
TiCDC 解析 | TiCDC 应用场景解析
TiCDC 是一款通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,具有将数据还原到与上游任意 TSO 一致状态的能力,同时提供开放数据协议 (TiCDC Open Protocol),支持其他系统订阅数据变更。
TiCDC业务使用场景描述
(1)增量数据抽取需求
数仓ETL每天凌晨基于table(create_date or update_date)增量或者全量的数据抽取:
目前离线报表业务为了凌晨产出报表,数仓团队凌晨需要从我们核心的物料TiDB集群(70+节点)中抽取维度基本信息数据,这些多张维度的基本信息表都是大表(200亿/表,5T+/表),每天凌晨的数仓抽取任务会对全实例(20T)做全量抽取。导致凌晨CPU跑满/内存oom/网卡跑满等各种负载问题,并且平均1~2个月出现数仓抽取失败,从而影响离线报表的定时产出,导致广告主不能及时看到昨天广告的消费情况,最严重的后果就是由此产生的广告停止投放,影响广告收入;另外凌晨除了数仓还有其他的计算任务存在,这种全量的抽取也会对其他正常凌晨任务的执行造成影响;凌晨的各种报警,我们DBA来说也苦不堪言。所以使用TiCDC写入kafka这种增量数仓需求是我们紧要的需求。
(2)同城双集群热备
目前我们的核心tidb都放在同一个机房。如果机房孤岛或者其他灾害问题。业务无法及时恢复。TiDB集群的同城双中心需求是重要的需求。
我们想利用TiCDC做同城双集群数据同步,一是可以将部分不需要太实时的读取流量切到备用集群,来缓解主TIDB集群的读取压力。二是一旦核心机房有问题,备用集群就可以立即接管服务。
(3)流处理需求
之前业务就是用maxwell/canal等工具将MySQL的变更binlog解析处理后写入kafka, 供实时JOB消费或者映射成flink table 作为flink sql的维表join。现在随着MySQL迁移到TiDB,我们也需要TiCDC高效/稳定的支持该需求,否则业务无法完全的迁移到TiDB(只能长期保持MySQL->DM->TiDB)这种架构,无法实现真正的TiDB替代MySQL,另外就是DM还需要处理上游分库分表DDL的兼容和同步中断的处理,所以TiCDC在流处理中扮演重要的角色。
ticdc架构
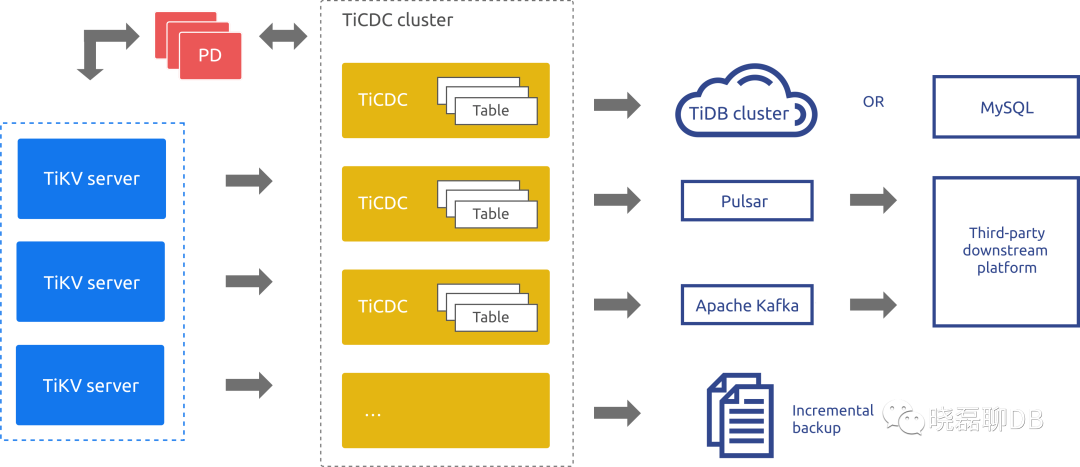
从上图的架构来看可以细分4个大模块分别为:TiKV cluster、PD、Ticdc Cluseter、Sink下游组件。
下面来详细介绍下各个组件:
1、最核心的TiCDC cluster
可以看出集群里有多个ticdc进程,专业名词可以叫做capture,capture有几大作用:
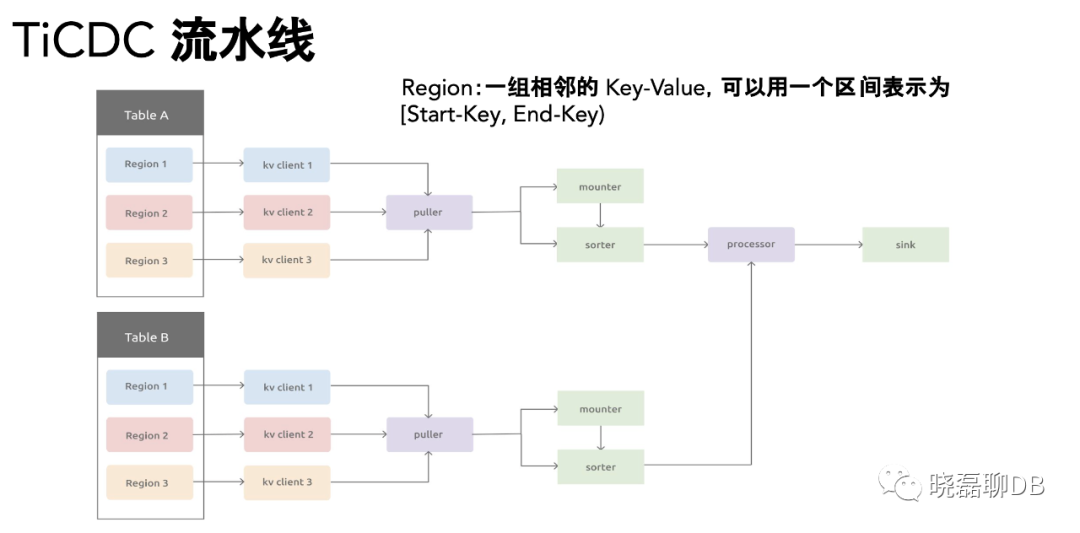
puller 负责拉取TiKV的change log,对拉取的change log排序(基于单表维度)。
基于processor这个内部逻辑线程,每个processot负责同步一张或者多张表的数据变更,一个capture节点可以运行多个processor线程,向下游输出。
高可用:多个capture组成一个ticdc集群,并且capture有不同的角色,分为owner/非owner角色,owner节点负责集群的调度,并且所有的capture都会注册到PD,一旦ticdc onwer异常,会触发选举新owner,并且owner会在其他processor节点异常时,将processor管理的同步任务调度到其他capture节点。
可以使用tiup来查看各个capture进程的状态
tiup ctl cdc capture list --pd=http://xxxxx:2379同步任务changefeed。一个同步任务可以同步一个tidb实例,也可以设定过滤规则,只同步某些DB or Table。创建同步任务:
