
Python 万能代码模版:数据可视化篇
“阅读本文大概需要6分钟”
上一篇,我写了:Python 万能代码模版:爬虫代码篇 接下来,是第二个万能代码,数据可视化篇。
其实,除了使用 Python 编写爬虫来下载资料, Python 在数据分析和可视化方面也非常强大。往往我们在工作中需要经常使用 Excel 来从表格生成曲线图,但步骤往往比较繁琐,而用 Python 则可以轻松实现。
1. 从 csv 或 excel 提取数据来画图
本节需要先安装 pandas 、matplotlib、seaborn
pip install pandas matplotlib seaborn
我们以刚才创建的 tips_2.xlsx 这个 excel 为例,来介绍我们如何把 Excel 表格中的数据画成图。
tips_2.xlsx 是上一篇我们生成的:Python 万能代码模版:爬虫代码篇
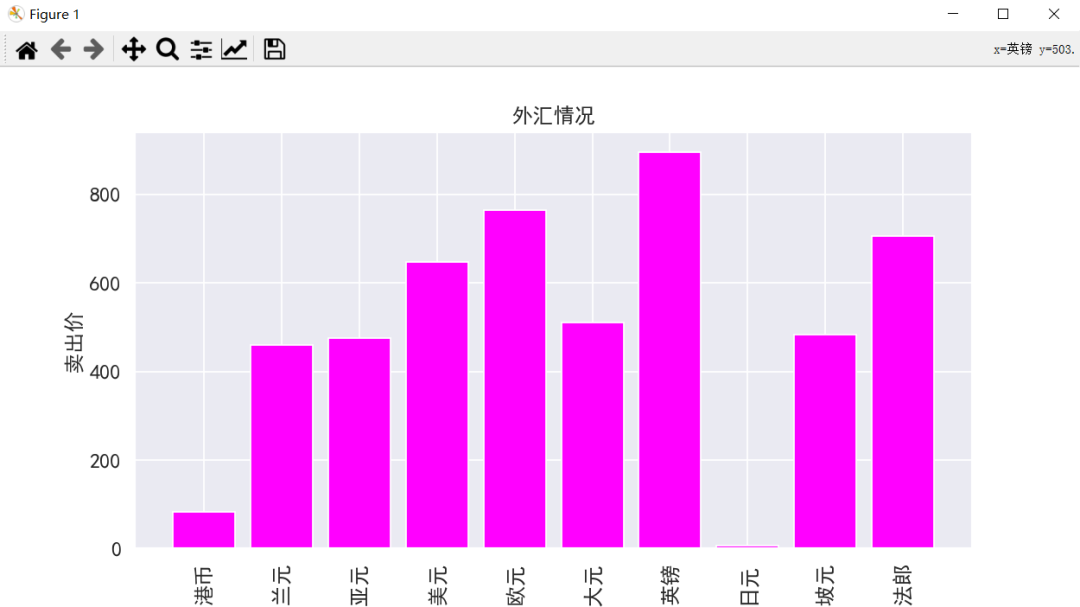
我们这次将 excel 中的卖出价一列,生成柱状图。
代码如下所示:
# -*- coding: utf-8 -*-
# @Author: AI悦创
# @Date: 2021-09-14 21:56:37
# @Last Modified by: aiyc
# @Last Modified time: 2021-09-15 14:27:22
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
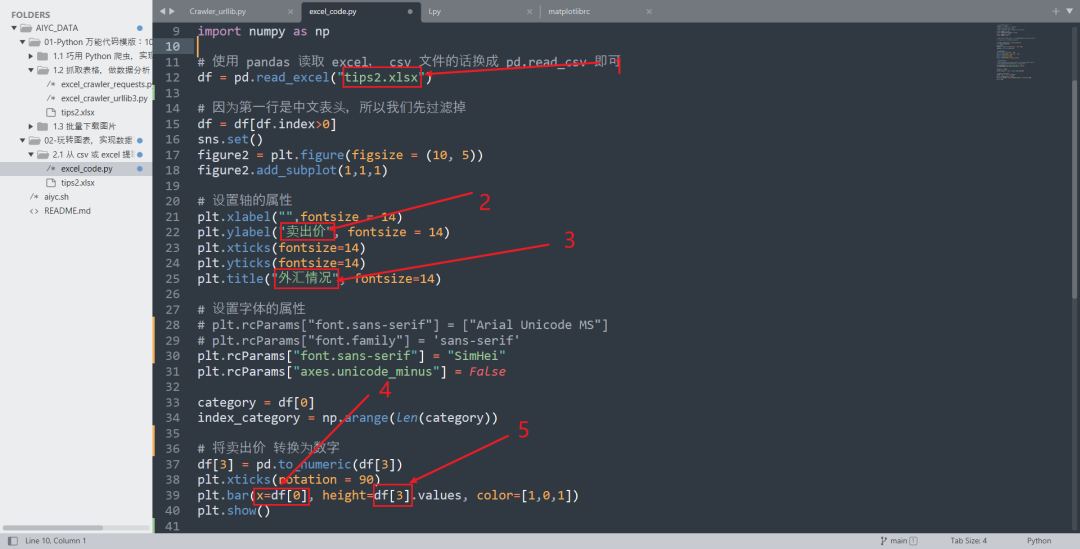
# 使用 pandas 读取 excel, csv 文件的话换成 pd.read_csv 即可
df = pd.read_excel("tips2.xlsx")
# 因为第一行是中文表头,所以我们先过滤掉
df = df[df.index>0]
sns.set()
figure2 = plt.figure(figsize = (10, 5))
figure2.add_subplot(1,1,1)
# 设置轴的属性
plt.xlabel("",fontsize = 14)
plt.ylabel("卖出价", fontsize = 14)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.title("外汇情况", fontsize=14)
# 设置字体的属性
# plt.rcParams["font.sans-serif"] = ["Arial Unicode MS"]
# plt.rcParams["font.family"] = 'sans-serif'
plt.rcParams["font.sans-serif"] = "SimHei"
plt.rcParams["axes.unicode_minus"] = False
category = df[0]
index_category = np.arange(len(category))
# 将卖出价 转换为数字
df[3] = pd.to_numeric(df[3])
plt.xticks(rotation = 90)
plt.bar(x=df[0], height=df[3].values, color=[1,0,1])
plt.show()
输出如下所示:
替换说明:
替换要画图的 excel 文件夹名称
Y 轴的标题
图的标题
横轴的数据(第几列做横轴)
纵轴的数据(第几列做纵轴)
代码: https://github.com/AndersonHJB/AIYC_DATA/tree/main/02-玩转图表,实现数据可视化/2.1%20从%20csv%20或%20excel%20提取数据来画图
2. 从文本文件中生成词云
