
Impala 3.4 在网易的最新实践
导读:Impala是Cloudera公司主导开发的交互式查询系统,它提供SQL语义和计算能力,但是本身并不存储数据。本次分享会聚焦于Impala在网易内部的一些新实践,以及基于Impala 3.4版本所做的优化和改进。
主要会围绕以下四点展开:
Impala定位及使用
Impala对接Iceberg
Impala管理系统
Impala未来规划
1. 什么是Impala?
Cloudera开源贡献至Apache的OLAP引擎
提供高并发和低延迟的交互式SQL查询
可以查询HDFS/HBase/Kudu中的数据
2. Impala优势
去中心化的MPP架构
完全兼容Hive元数据格式
Apache顶级项目,社区活跃度高
支持多种数据格式,例如Parquet、Orc、Avro等
高效的查询性能,支持codegen、llvm、runtime filter等
3. Impala架构简介
下面是Impala的一个架构,如图所示:
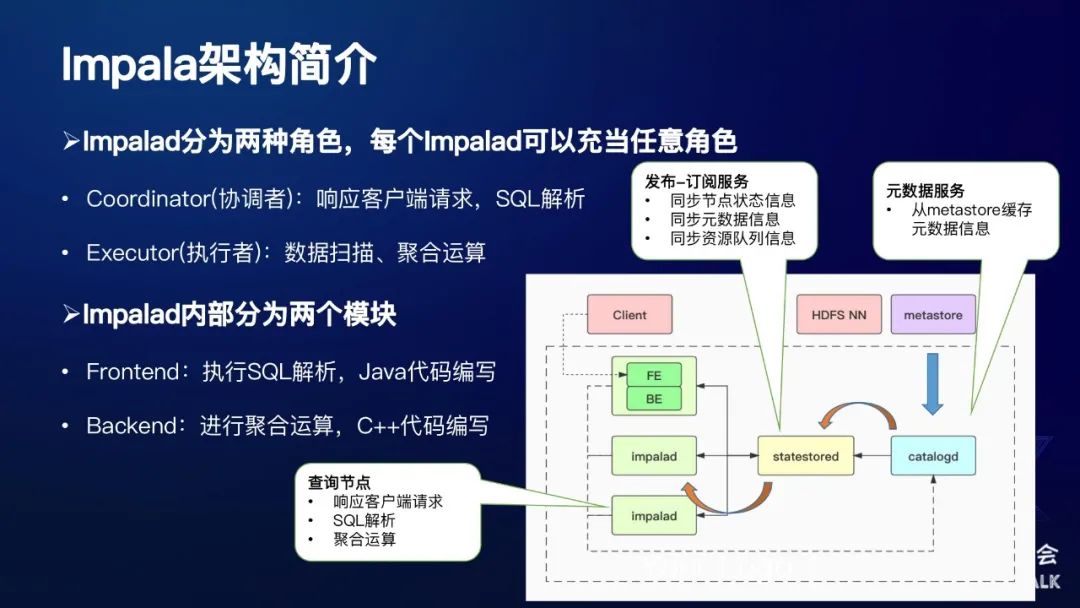
Impalad节点分为两种角色:
Coordinator(协调者):响应客户端请求,SQL解析
Executor(执行者):数据扫描、聚合运算
Impalad内部分为两个模块:
Frontend:执行SQL解析,Java代码编写
Backend:进行聚合运算,C++代码编写
Impala主要分为三种服务,每种服务对应一个单独的进程。
第一种服务:从最左边绿色的部分可以看起,它是一个Impalad 进程,主要有两种角色,第一种角色:Coordinator(协调者),它主要的功能是响应JDBC请求,对发过来的SQL进行执行计划解析,将SQL生成的执行计划发给各个Executor(执行者),这些Executor会进行数据扫描和聚合运算等操作。每个Impalad节点,既可以充当Coordinator,也可以充当Executor,也可以二者兼之。在Impalad内部也分为两个模块,其中FE模块由Java代码编写,主要执行SQL的解析操作,使用Java可以更好地兼容Hadoop生态圈;BE模块由C++代码编写,主要负责实际的数据扫描、聚合运算,使用C++可以进行更好地性能优化。
第二种服务:catalogd,它是一个元数据服务,单独的一个进程,主要就是将hive的metastore所存储的元数据缓存到自己的内存当中。
第三种服务:statestored,它是一个发布订阅服务,主要的作用包括节点之间状态信息的同步、元数据信息的同步、资源队列的信息同步等等。
这里以元数据服务加载为例:首先catalogd将元数据缓存到自己的内存中,同时它会将元数据信息发布到statestored上面,然后Impalad就可以去订阅相应的topic,将这部分信息拉到自己的本地进行缓存。这整体就是一个发布订阅的过程。
需要注意的是,在一个Impala集群中,statestored和catalogd只有一个,Impalad节点有若干个。由于coordinator需要进行执行计划解析,因此需要缓存元数据在自己的内存中。实际线上部署的时候,我们一般会将coordinator和executor分开,同时集群中只有配置少量几个coordinator节点,大部分都是executor节点。
4. Impala 3.x新特性
3.0到3.4的特性罗列:
支持在相同的查询块中存在多个distinct算子
支持优雅的(不影响正在执行的查询)关闭impala进程
支持ORC文件格式
支持DATE数据类型及其操作函数
支持将远端的HDFS/S3等文件缓存到Impalad节点上
CBO增强
支持将Profile信息导出成JSON格式,方便解析
...