tiup ctl:v4.0.14 cdc changefeed create --pd=http://pd-ip:2379 --sink-uri="mysql://User:password@vip:4000/" --changefeed-id="sync-name" --start-ts=0 --config=./ticdc.yaml查看同步任务:tiup ctl:v4.0.14 cdc changefeed list --pd=http://pd-ip:2379
详情可以下图的抽取逻辑
2、TiKV Cluster
用户写入的键值对会先写入磁盘上的 WAL (Write Ahead Log),又可以理解为 KV 变更日志(KV Change Logs)。一旦同步任务创建,TiCDC集群就会拉取这些 row changed events。
3、PD cluster
TIDB集群的大脑,除了分配全局TSO、管理集群元数据和调度外,在TiCDC层面:负责存储changefeed的配置和状态、capture 节点元信息、owner 选举信息以及 processor 的同步状态等。
4、Sink组件
TiCDC的下游
MySQL 协议兼容的数据库(MySQL、TiDB)
Kafka/Pulsar,然后Flink等第三方流处理组件订阅数据变更来使用。
增量备份,比如存放在S3这种分布式文件存储系统上。
早期版本的问题
之前存在的问题(大部分已经修复):
TiCDC正常同步进行中,上游TiDB突增大写入量的情况下经常OOM,稳定性不足
当TiCDC因为某些原因同步中断时,并且中断期间上游TiDB写入了大量数据,重新启动同步导致TiCDC出现 OOM 问题
ticdc的下游是tidb的情况下,上游tidb集群出现大量对同一行记录进行更新时,下游tidb出现写写冲突导致ticdc同步停止(官方已经对这个问题有解决方案)
sort-dir路径问题:之前版本的sort目录是默认跟deploy放同一目录,如果按照默认deploy是/home/tidb/deploy的话,sort目录就是默认使用系统盘(一般空间较小),当遇到突增写入或者又较大多的change log需要同步时,可能会把系统盘写满,另外ticdc同步也会因为sort目录写满而中断。目前sort目录已经修改成TiCDC的data目录
早期版本的TiCDC在拉取change log时并发度没有上限,导致TiKV节点的网卡、硬盘IO、CPU等飙升,影响了集群正常业务的运行。
在执行大的DDL操作时(比如对亿级别的表添加索引),TiCDC同步会等待DDL执行完毕后才继续同步change log。(4.0.14+版本解决)
最佳实践:
强烈建议使用4.0.14/5.1.1最新版本的ticdc,高版本修复了不少bug。
及时观察ticdc相关的监控。ticdc有专门的监控dashboard,从里面可以看出抽取changelog的速度,写下游Sink的情况,对tikv集群的影响等等,官网有对各个监控项的详细说明,如下。
https://docs.pingcap.com/zh/tidb/stable/monitor-ticdc如果数据写入kafka,除了提供默认的开放数据协议 (TiCDC Open Protocol)外,还有多种 kafka 消息协议可选择比如canal、canal-json、avro、maxwell等方式,兼容之前MySQL的cdc,可以无缝迁移。
在上游TiDB写入量比较大时,拆分多个changefeed进行同步,可以从STATEMENTSSUMMARYHISTORY系统表来看table写入分布,按照写入表拆分成多个changefeed,SQL如下:
