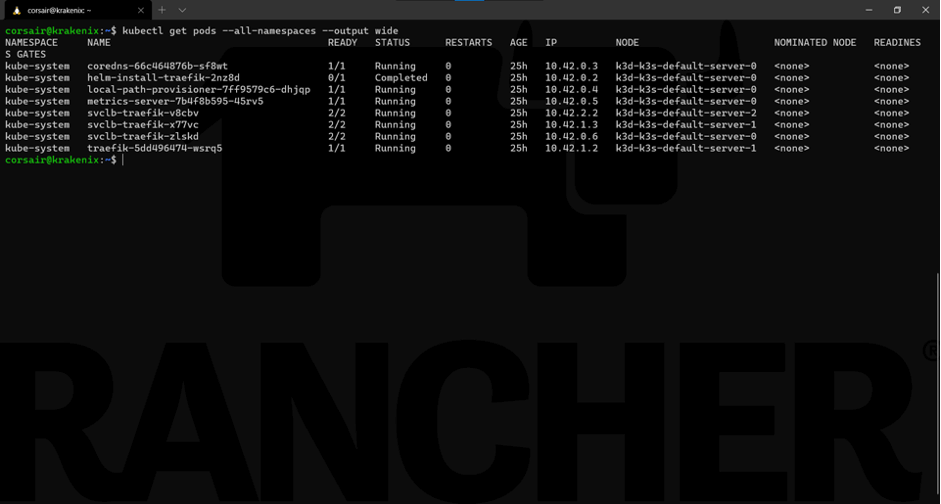
最后一项检查是看pods在哪个节点上运行:
kubectl get podes --all-namespaces --output wide
现在我们有了HA集群的基础。让我们添加额外的控制平面节点,并故意对其进行破坏,看看集群的表现。
扩展集群
由于k3d以及我们的集群运行在顶部容器的事实,我们可以快速模拟在HA集群中增加另一个控制平面节点:
k3d node create extraCPnode --role=server --image=rancher/k3s:v1.19.3-k3s2
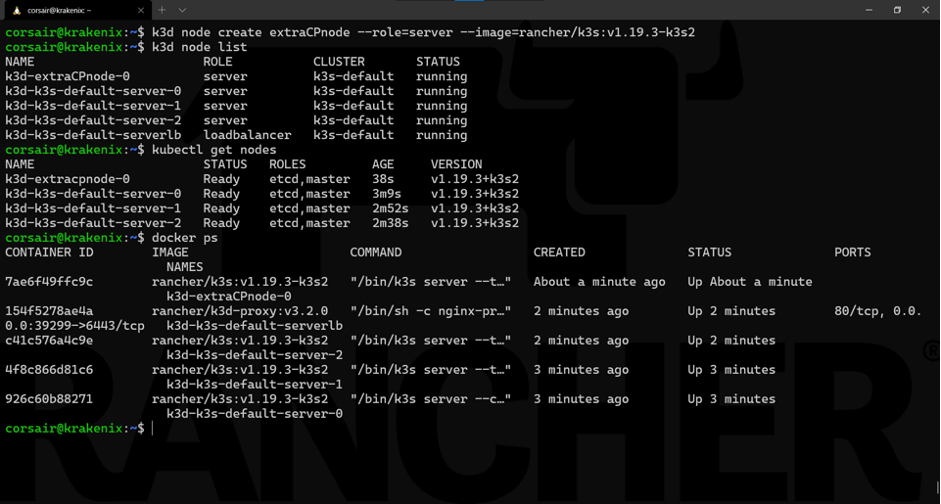
了解命令:
基础命令:k3d node create
选项:
extraCPnode:k3d用于创建最终节点名称的基本名称。
role=server:设置节点的角色为控制平面。
image rancher/k3s:v1.19.3-k3s2:指定要使用的K3s镜像。
从这里可以看出,我们从不同的角度进行检查以确保新的控制平面节点正常运行。
增加了这个额外的节点之后,我们就可以进行最后的测试了:降低node0!
