
一文看完吴恩达最新演讲精髓,人工智能部署的三大挑战及解决方案

新智元报道
【新智元导读】AI算法研究的进展似乎已经到了一个瓶颈期,现在许多公司和研究团队正在努力将研究转化为实际的生产部署。吴恩达(Andrew Ng)最近在斯坦福大学的一个线上的演讲中,分享了一些他认为有趣的观点。
Andrew这次演讲的主题是「Bridging AI's Proof-of-Concept to Production Gap」,即「将人工智能的概念验证与生产差距连接起来」,提出了人工智能部署面临的三个调整和解决的方案,并解答了一些问题。
人工智能部署面临的三大挑战
人工智能部署面临的三大挑战
1.小数据(Small data:Moving beyond big data)
当今很多互联网公司的人工智能算法研究通常使用的是「Big Data」,因为用户产生了很多的数据可供模型训练,而小数据在消费者互联网之外的工业应用领域中却很常见。
智能手机上的各种APP,因为「拿到」了数以亿计的用户数据,所以训练出一个效果很好的神经网络是非常简单的。
但是如何使用小数据来让很多其他行业也能得到效果不错的模型,将是未来的AI发展面临的一个挑战。
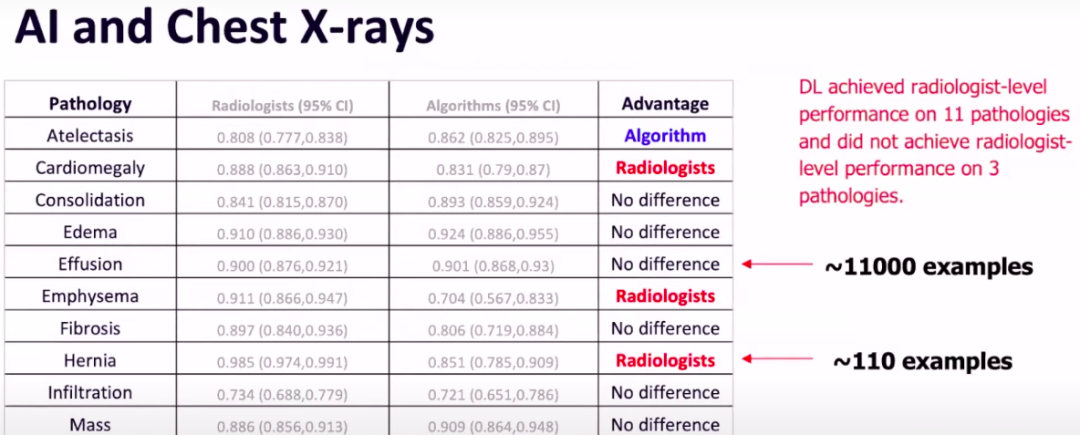
例如在做X射线的时候,当样本量达到11000时,AI算法的诊断结果和放射科专家的结果是没有区别的,但在数据量很小的时候,放射科医生的准确率就会远大于模型的结果。
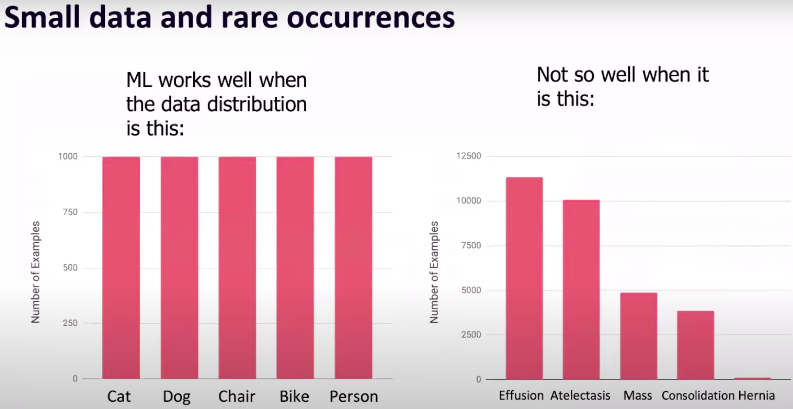
吴恩达指出,当数据分布大致呈现出均匀分布的时候,模型的效果通常是不错的,但是当模型的分布非常不均匀的时候,机器学习算法的效果就会差强人意,这正是人工智能在医疗领域面临的一个重大问题。
如上图所示,「Hernia」是一种罕见的案例,统计数据量非常少,忽略不计对模型准确度的影响不大,但是在医疗领域,「Hernia」作为一种症状,是绝对不可以被忽略的。
就像他经常听到很多的有趣对话一样,通常算法工程师在炫耀说:「快看我的模型在测试集上得到了非常高的准确率」,而医生则通常会说:「恭喜你的算法取得了很好的效果,并且能发论文了,但是你的系统不能用」。
而这种结果就导致了人工智能面临的第二个挑战。
2.算法的鲁棒性和泛化性(Generalizability and robustness)
一个模型通常在已发表的论文中work,而在实际生产环境中通常不work。