5. Impala内部特性增强
Impala 在网易内部进行的一些开发,以下做了一个简单的列举:
支持Impala对接Iceberg
元数据同步功能
Impala on Alluxio功能
Impala管理系统
集群节点分组功能
6. Impala在网易易数

Impala在网易这边的定位是作为一个交互式查询系统,对下可以查询存储在HDFS、Kudu、HBase等等这些存储系统中的数据,向上它可以对接一些我们开发的BI工具、或者是一些业务自己的系统等。
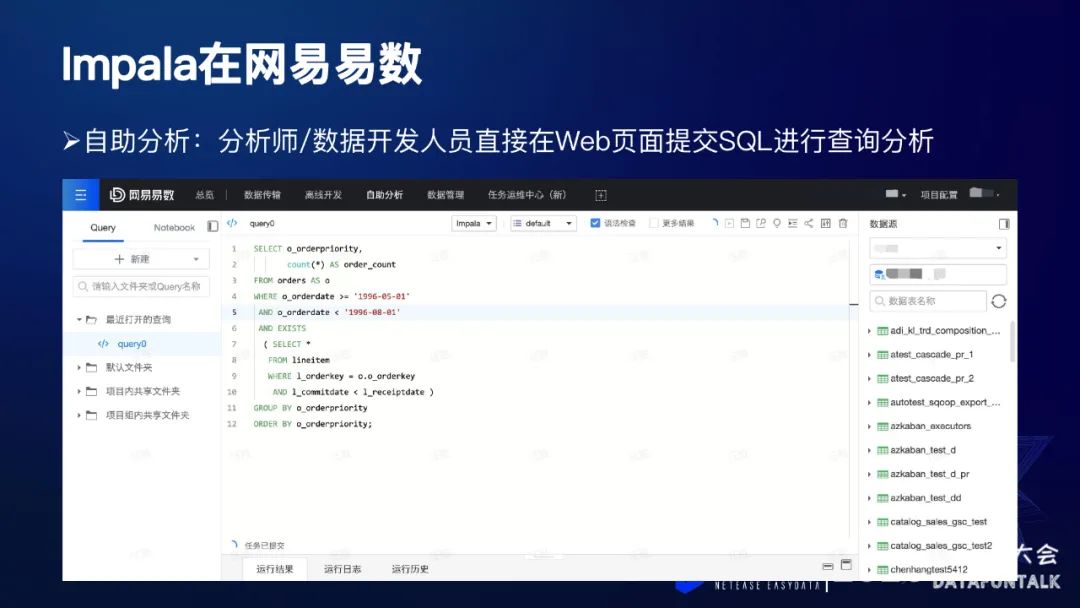
上图所示是我们内部的一个使用场景:自助分析,主要提供给分析师或者数据开发人员使用,直接在页面上提交SQL查询,通过SQL来获取自己想要的数据,这个与Cloudera的HUE类似。
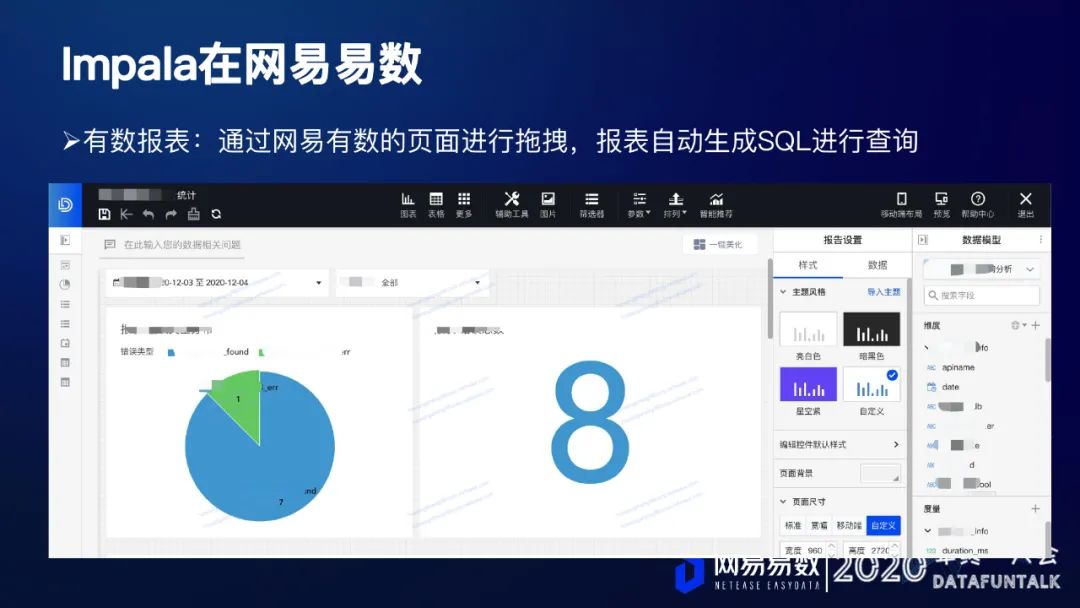
另外一个使用场景就是:网易有数,作为一款BI工具,它提供了一个图形化界面,用户只需要在这个页面上进行相应的一些拖拽操作,系统会自动地生成相应的SQL,发到Impala,根据Impala的查询结果,以图形化的界面形式展示给用户。用户不需要关注具体的SQL编写,只需要在页面上进行一些简单的控件拖拽,就可以获取相应的图标展示,非常方便。
1. 什么是Iceberg?