需要先安装 wordcloud,jieba
pip install wordcloud jieba
词云是最近数据分析报告中非常常见的数据表现形式了,它会从一段文字中抽取出高频的词汇并且以图片的形式将它们展示出来。
如何用 Python 生成词云呢?
为了做示范,我们首先解析第一步我们抓取的 tips_1.html 网页(考研网),将所有的新闻标题都存储到一个文本文档中。
代码如下:
# -*- coding: utf-8 -*-
# @Author: AI悦创
# @Date: 2021-09-15 22:15:30
# @Last Modified by: aiyc
# @Last Modified time: 2021-09-15 23:12:34
from bs4 import BeautifulSoup
# 输入参数为要分析的 html 文件名,返回值为对应的 BeautifulSoup 对象
def create_doc_from_filename(filename):
with open(filename, "r", encoding='utf-8')as f:
html_content = f.read()
doc = BeautifulSoup(html_content, "lxml")
return doc
def parse(doc):
post_list = doc.find_all("div",class_="post-info")
result = []
for post in post_list:
link = post.find_all("a")[1]
result.append(link.text.strip())
result_str="\n".join(result)
with open("news_title.txt", "w", encoding='utf-8') as fo:
fo.write(result_str)
def main():
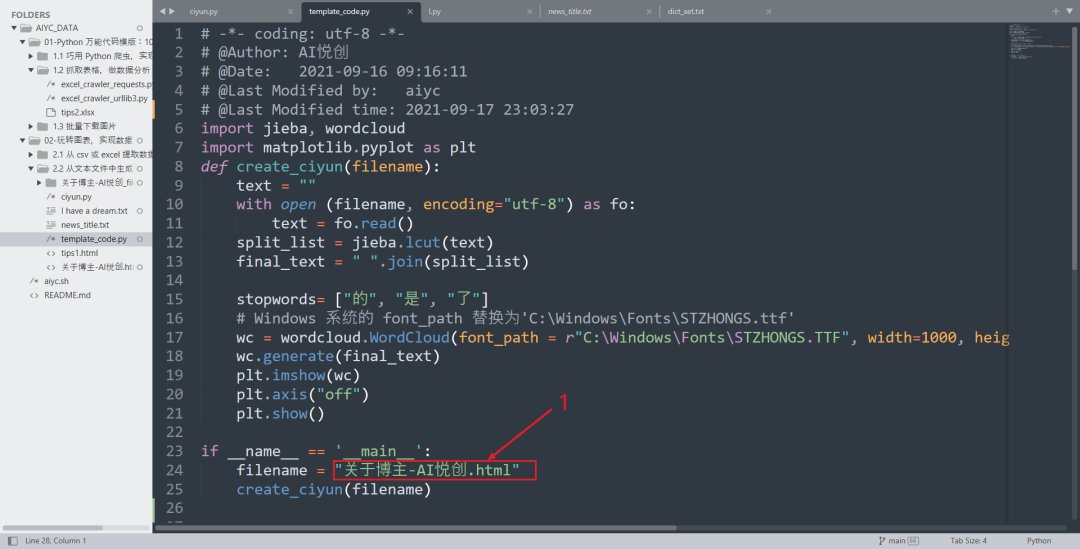
filename = "tips1.html"
doc = create_doc_from_filename(filename)
parse(doc)
if __name__ == '__main__':
main()
接下来我们将 news_title.txt 这个文本文件中的汉字进行分词,并生成词云。代码如下:
import jieba
import wordcloud
import matplotlib.pyplot as plt
def create_ciyun():
text = ""
with open ("news_title.txt", encoding="utf-8") as fo:
text = fo.read()
split_list = jieba.lcut(text)
final_text = " ".join(split_list)
stopwords= ["的", "是", "了"]
# Windows 系统的 font_path 替换为'C:\Windows\Fonts\STZHONGS.ttf'
wc = wordcloud.WordCloud(font_path = r"C:\Windows\Fonts\STZHONGS.TTF", width=1000, height=700, background_color="white",max_words=100,stopwords = stopwords)
wc.generate(final_text)
plt.imshow(wc)
plt.axis("off")
plt.show()
然后,在 main 函数中调用:
def main():
