
十连发,Leetcode算法题分享(哈希表)
文章已收录Github精选,欢迎Star:https://github.com/yehongzhi/learningSummary
前言
本篇文章主要讲解leetcode上,关于哈希表(简单难度)的算法题目。
1. 两数之和
题目:
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
你可以按任意顺序返回答案。
示例1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
解法1(暴力解法)
思路:
因为在数组中有两个整数的和等于目标值,很自然地我们就会想到一个个来尝试。我们知道目标值target和nums[i],只需要找到nums[j],然后返回new int[]{i,j}即可。
代码如下:
public int[] twoSum(int[] nums, int target) {
for (int i = 0; i < nums.length; i++) {
//由于数组中同一个元素不能使用两遍,所以j从i的下一个元素开始
for (int j = i + 1; j < nums.length; j++) {
if (target - nums[i] == nums[j]) {
return new int[]{i, j};
}
}
}
return new int[]{};
}
提交代码,结果如下:

按道理嵌套循环的话,时间应该会久一点,居然仅用了0ms,我也不太相信,但是提交了三四次也是这个结果,不管了,哈哈~
假如我们想去掉嵌套循环,优化一下,怎么做呢?没错,就是今天的主角,哈希表!
解法2(HashMap)
思路:
创建一个Map集合,key是nums[i]元素的值,value是下标值i。当target - 当前遍历的元素的差值在map中存在时,就返回new int[]{map.get(target-nums[i]),i}。如果不在map集合中,就把元素值和元素下标存进map集合中。
代码如下:
public int[] twoSum(int[] nums, int target) {
//map的key是nums[i]的值,value是下标i
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
//获取结果值与nums[i]的差值
int diff = target - nums[i];
//如果包含的话,返回结果
if (map.containsKey(diff)) {
return new int[]{map.get(diff), i};
} else {
map.put(nums[i], i);
}
}
return new int[]{};
}
提交代码,结果如下:

349. 两个数组的交集
题目:
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
实例2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
解法1(暴力解法)
嵌套循环,比较两个数组中的元素,如果nums1[i] == nums2[j]的话,表示两个数组中都有的数字,则添加到HashSet(去重),最后再把HashSet转换成数组输出。
代码如下:
public int[] intersection(int[] nums1, int[] nums2) {
Set<Integer> set = new HashSet<>();
for (int i = 0; i < nums1.length; i++) {
for (int j = 0; j < nums2.length; j++) {
if (nums1[i] == nums2[j]) {
set.add(nums1[i]);
}
}
}
//HashSet转换成数组输出
return set.stream().mapToInt(Integer::intValue).toArray();
}
提交代码,结果如下:
经典的击败5%的用户,这是很正常的结果,因为使用了嵌套循环,而且还要把HashSet转换成数组,非常耗费性能,那么有没有优化空间呢,答案是肯定有的。
解法2
如果要判断一个整数是否包含在无序的数组中,只能从头遍历到尾。既然数组在判断时需要从头到尾遍历这么耗费性能,那我们能不能换一种数据结构,做到快速判断是否包含在其中呢,答案就是哈希表。HashSet的底层就是一个哈希表,所以我们把nums1的数全部存入一个HashSet中,然后再遍历nums2,判断nums中的元素是否包含在HashSet中即可。
代码如下:
public int[] intersection(int[] nums1, int[] nums2) {
Set<Integer> s1 = new HashSet<>();
for (int n1 : nums1) {
s1.add(n1);
}
Set<Integer> s2 = new HashSet<>();
for (int n2 : nums2) {
if (s1.contains(n2)) {
s2.add(n2);
}
}
//把set集合转成数组,返回
int[] res = new int[s2.size()];
int i = 0;
for (Integer num : s2) {
res[i] = num;
i++;
}
return res;
}
提交代码,结果如下:
350. 两个数组的交集II
题目:
给定两个数组,编写一个函数来计算它们的交集。
示例1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2,2]
示例2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[4,9]