HA:重型装甲防撞车
node0通常是我们的KUBECONFIG所指的节点(用IP或主机名表示),因此我们的kubectl应用程序试图连接到它来运行不同的命令。
由于我们正在使用容器,所以“破坏“一个节点的最好方法是直接停止容器。
docker stop k3d-k3s-default-server-0
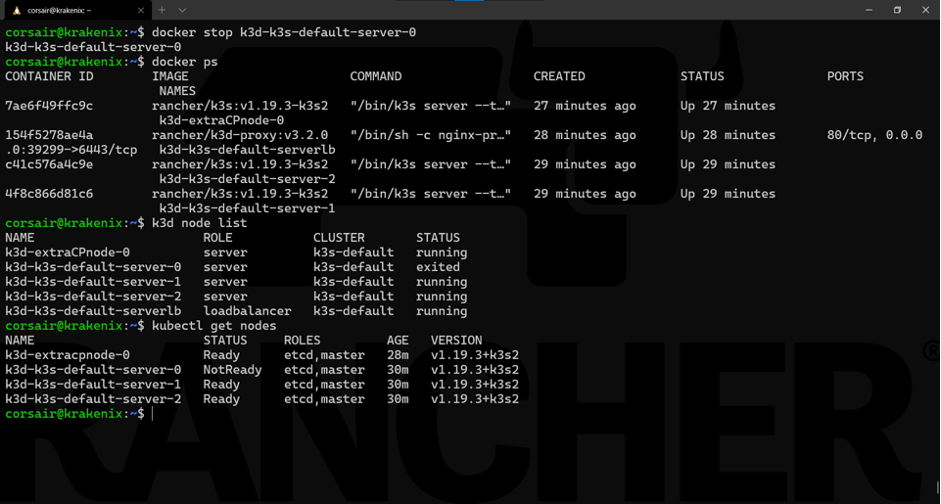
请注意:Docker和k3d命令会立即显示状态变化。然而,Kubernetes集群需要很短的时间才能看到状态变化为NotReady。
此外,我们的集群仍然使用Kubectl响应我们的命令。
现在是时候再次参考负载均衡器k3d所用的时间,以及它对于让我们继续访问K3s集群的重要性。
从外部连接的角度来看,虽然负载均衡器内部切换到了下一个可用节点,但我们仍使用相同的IP/主机。这种抽象为我们节省了很多经理,并且这是k3d最有用的功能之一。
让我们看一下集群的状态:
kubectl get all --all-namespaces
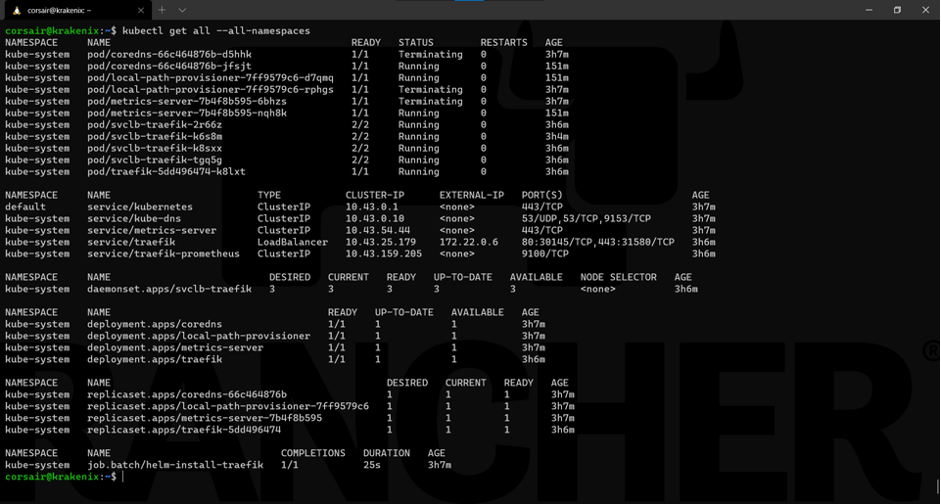
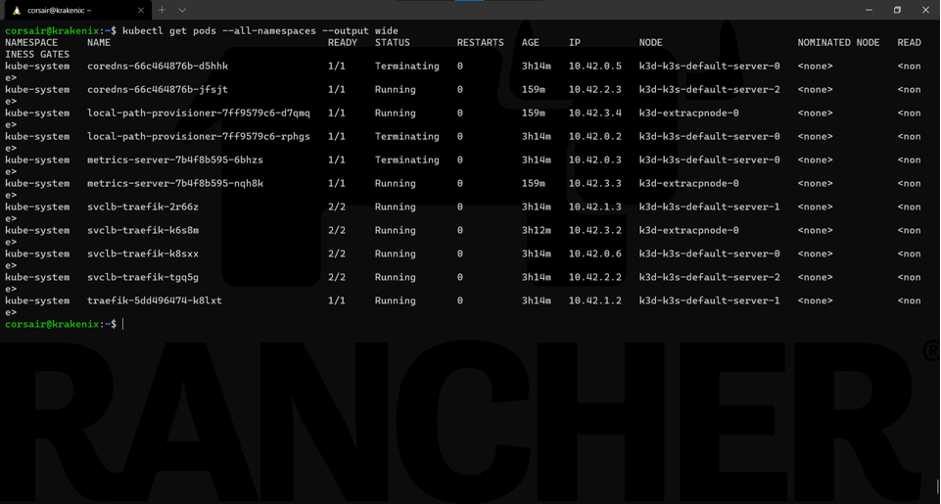
一切看起来正常。如果我们再具体看一下Pods,那么我们会发现,K3s通过在其他节点上重新创建运行在故障节点上的pods来自动自愈:
