
大白话说协程

普通的函数
def func():print("a")print("b")print("c")
调用func func开始执行,直到return func执行完成,返回函数A
abc

从普通函数到协程
void func() {print("a")暂停并返回print("b")暂停并返回print("c")}
void func() {print("a")returnprint("b")暂停并返回print("c")}
void func() {print("a")定print("b")定print("c")}

Show Me The Code
void func() {print("a")yieldprint("b")yieldprint("c")}
def A():co = func() # 得到该协程next(co) # 调用协程print("in function A") # do somethingnext(co) # 再次调用该协程
aain function A
ain function Ab
图形化解释
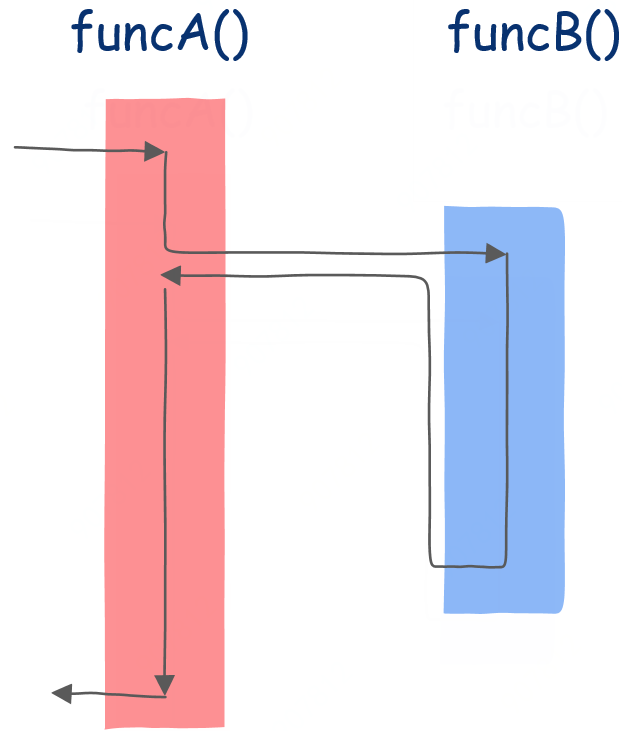
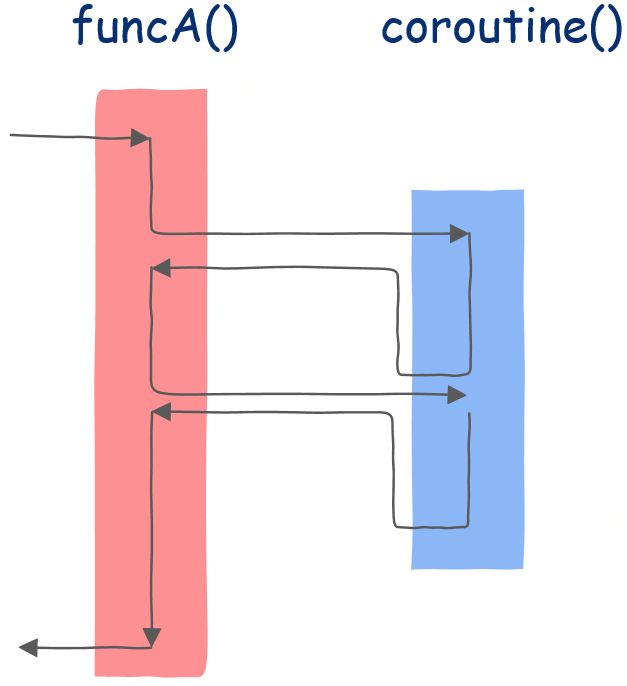
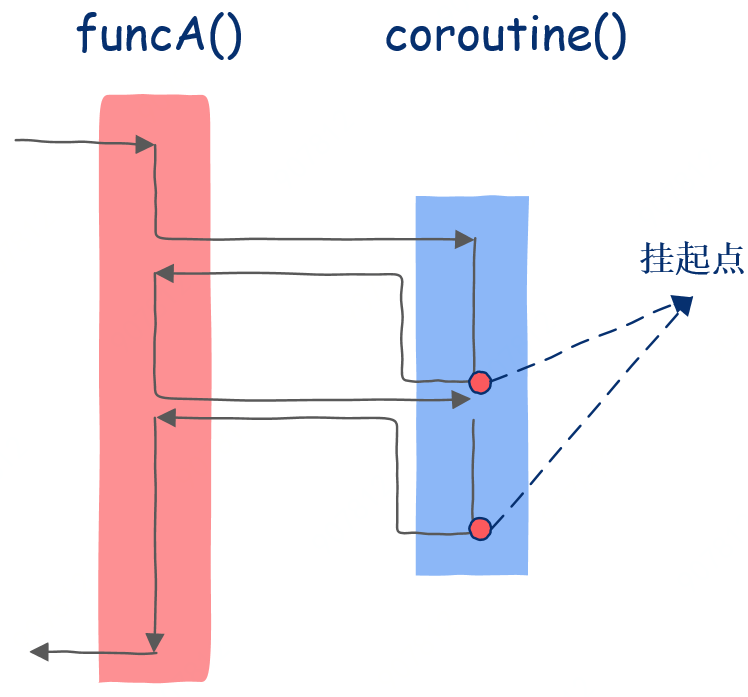
函数只是协程的一种特例