说明:
输出结果中每个元素出现的次数,应与元素在两个数组中出现次数的最小值一致。 我们可以不考虑输出结果的顺序。
解法1
这道题是上面那道题的变形,不同在于输出结果不需要去重。因此我们不能使用HashSet存储,而要改用HashMap,key是数组中的元素,value是元素的个数。在判断是否包含在其中的时候,还要判断个数是否大于0,每添加一个元素到结果集中就从HashMap中减去一个元素的个数。
最后把结果集转成数组返回即可。
代码如下:
public int[] intersect(int[] nums1, int[] nums2) {
//key为num1的元素,value为元素出现的次数
Map<Integer, Integer> map = new HashMap<>();
for (int num : nums1) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
List<Integer> list = new ArrayList<>();
for (int num : nums2) {
if (map.containsKey(num) && map.get(num) > 0) {
list.add(num);
map.put(num, map.get(num) - 1);
}
}
int[] res = new int[list.size()];
for (int i = 0; i < list.size(); i++) {
res[i] = list.get(i);
}
return res;
}
提交代码,结果如下:
771. 宝石与石头
题目:
给定字符串J 代表石头中宝石的类型,和字符串 S代表你拥有的石头。S 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
J 中的字母不重复,J 和 S中的所有字符都是字母。字母区分大小写,因此"a"和"A"是不同类型的石头。
示例1:
输入: J = "aA", S = "aAAbbbb"
输出: 3
示例2:
输入: J = "z", S = "ZZ"
输出: 0
注意:
S和J最多含有50个字母。J中的字符不重复。
解法1(HashSet)
这也是一个很典型的使用哈希表判断是否包含在集合中的题目。思路还是跟前面判断交集的一样,先把其中一个字符串遍历每个字符,放进HashSet,然后再遍历另一个字符串,判断是否包含在其中,包含则数量加一。最后返回结果。
代码如下:
public int numJewelsInStones(String jewels, String stones) {
Set<Character> set = new HashSet<>();
for (char j : jewels.toCharArray()) {
set.add(j);
}
int count = 0;
for (char s : stones.toCharArray()) {
if(set.contains(s)){
count++;
}
}
return count;
}
提交代码,结果如下:
解法2(简化版哈希表)
上面的解法执行用时2ms已经很快了,但是如果细心想一下,其实没必要使用HashSet集合,因为题目已经告诉我们只有字母,因此我们大可以使用一个数组模拟一个哈希表,优化一下。
代码如下:
public int numJewelsInStones(String jewels, String stones) {
//大写字母'A'的ASCII码是65,小写字母'z'的ASCII码是122
//所以使用一个长度58的数组已经足够
boolean[] bools = new boolean[58];
for (char j : jewels.toCharArray()) {
//类似哈希映射,把对应下标标记为true
bools[j - 'A'] = true;
}
int count = 0;
for (char s : stones.toCharArray()) {
boolean bool = bools[s - 'A'];
//如果对应下标为true,则是宝石
if (bool) {
count++;
}
}
return count;
}
提交代码,结果如下:
387. 字符串中的第一个唯一字符
题目:
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
示例:
s = "leetcode"
返回 0
s = "loveleetcode"
返回 2
**提示:**你可以假定该字符串只包含小写字母。
解法1(HashMap)
我们可以遍历两次,第一次遍历使用HashMap记录字符出现的次数,第二次遍历找出只出现一次的字符,返回它的索引。
代码如下:
public int firstUniqChar(String s) {
Map<Character, Integer> map = new HashMap<>();
char[] chars = s.toCharArray();
for (char c : chars) {
map.put(c, map.getOrDefault(c, 0) + 1);
}
for (int i = 0; i < chars.length; i++) {
Integer count = map.get(chars[i]);
if (count == 1) {
return i;
}
}
return -1;
}
提交代码,结果如下:

解法2
显然解法1耗时过长,不是很理想。怎么优化呢,要抓住题目给的提示,只包含小写字母。既然只含有小写字母,那么我们就可以简化哈希表,使用一个数组代替。
代码如下:
public int firstUniqChar(String s) {
int[] hash = new int[26];
char[] chars = s.toCharArray();
for (char ch : chars) {
hash[ch - 'a']++;
}
for (int i = 0; i < chars.length; i++) {
if (hash[chars[i] - 'a'] == 1) {
return i;
}
}
return -1;
}
提交代码,结果如下:

1365. 有多少小于当前数字的数字
给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。
换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 nums[j] < nums[i] 。
以数组形式返回答案。
示例1:
输入:nums = [8,1,2,2,3]
输出:[4,0,1,1,3]
解释:
对于 nums[0]=8 存在四个比它小的数字:(1,2,2 和 3)。
对于 nums[1]=1 不存在比它小的数字。
对于 nums[2]=2 存在一个比它小的数字:(1)。
对于 nums[3]=2 存在一个比它小的数字:(1)。
对于 nums[4]=3 存在三个比它小的数字:(1,2 和 2)。
示例2:
输入:nums = [6,5,4,8]
输出:[2,1,0,3]
示例3:
输入:nums = [7,7,7,7]
输出:[0,0,0,0]
提示:
2 <= nums.length <= 5000 <= nums[i] <= 100
解法1(暴力法)
暴力法思路很简单粗暴,就是拿每一个元素跟数组中除了自身之外的每一个元素对比,只要元素大于数组中其他的数就计数加一,最后把计数收集起来就是结果。
代码如下:
public int[] smallerNumbersThanCurrent(int[] nums) {
int[] res = new int[nums.length];
int count = 0;
for (int i = 0; i < nums.length; i++) {
int num = nums[i];
for (int j = 0; j < nums.length; j++) {
//排除跟自己对比
if (i == j) {
continue;
}
//如果元素本身比其他数要大,计数+1
if (num > nums[j]) {
count++;
}
}
//收集计数
res[i] = count;
//计数器归0
count = 0;
}
return res;
}
提交代码,结果如下:
解法2
明显解法1使用了嵌套循环,导致耗时太多,结果不太理想。优化代码前,我们可以先看看提示0 <= nums[i] <= 100,也就是说元素的值在0到100范围内。我们可以使用一个101长度的数组统计元素出现的次数,当我们要计算有多少少于该元素的数字时,就只需要该元素前面所有元素出现的次数即可。
代码如下:
public int[] smallerNumbersThanCurrent(int[] nums) {
int[] hash = new int[101];
//使用数组统计数字出现的次数
for (int num : nums) {
//元素值相当于下标,类似于哈希映射
hash[num]++;
}
int[] res = new int[nums.length];
for (int i = 0; i < nums.length; i++) {
//计数
int count = 0;
//统计在该元素前的所有元素(也就是小于该元素的数字)出现的次数
for (int j = nums[i] - 1; j >= 0; j--) {
//计数器累加,j就是统计哈希表的下标
count += hash[j];
}
res[i] = count;
}
return res;
}
提交代码,结果如下:
389. 找不同
题目:
给定两个字符串 s 和 t,它们只包含小写字母。
字符串 t 由字符串 s 随机重排,然后在随机位置添加一个字母。
请找出在 t 中被添加的字母。
示例1:
输入:s = "abcd", t = "abcde"
输出:"e"
解释:'e' 是那个被添加的字母。
示例2:
输入:s = "", t = "y"
输出:"y"
示例3:
输入:s = "a", t = "aa"
输出:"a"
提示:
0 <= s.length <= 1000t.length == s.length + 1s和t只包含小写字母
解法1(HashMap)
使用HashMap记录字符串s中每一个字符出现的次数,然后遍历字符串t,通过字符获取字符出现的次数,次数大于0就减一,次数等于0则表示是添加的字母,返回该字母。
代码如下:
public char findTheDifference(String s, String t) {
Map<Character, Integer> map = new HashMap<>();
for (char c : s.toCharArray()) {
map.put(c, map.getOrDefault(c, 0) + 1);
}
for (char c : t.toCharArray()) {
Integer count = map.getOrDefault(c, 0);
if (count > 0) {
map.put(c, count - 1);
} else {
return c;
}
}
return ' ';
}
提交代码,结果如下:
解法2
关键是抓住提示,字符串s和t只包含小写字母,所以我们还是可以使用数组简化HashMap。小写字母只有26个,所以我们创建一个26长度的int数组,统计s字符串中字符出现的次数。其他逻辑和解法1一样即可。