Apache Iceberg is an open table format for huge analytic datasets.
从官网上来看可以知道它是一个表格式,为了一个海量的数据分析所诞生的,这也就意味着它并不是一个单独的服务,它只是提供了一系列的API,我们需要去操作这些API。
2. 为什么要引入Iceberg?
以下是我们在内部业务中遇到的痛点,这里简单给大家归纳以下:
① 百TB级的离线任务延迟导致报表产出时间不稳
凌晨NameNode压力很大,请求延迟不稳定
任务ETL效率相对低效,一次ETL需要时间2个小时
一旦遇到磁盘坏掉或者机器宕机,Spark任务重试一次就会导致2小时延迟
② 基于Lambda架构的实时数据仓库存在较多问题
Kafka无法支持海量数据存储,无法支持高效的OLAP查询
Lambda架构维护成本很高
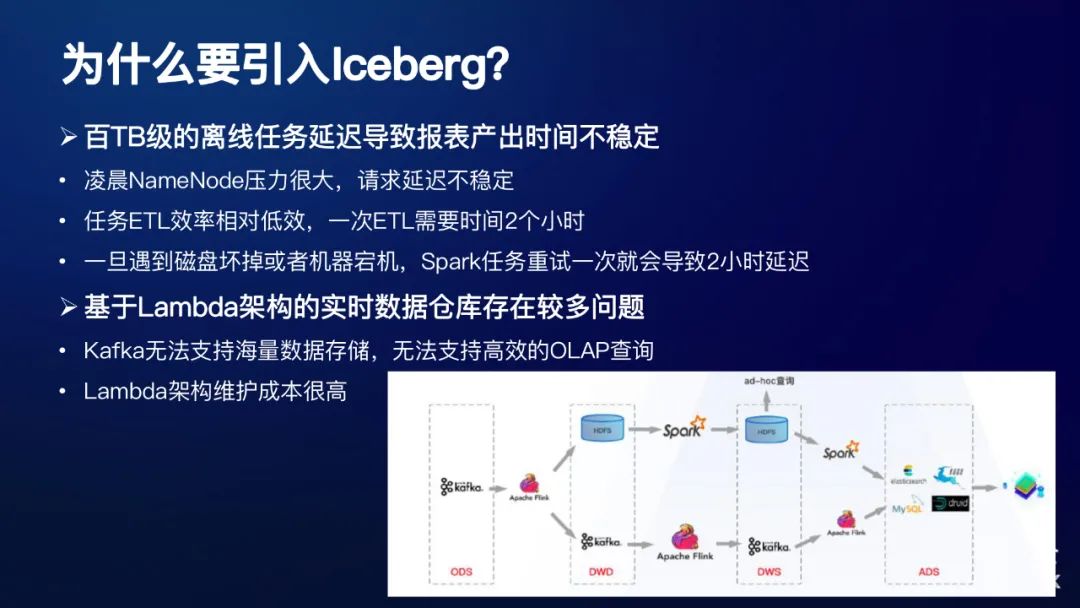
上图目前我们网易内部的一个数仓架构图,可以看到,维护实时和离线两条线路,本身涉及到的组建也比较多。关于这块相关的情况,之前也有同事做过Iceberg相关的分享,这里就不再展开了。
3. Impala支持Iceberg功能
通过Impala创建Iceberg表
通过Impala查询Iceberg表
支持INSERT INTO非分区的Iceberg表(Parquet格式)
支持部分ALTER操作,例如ADD COLUMNS/RENAME TABLE等
支持DESCRIBE HISTORY,查看表的历史snapshots
4. Impala创建Iceberg表
Catalog类型:
HiveCatalog/HadoopCatalog/HadoopTables