select digest,DIGEST_TEXT,TABLE_NAMES,sum(EXEC_COUNT),min(SUMMARY_BEGIN_TIME),max(SUMMARY_END_TIME) from STATEMENTS_SUMMARY_HISTORY where stmt_type='insert' and schema_name='ad_monitor' group by digest order by sum(exec_count) desc limit 20;PS:dashboard->SQL语句分析,过滤insert找出table写入情况。
kafka的partition-num参数要设定为1,因为基于表的同步虽然是sort后执行,如果输出到多个kafka partition,kafka保证每个partition是有序的,但是消费者从多个kafka partition拿数据向下游应用时可能事务顺序会被打乱,导致数据不一致的情况产生。
为了防止因为 sort 信息过多 导致 ticdc 节点的 gorouting 异常,需要 ticdc 配置 per-table-memory-quota 到 6M 来缓解稳定,注意这个参数的values是数值类型,按照下面的方式修改:
tiup edit-config tidb-cluster-name #在全局配置的cdc配置加入下面
cdc:
per-table-memory-quota: 6291456TiKV网络限速,避免TiCDC的拉取对tikv集群造成影响,比如你的tikv都是千兆网卡,正常的集群就已经使用到30~50M,可以将ticdc的拉取限速我20M(因为担心ticdc的拉取把千兆网卡跑满影响集群正常业务),修改方式如下:
tiup edit-config tidb-cluster-name #在全局配置的tikv配置加入下面
tikv:
cdc.incremental-scan-speed-limit: 20MBTiCDC 的 gc-ttl:Ticdc默认可以hold 24小时的changlog,超过24自动释放gc。所以中断24小时以上的同步任务重启会报错,启动 TiCDC server 时可以通过 gc-ttl 指定 GC safepoint 的 TTL。
虽然gc-ttl可以为中断的同步hold 24小时的KV数据变更,但是从另外一个方面来看,累积多过的MVCC版本,肯定会对查询造成影响,需要根据业务评估影响,如果需要删除同步任务可以用下面的命令:
tiup ctl:v4.0.14 cdc changefeed remove --pd=http://pd-ip:2379 --changefeed-id=TICDC-XXX使用ticdc增量拉取时,提前调整gc lifetime。比如要用cdc做跨机房数据同步,比如:用br恢复今天凌晨备份,记得提前调整gc lifetime时间,避免BR恢复完数据创建changefeed的时候发现change log已经被gc了。
TiCDC 对大事务(大小超过 5 GB)提供部分支持,所以对于上游TIDB集群最大支持10G的事务来说,大事务可能触发TiCDC的oom。
出现同步中断时,可以先使用以下命令查看同步报错的原因,另外就是从TiCDC的日志里面查看报错的具体详情。
tiup ctl:v4.0.14 cdc changefeed query -s --pd=http://pd-ip:2379 --changefeed-id=TICDC-XXX
总结:
其实我想说的是:目前ticdc在大部分场景下是可用的。
这里要提到一件事情,就是关于ticdc稳定性和可用性立项:TiCDC在早期版本确定是出现过各种OOM以及对Tikv集群负载影响等问题,从今年年初360就提出了本文开头的3个应用场景,并且跟PingCAP的TiCDC研发团队一起合作立项,中间在线和线下沟通了10多次,基于360的高写入环境来验证TiCDC的稳定和可用性,直到现在TiCDC终于可以在各个场景下稳定运行,希望有类似需求的可以尝试使用起来,有问题可以及时跟官方沟通反馈,目的就是让TiCDC这个同步工具更加高效和稳定运行。