协程的历史

协程是如何实现的

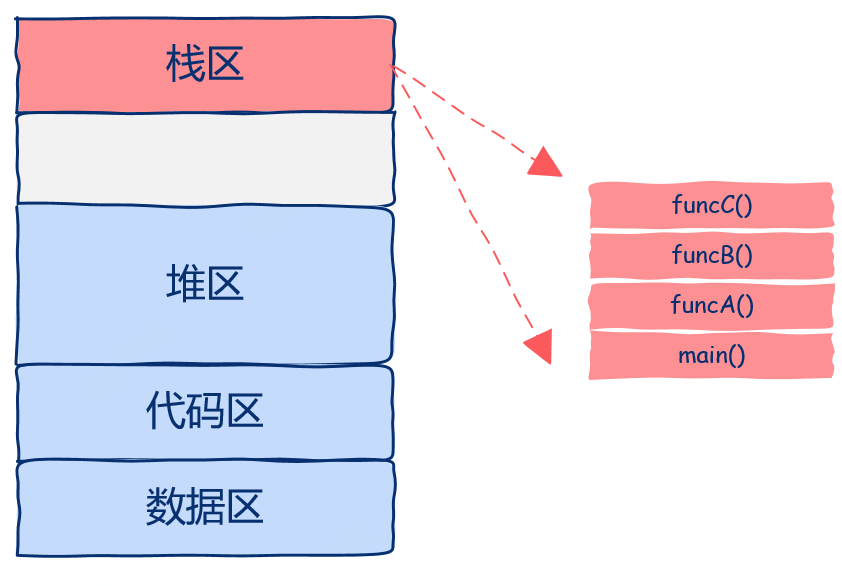
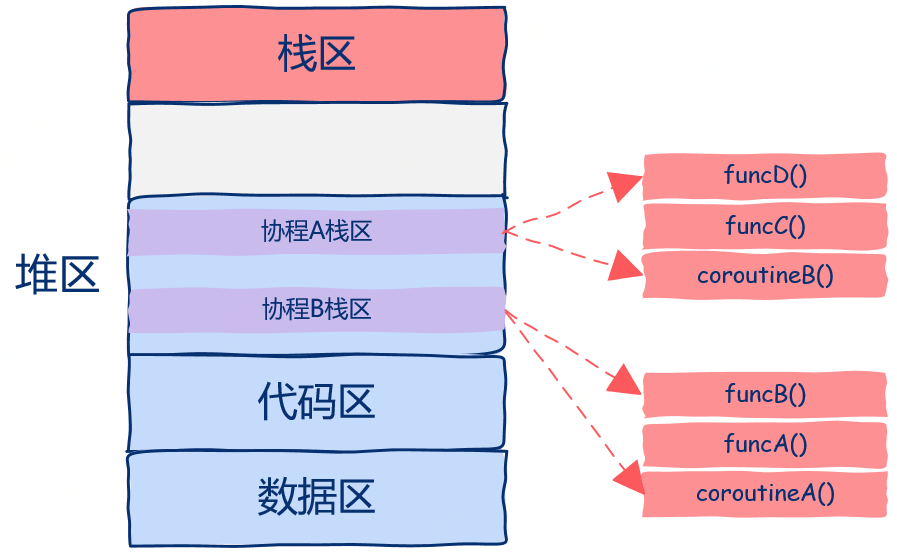
一个普通线程
两个协程


总结
评论