数据文件格式:Parquet/ORC格式
分区类型:
IDENTITY/YEAR/MONTH/DAY/BUCKET/TRUNCATE
Iceberg本身提供了好几种分区类型,它与传统的Hive不太一样。举一个简单的例子:

这是Impala创建Iceberg表的一个SQL,首先我们知道Hive的分区列只是一个逻辑上的概念,是HDFS上的一个目录层级。但是Iceberg表的分区列的数据,在底层的数据文件中也是存在的,所以在建表的时候,分区列也必须位于表名后面。第二点是新增了一个关键字SPC,如果要创建Iceberg分区表的话,必须要指定关键字SPEC。第三点就是我们在定义分区的时候,列名后面跟的是分区类型,而Hive后面跟的是列的类型。最后一点需要注意的是,需要在TBLPROPERTIES中指定各个属性。因为Iceberg在Impala中是一个表格式,有不同的数据文件,所以目前采取的方式是在表属性中对这些属性进行相应的定义。总结一下,有以下几点:
分区列数据也存在于数据文件中
新关键字标识SPEC
定义分区时,列名后面跟分区类型
需要在表属性中定义文件格式、catalog类型
5. Impala查询Iceberg表
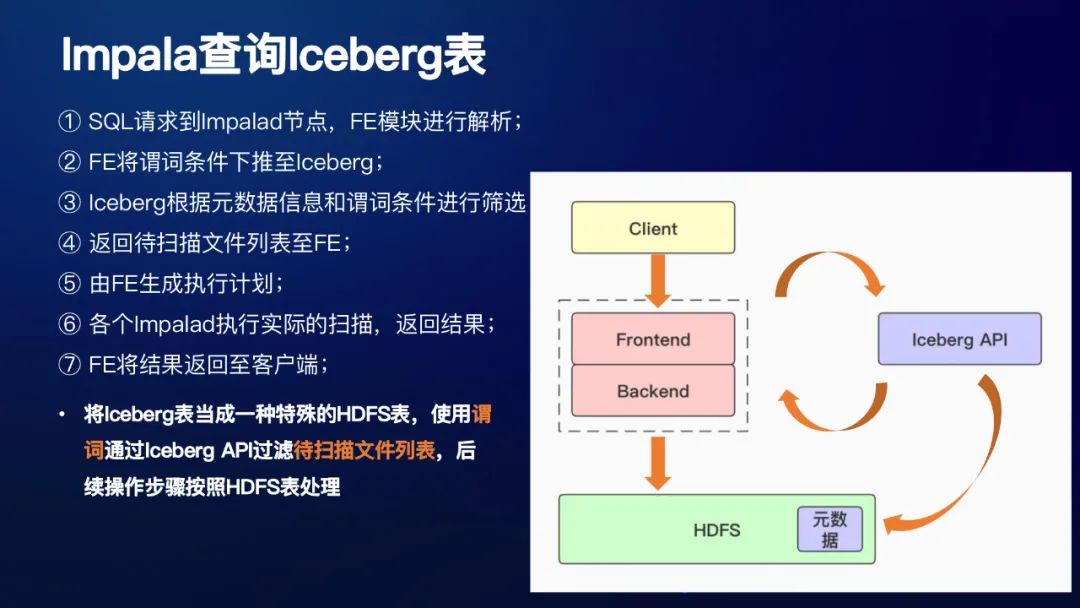
接下来看一下Impala查询Iceberg表简单流程:
① SQL请求到Impalad节点,FE模块进行解析;
② FE将谓词条件下推至Iceberg,其实就是调用了Iceberg的api;
③ Iceberg根据元数据信息和谓词条件进行筛选
④ 返回待扫描文件列表至FE;
⑤ 由FE生成执行计划;
⑥ 各个Impalad执行实际的扫描,返回结果;
⑦ FE将结果返回至客户端;