而这种情况不仅仅只发生在医疗领域,在其他的领域中也非常常见。很多情况下,当你使用了一个完全不同的数据集,模型的泛化能力就会大大降低。
3.变革管理(Change management:manage the change the technology brings)
在自动化工作流中,一个部分使用的模型可能会潜在地影响整个系统和许多其他相关方。

吴恩达举了一个姑息疗法(Palliative care,也叫临终关怀)的例子:在美国,很多医生虽然非常的关注自己的病人,但是由于医生人数的短缺,他们却很少会去做Palliative care。

而通过人工智能设计的系统,医生们可以了解到每一位病人的死亡率,可以更高效的辅助他们的工作。
同时,在医疗系统中,「可解释AI」的作用非常重要,因为医生是无法轻易信任一个黑盒算法给出的结果的。
最后,吴恩达还指出,机器学习的代码(ML Code)只是解决问题的非常小的一部分,需要很多环节形成一个整体的闭环。
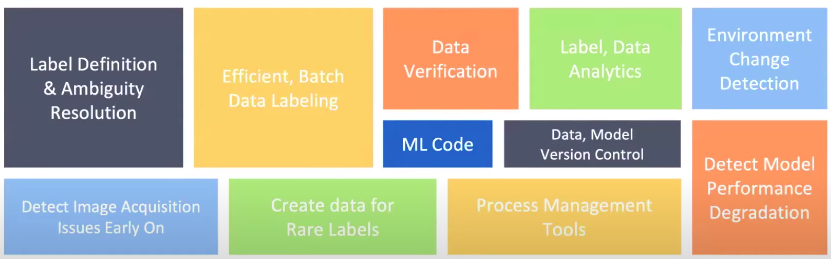
应对挑战的解决方案
应对挑战的解决方案
通常来讲,一个AI项目的整体流程包括如下几个阶段: 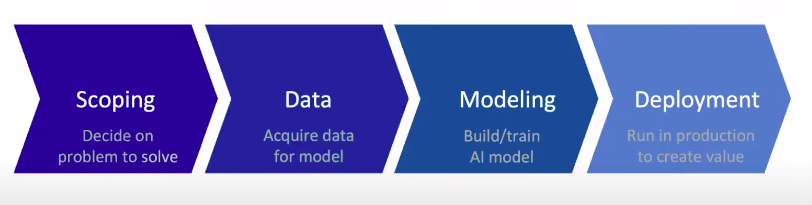 完成一个项目需要系统地规划机器学习项目的整个周期,从范围到数据、建模和部署。
完成一个项目需要系统地规划机器学习项目的整个周期,从范围到数据、建模和部署。

在部署阶段,吴恩达指出了一种「Shadow deployment」的方法,就像在放射科使用AI系统一样,算法本身不会做出任何的决策,只会用来辅助医生得到诊断结果。
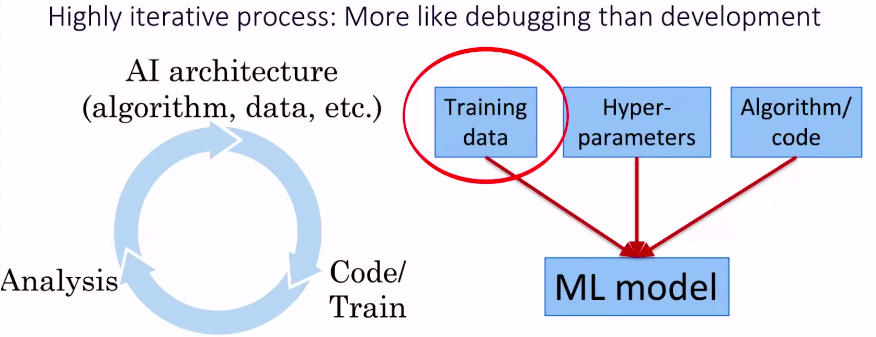
在模型构建和训练的阶段,Andrew提出了训练数据的重要性,在训练阶段使用一些现成的数据集得出的模型并不一定在实际使用中有很好的泛化能力。

在数据方面,「不要等待找到完美的数据才开始行动」,这是Andrew接触过的很多CEO经常会犯的错误。

吴恩达还指出,AI解决问题不可以凭空想象,一定要结合各个行业的实际痛点,解决对商业有价值的需求。
演讲的最后,他还分享了一个麦肯锡的调研图表:

结果显示,AI所能做的领域远不止消费电子行业,其他领域也有非常广阔的市场空间。
完整版视频地址放送如下:
https://crossminds.ai/video/5f9a11f026cd723d6a05efa4/?timecode=1134.021093202179&&utm_campaign=bc839cc127703d0c&utm_medium=share