kubectl get pods --all-namespaces --output wide
最终,为了展示HA的强大以及k3s如何管理它,让我们重启node0,然后我们会看到它被重新纳入集群,好像什么都没有发生。
docker start k3d-k3s-default-server-0
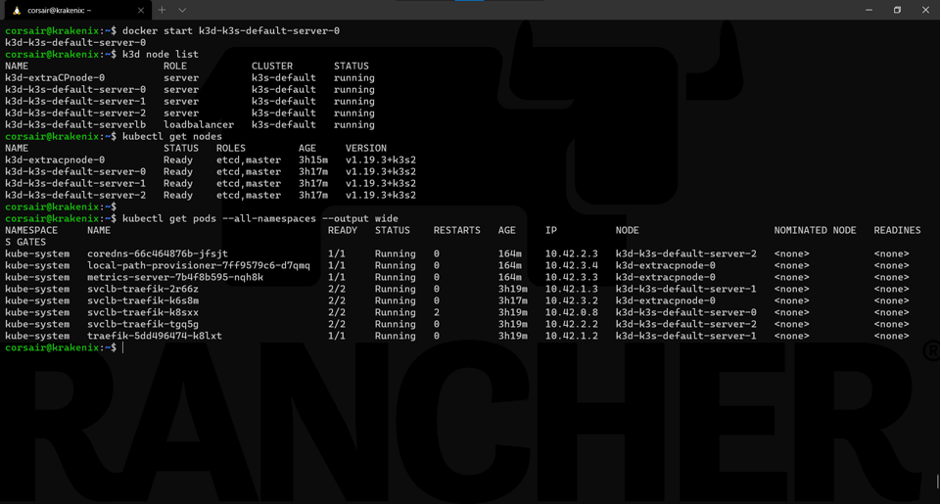
我们的集群是稳定的并且所有节点都再次正常运行。
再次清理资源
现在我们可以删除本地HA集群,因为它已经完成了它的使命。此外,我们知道我们可以轻松创建一个新的集群。
使用以下命令即可清理我们的HA集群:
k3d cluster delete
总 结
虽然我们在本地、容器中创建了单节点和HA集群,我们仍然可以看到K3s在新的etcd嵌入式DB下的表现,如果我们在裸机或虚拟机上部署K3s,其作用方式相同。
也就是说,k3d在管理方面帮助很大。它默认创建了一个负载均衡器,允许永久连接到K3s集群,同时抽象了所有的任务。如果它部署在容器外,我们需要手动完成这一步骤。
在本文中,我们已经看到了使用k3d设置高可用性K3s集群是多么容易。如果你尚未尝试,强烈推荐你根据本教程进行实践,它们都是开源且易用的。
推荐阅读
扫码添加k3s中文社区助手
加入官方中文技术社区
官网:https://k3s.io