总结下来就是:将Iceberg表当成一种特殊的HDFS表,使用谓词通过Iceberg API过滤待扫描文件列表,后续操作步骤按照HDFS表处理。这样设计的好处,就是可以复用大量的Impala代码(Impala的SCAN都是在BE模块,用C++实现的)。
6. 其他SQL支持
① INSERT INTO非分区表(Parquet)
INSERT INTO xxx SELECT * FROM xxx
INSERT INTO xxx VALUES(...)
CREATE TABLE xxx AS SELECT * FROM xxx
② DESCRIBE HISTORY查看snapshots
DESCRIBE HISTOR Y xxx
7. 2.12.0 parquet vs Iceberg
我们将基本的建表和查询功能backup到了2.12.0版本,与parquet进行了对比,测试环境为10台384G、48核的物理机,数据集为TPCDS-1000,测试结果如下:
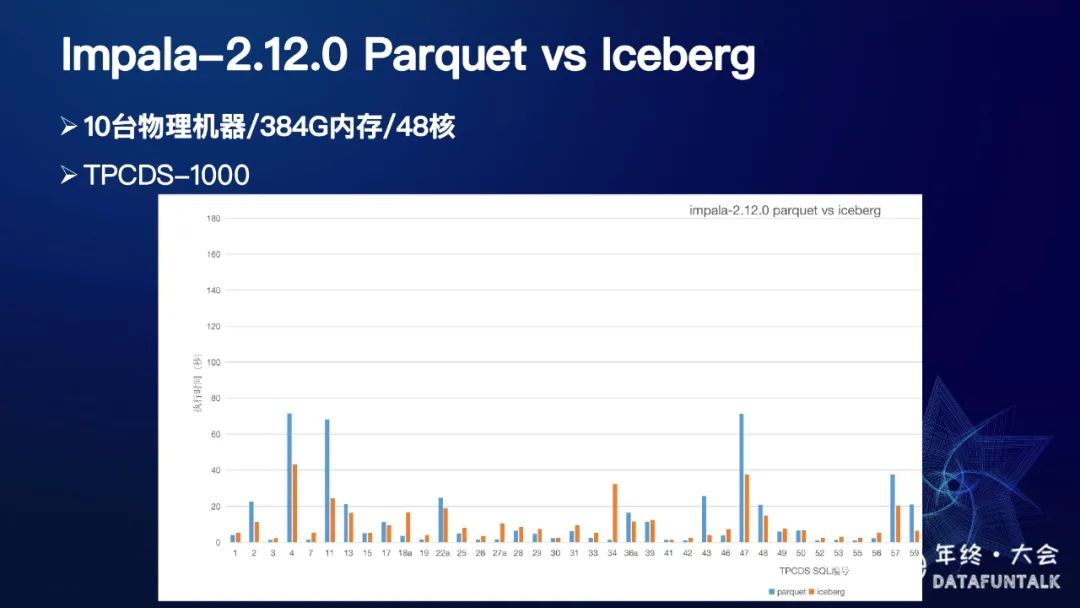
目前我们只是做了一个简单的对比,后续会进行更深入的分析和优化。
8. 社区相关动态
社区EPIC地址:
https://issues.apache.org/jira/browse/IMPALA-10149
目前开发基于社区4.0版本,低版本需要手动将patch合并
目前还有很多功能待完成,大家感兴趣的话,欢迎大家一起参与开发。

1. Impala管理系统增强
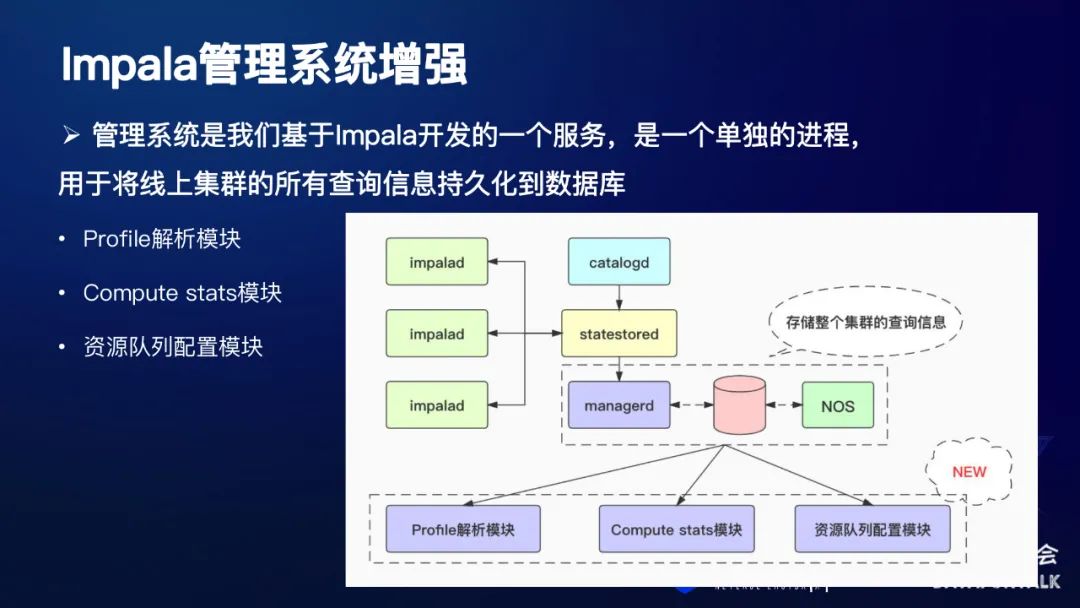
管理系统是网易基于Impala开发的一个服务,是一个单独的进程, 用于将线上集群的所有查询信息持久化到数据库,我们这里主要介绍以下,基于管理系统所新增的三个模块。
