
Spark如何进行动态资源分配
一、操作场景
对于Spark应用来说,资源是影响Spark应用执行效率的一个重要因素。当一个长期运行的服务,若分配给它多个Executor,可是却没有任何任务分配给它,而此时有其他的应用却资源紧张,这就造成了很大的资源浪费和资源不合理的调度。
动态资源调度就是为了解决这种场景,根据当前应用任务的负载情况,实时的增减Executor个数,从而实现动态分配资源,使整个Spark系统更加健康。
二、动态资源策略
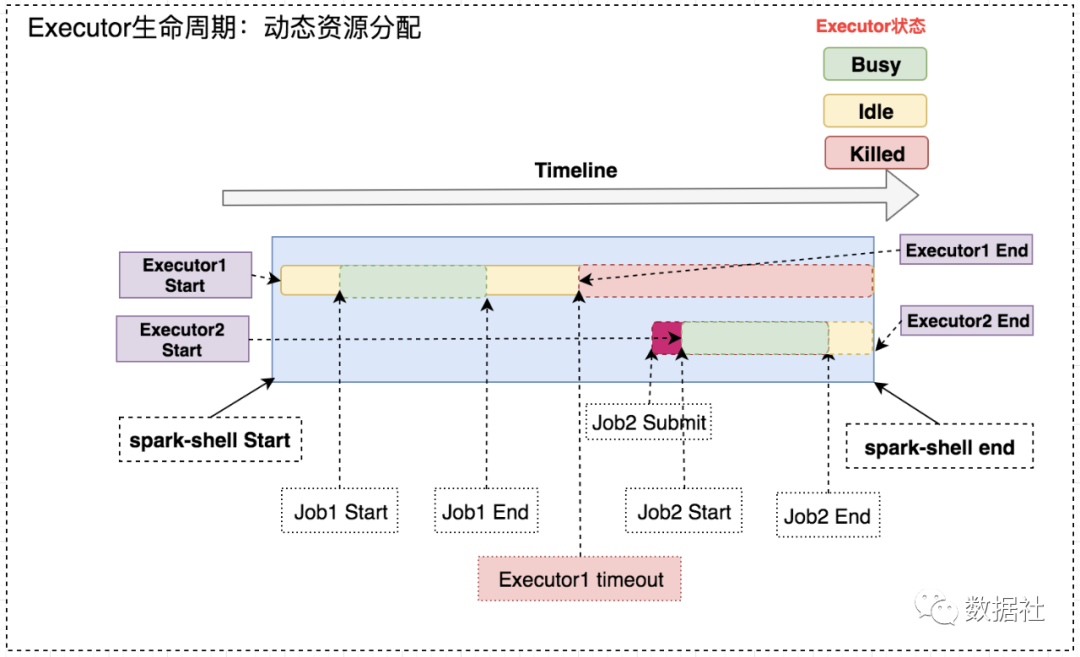
1、资源分配策略
开启动态分配策略后,application会在task因没有足够资源被挂起的时候去动态申请资源,这种情况意味着该application现有的executor无法满足所有task并行运行。spark一轮一轮的申请资源,当有task挂起或等待spark.dynamicAllocation.schedulerBacklogTimeout(默认1s)`时间的时候,会开始动态资源分配;之后会每隔spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(默认1s)时间申请一次,直到申请到足够的资源。每次申请的资源量是指数增长的,即1,2,4,8等。
之所以采用指数增长,出于两方面考虑:其一,开始申请的少是考虑到可能application会马上得到满足;其次要成倍增加,是为了防止application需要很多资源,而该方式可以在很少次数的申请之后得到满足。
2、资源回收策略
当application的executor空闲时间超过spark.dynamicAllocation.executorIdleTimeout(默认60s)后,就会被回收。
三、操作步骤
1、yarn的配置
首先需要对YARN进行配置,使其支持Spark的Shuffle Service。
修改每台集群上的yarn-site.xml:
- 修改<property><name>yarn.nodemanager.aux-servicesname><value>mapreduce_shuffle,spark_shufflevalue>property>
- 增加<property><name>yarn.nodemanager.aux-services.spark_shuffle.classname><value>org.apache.spark.network.yarn.YarnShuffleServicevalue>property><property><name>spark.shuffle.service.portname><value>7337value>property>
将$SPARKHOME/lib/spark-X.X.X-yarn-shuffle.jar拷贝到每台NodeManager的${HADOOPHOME}/share/hadoop/yarn/lib/下, 重启所有修改配置的节点。
2、Spark的配置
配置$SPARK_HOME/conf/spark-defaults.conf,增加以下参数:
spark.shuffle.service.enabled true //启用External shuffle Service服务spark.shuffle.service.port 7337 //Shuffle Service默认服务端口,必须和yarn-site中的一致spark.dynamicAllocation.enabled true //开启动态资源分配spark.dynamicAllocation.minExecutors 1 //每个Application最小分配的executor数spark.dynamicAllocation.maxExecutors 30 //每个Application最大并发分配的executor数spark.dynamicAllocation.schedulerBacklogTimeout 1sspark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
四、启动
使用spark-sql On Yarn执行SQL,动态分配资源。以yarn-client模式启动ThriftServer:
cd $SPARK_HOME/sbin/\--master yarn-client \--conf spark.driver.memory=10G \--conf spark.shuffle.service.enabled=true \--conf spark.dynamicAllocation.enabled=true \--conf spark.dynamicAllocation.minExecutors=1 \--conf spark.dynamicAllocation.maxExecutors=300 \--conf spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s
启动后,ThriftServer会在Yarn上作为一个长服务来运行。
点击【阅读全文】可以查看官方文档最新版本详细介绍~