代码如下:
public char findTheDifference(String s, String t) {
int[] hash = new int[26];
for (char c : s.toCharArray()) {
hash[c - 'a']++;
}
for (char c : t.toCharArray()) {
if (hash[c - 'a'] > 0) {
hash[c - 'a']--;
} else {
return c;
}
}
return ' ';
}
提交代码,结果如下:

解法3(排序法)
把两个字符串转成字符数组,然后对两个数组排序。对排序好的数组进行遍历对比,只要出现不相等的字符,就是要返回的字符。
代码如下:
public char findTheDifference(String s, String t) {
char[] sChars = s.toCharArray();
char[] tChars = t.toCharArray();
Arrays.sort(sChars);
Arrays.sort(tChars);
int length = Math.min(sChars.length, tChars.length);
int i = 0;
while (i < length) {
char sChar = sChars[i];
char tChar = tChars[i];
if (sChar != tChar) {
return tChar;
}
i++;
}
return tChars[tChars.length - 1];
}
提交代码,结果如下:
效率虽然没有哈希表快,但是也是一种不错的解题思路。
217. 存在重复元素
题目:
给定一个整数数组,判断是否存在重复元素。
如果存在一值在数组中出现至少两次,函数返回 true 。如果数组中每个元素都不相同,则返回 false 。
示例1:
输入: [1,2,3,1]
输出: true
示例2:
输入: [1,2,3,4]
输出: false
示例3:
输入: [1,1,1,3,3,4,3,2,4,2]
输出: true
解法1
假如使用嵌套循环,是会超出时间限制的,所以不能考虑用暴力法。一般来说,判断一个元素是否包含在其中肯定是HashSet最快,所以我们可以用HashSet容纳元素,然后判断一下是否包含,包含则返回true,不包含则继续装入,如果遍历结束都没有返回true,则返回false。
代码如下:
public boolean containsDuplicate(int[] nums) {
Set<Integer> set = new HashSet<>();
for (int num : nums) {
if (!set.contains(num)) {
set.add(num);
} else {
return true;
}
}
return false;
}
提交代码,结果如下:
解法2
其实HashSet本身就有去重的效果,我们把所有的元素装入到HashSet中,如果有重复的元素则长度和原来的长度不相等。
代码如下:
public boolean containsDuplicate(int[] nums) {
Set<Integer> set = new HashSet<>();
for (int num : nums) {
set.add(num);
}
return set.size() != nums.length;
}
提交代码,结果如下:
409. 最长回文串
题目:
给定一个包含大写字母和小写字母的字符串,找到通过这些字母构造成的最长的回文串。
在构造过程中,请注意区分大小写。比如 "Aa" 不能当做一个回文字符串。
注意:
假设字符串的长度不会超过 1010。
示例1:
输入:
"abccccdd"
输出:
7
解释:
我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。
解法1
回文字符串就是从左往右读和从右往左读都是一样的字符串,也就是左右对称的字符串。要做到左右对称,其实很简单,只要是偶数个相同的字符就可以,比如有两个"a",左右两端各放一个就对称了。
所以我们用一个HashMap来统计字符出现的次数,然后遍历,判断如果是偶数就累加字母出现的次数,如果是奇数就减一让他变成偶数再累加,最后就得到答案res,但是还没大功告成,因为中点插进一个字母,他还是对称的,所以最后要判断一下累加的长度是否等于原来的字符串长度,再决定要不要再加上一个字母的长度。
代码如下:
public int longestPalindrome(String s) {
HashMap<Character, Integer> map = new HashMap<>();
//统计字符出现的次数
for (char c : s.toCharArray()) {
map.put(c, map.getOrDefault(c, 0) + 1);
}
int res = 0;
for (Character key : map.keySet()) {
Integer val = map.get(key);
//如果是奇数次,减一成为偶数,再累加
if (val % 2 != 0) {
res += (val - 1);
} else {
//如果是偶数次,直接累加
res += val;
}
}
int length = s.length();
return res == length ? length : (res + 1);
}
提交代码,结果如下:
解法2(优化)
题目说明是包含大写字母和小写字母,所以我们还是可以使用数组来代替HashMap,以此提高代码的执行效率。我们只需要一个长度为128的数组来统计字符出现的次数,代替HashMap。其他逻辑不变即可。