Profile解析模块
Compute stats模块
资源队列配置模块
2. Profile解析模块
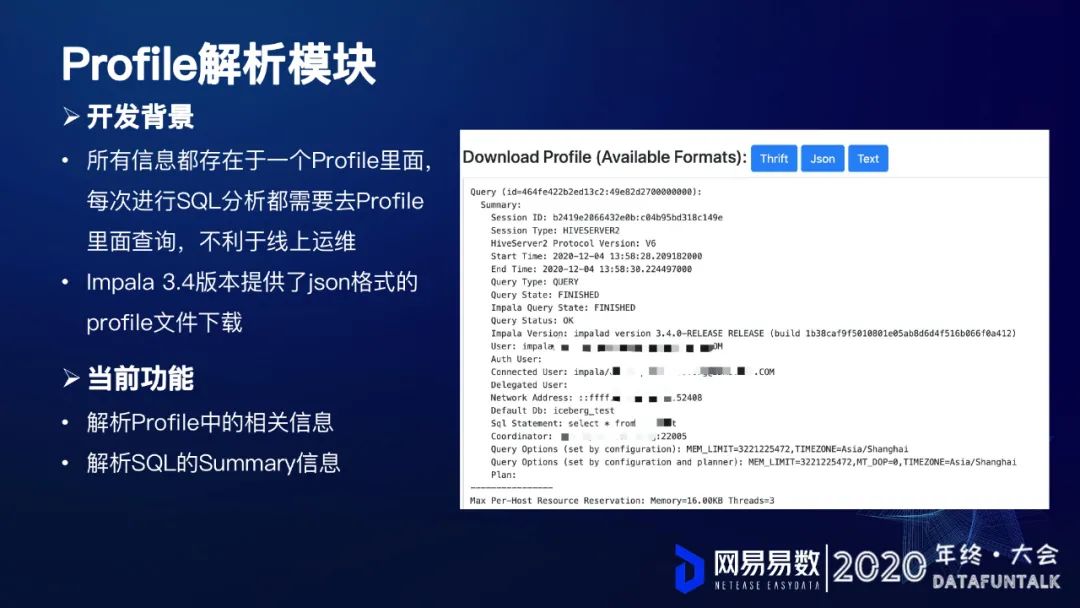
从上面这个截图可以看到,profile其实是非常详细的,它包含了整个查询的所有相关信息。
所有信息都存在于一个Profile里面, 每次进行SQL分析都需要去Profile 里面查询,不利于线上运维
Impala 3.4版本提供了json格式的 profile文件下载
基于这两点考量,网易开发了一个的解析模块,它主要包括下面两个功能:
解析Profile中的相关信息
解析SQL的Summary信息
接下来就分别看看这两点:
① Node解析
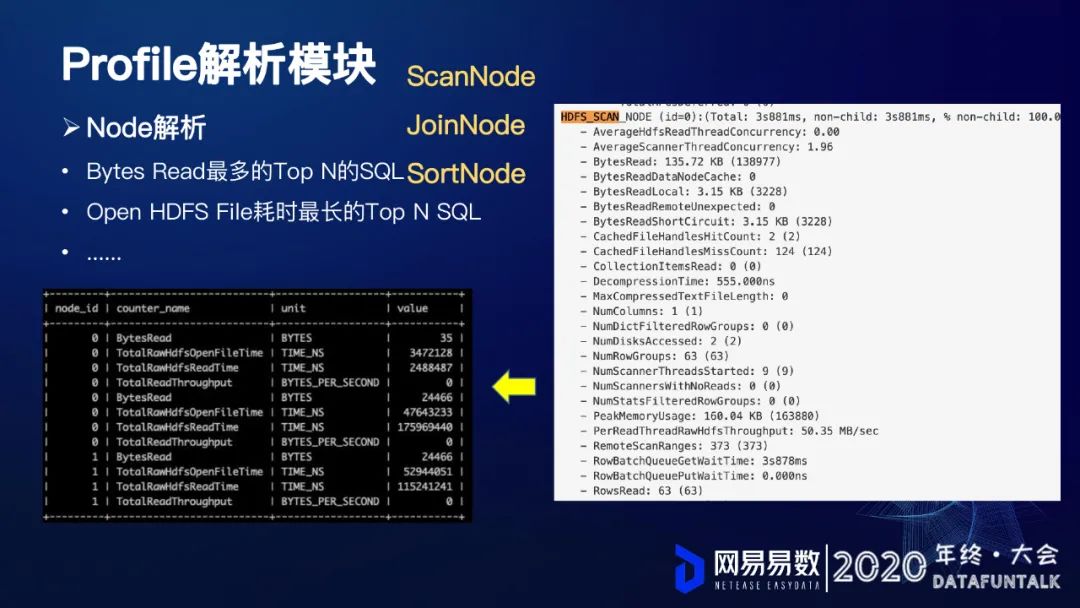
Node分为ScanNode、JoinNode、SortNode。上图是典型的HTFS_SCAN_NODE,它包含了很多的指标。从截图中看到,像读取的字节数,本地读取的字节数,读取的函数等等,这块都是有展示的。我们将这些指标都提取出来,然后解析成一条一条的记录存储到Mysql表当中。
通过对这些字段进行一些过滤、排序和筛选,例如:
Bytes Read最多的Top N的SQL
nOpen HDFS File耗时最长的Top N SQL
......
② Summary解析

上面是summary信息,它包含了SQL执行每个阶段,我们将这些阶段也都进行相应的解析提取,然后转化成一条一条的记录,然后存储在MySQL表中。
和上面一样,我们也可以对表进行相应的一些处理,获取如下的一些信息:
SCAN HDFS最慢的Top N SQL
HASH JOIN最慢的Top N SQL
......
3. Compute Stats模块
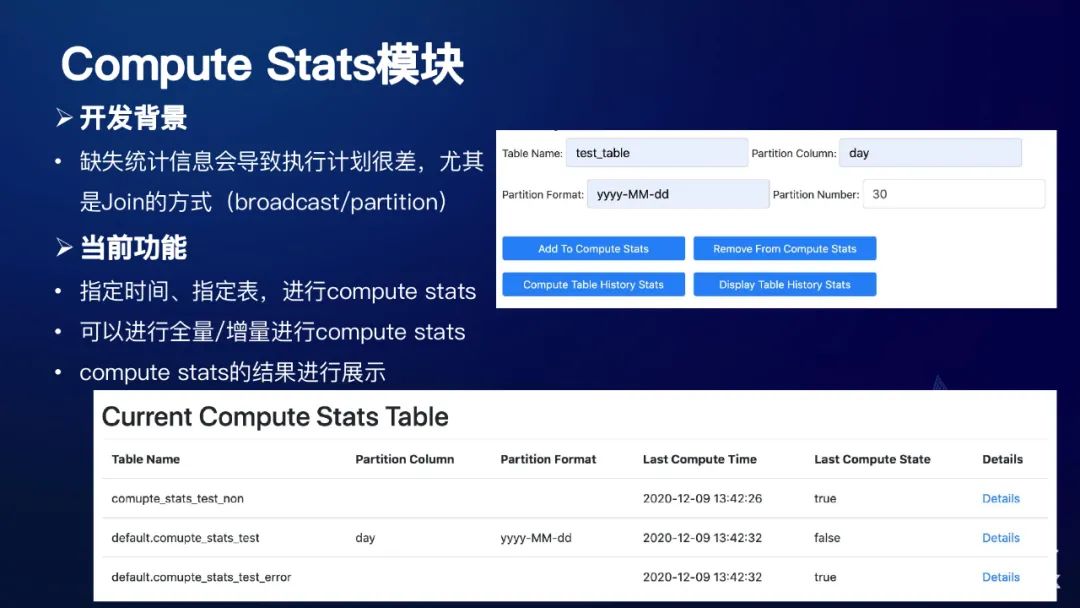
统计信息计算模块,Impala之前对于统计信息的依赖是非常重的,如果说这个表没有统计信息的话,它的执行计划有时候会非常的差,尤其是我们Join的方式。我们所说的统计信息通常会包括像每个列的最大值,最小值,还有它的distinct值等,这些我们都可以称之为统计信息。基于这个原因,网易目前开发了这样一个模块,它主要包括这三个功能:
指定时间、指定表,进行compute stats
可以进行全量/增量进行compute stats
compute stats的结果进行展示
下面就是一些相关的配置和页面展示情况:
4. Impala 3.4优化新参数
下面两个新的参数3.4版本所引入的,也可以理解是对于CBO的增强。
① BROADCAST_BYTES_LIMIT
当broadcast join的数据量超过该阈值,则使用partition join
默认32G,是一个query option
对于有些集群,如果网络是它的瓶颈,我们就可以考虑将这个值调小一点,限制广播的数据量,对于我们的网络负载是有一定帮助的。
② DISABLE_HDFS_NUM_ROWS_ESTIMATE
默认为false,表示当hdfs表的统计信息缺失的时候,进行行数的预估
这就意味着这个表如果没有统计信息的话,Impala会对它进行一个预估,不会像以前一样非常暴力的采取一个默认的值。目前这个参数只对HDFS表有效,对于Kudu表是无效的。