代码如下:
public int longestPalindrome(String s) {
int[] hash = new int[128];
for (char c : s.toCharArray()) {
hash[c - 'A']++;
}
int res = 0;
for (int count : hash) {
if (count % 2 != 0) {
res += (count - 1);
} else {
res += count;
}
}
int length = s.length();
return res == length ? length : (res + 1);
}
提交代码,结果如下:

204. 计数质数
统计所有小于非负整数 n 的质数的数量。
示例1:
输入:n = 10
输出:4
解释:小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。
示例2:
输入:n = 0
输出:0
示例3:
输入:n = 1
输出:0
解法1(暴力法)
其实这是一个很经典的数学问题,比如要判断223是不是质数,最粗暴的方法就是,223对(2到222)进行取余,每次取余的余数都不为0,那就是质数。但是如果n的值非常大,那就会超过时间限制。
代码如下:
public int countPrimes(int n) {
int count = 0;
for (int i = 0; i < n; i++) {
//判断是否是质数,是质数则计数+1
if (isPrimes(i)) {
count++;
}
}
return count;
}
//判断一个数是否是质数
private boolean isPrimes(int num) {
if (num <= 1) {
return false;
}
if (num == 2) {
return true;
}
//循环取余,只要有一次返回余数为0则是非质数
for (int i = 2; i < num; i++) {
if (num % i == 0) {
return false;
}
}
//如果余数都不为0则是质数
return true;
}
提交代码,结果如下:
解法2
不如反向思维一下,我们使用一个boolean[]数组记录每个数是否是质数,然后从2开始找出非质数都标记成true,标记完成之后就可以统计质数的数量是多少了。
public int countPrimes(int n) {
boolean[] booleans = new boolean[n];
for (int i = 2; i < n; i++) {
for (int j = 2; j * i < n; j++) {
booleans[i * j] = true;
}
}
int count = 0;
//从2开始统计
for (int i = 2; i < booleans.length; i++) {
if (!booleans[i]) {
count++;
}
}
return count;
}
提交代码,结果如下:
其实上面的代码还可以优化一下,不需要遍历两次,把统计和标记放在一个循环即可。代码如下:
public int countPrimes(int n) {
int count = 0;
boolean[] booleans = new boolean[n];
for (int i = 2; i < n; i++) {
if (!booleans[i]) {
for (int j = 2; j * i < n; j++) {
booleans[i * j] = true;
}
count++;
}
}
return count;
}
提交代码,结果如下:
解法3
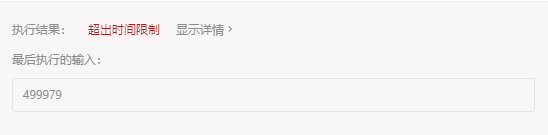
万万没想到,这个题目还有0ms的题解!这是我在提交记录中一不留神看到的,截图给大伙看看。
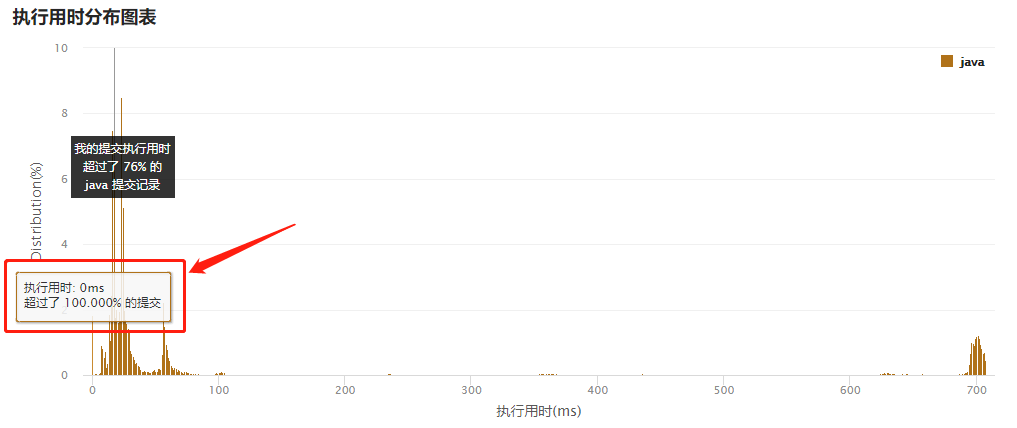
然后我点开代码一看,好家伙,震惊我一整年!
public int countPrimes(int n) {
switch (n) {
case 0: return 0;
case 1: return 0;
case 2: return 0;
case 3: return 1;
case 4: return 2;
case 5: return 2;
case 6: return 3;
case 7: return 3;
case 8: return 4;
case 9: return 4;
case 10: return 4;
case 11: return 4;
case 12: return 5;
case 13: return 5;
case 14: return 6;
case 15: return 6;
case 10000: return 1229;
case 499979: return 41537;
case 999983: return 78497;
case 1500000: return 114155;
case 5000000: return 348513;
default: return -1;
}
}
我当然不相信这是能通过的啦,于是复制了这段代码提交试试,没想到还真行呀!

总结
哈希表的算法题中有很多问题其实在实际项目中也会遇到,比如找出两个集合的交集,找出集合中重复的元素等等,所以做一做算法题对我们的编码能力会有很大的提升。
这篇文章讲到这里了,感谢大家的阅读,希望看完这篇文章能有所收获!
觉得有用就点个赞吧,你的点赞是我创作的最大动力~
我是一个努力让大家记住的程序员。我们下期再见!!!
能力有限,如果有什么错误或者不当之处,请大家批评指正,一起学习交流!