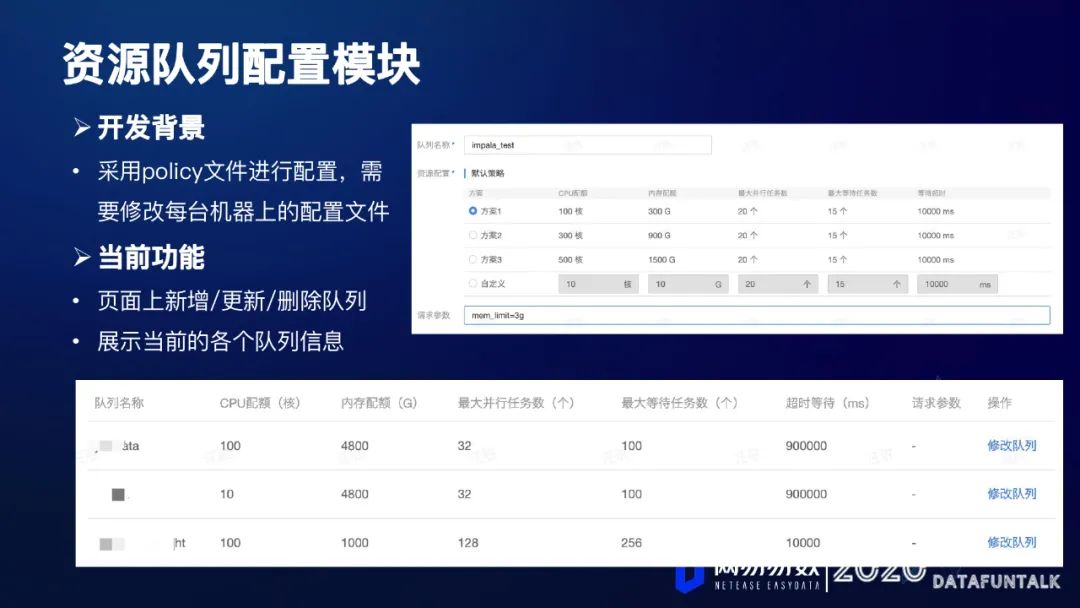
5. 资源队列配置模块
在Impala2.12的时候,采用policy文件进行配置,需要修改每台机器上的配置文件,新增或者修改一个队列的话,就需要在所有的机器上把配置文件进行修改(可以只配置coordinator),这样比较麻烦,不利于运维。基于这个情况,我们就开发了资源对列配置模块。主要有以下这些功能:
页面上新增/更新/删除队列
展示当前的各个队列信息
如图所示:
1. 基于k8s和集群分组的动态伸缩

支持impala on k8s,实现Impala集群的快速部署和运维
基于集群分组,实现不同的业务隔离
支持集群节点的快速扩容/缩容
2. 基于Alluxio的HDFS文件缓存和优化
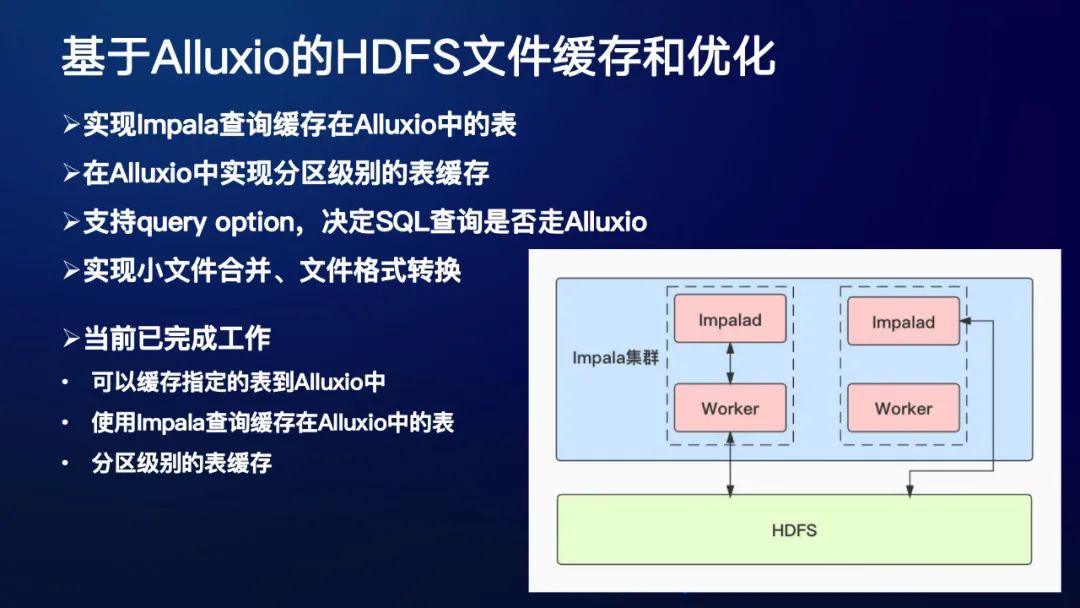
实现Impala查询缓存在Alluxio中的表
在Alluxio中实现分区级别的表缓存
支持query option,决定SQL查询是否走Alluxio
实现小文件合并、文件格式转换
3. 预计算与SQL路由
根据用户配置或者SQL分析,通过物化视图进行预计算
根据配置决定预计算的结果是否放在Alluxio中
用户查询路由,优选选择预计算的中间表
根据规则对SQL进行重写,优化SQL执行
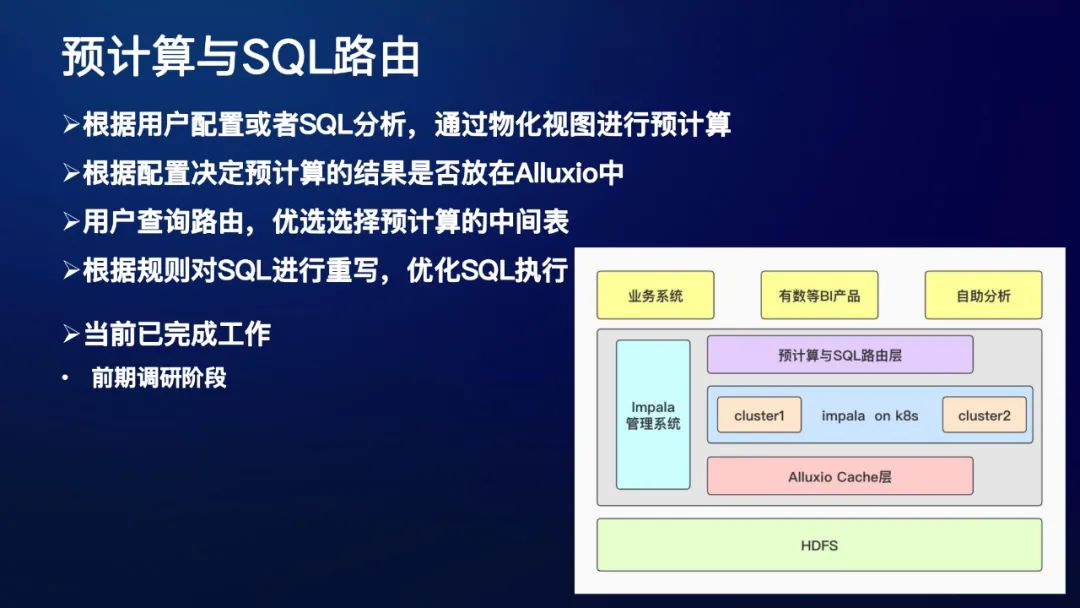
基于以上三个模块,就有了如上图这样一个整体的架构,这就是目前Impala在网易的一个整体的未来规划。