filename = "tips1.html"
doc = create_doc_from_filename(filename)
parse(doc)
create_ciyun()
为了方便阅读,这里我也把整合好的代码放出来:
# -*- coding: utf-8 -*-
# @Author: AI悦创
# @Date: 2021-09-15 22:15:30
# @Last Modified by: aiyc
# @Last Modified time: 2021-09-15 23:21:44
import jieba
import wordcloud
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
# 输入参数为要分析的 html 文件名,返回值为对应的 BeautifulSoup 对象
def create_doc_from_filename(filename):
with open(filename, "r", encoding='utf-8')as f:
html_content = f.read()
doc = BeautifulSoup(html_content, "lxml")
return doc
def parse(doc):
post_list = doc.find_all("div",class_="post-info")
result = []
for post in post_list:
link = post.find_all("a")[1]
result.append(link.text.strip())
result_str="\n".join(result)
with open("news_title.txt", "w", encoding='utf-8') as fo:
fo.write(result_str)
def create_ciyun():
text = ""
with open ("news_title.txt", encoding="utf-8") as fo:
text = fo.read()
split_list = jieba.lcut(text)
final_text = " ".join(split_list)
stopwords= ["的", "是", "了"]
# Windows 系统的 font_path 替换为'C:\Windows\Fonts\STZHONGS.ttf'
wc = wordcloud.WordCloud(font_path = r"C:\Windows\Fonts\STZHONGS.TTF", width=1000, height=700, background_color="white",max_words=100,stopwords = stopwords)
wc.generate(final_text)
plt.imshow(wc)
plt.axis("off")
plt.show()
def main():
filename = "tips1.html"
doc = create_doc_from_filename(filename)
parse(doc)
create_ciyun()
if __name__ == '__main__':
main()
不过还是建议阅读源代码文件,源代码文件我此片段最后会放出来。
输出结果如下:
 如果你想生成自己的词云,首先你需要想清楚你的数据来源,一般是一个网页或者一个文本文件。
如果你想生成自己的词云,首先你需要想清楚你的数据来源,一般是一个网页或者一个文本文件。
如果是网页的话可以首先保存到本地,提取文本,之后就可以进行代码替换来生成了。(对于网页文件,需要自行提取文本咯,实在不会就把网页的文件的内容,复制出来。保存成 .txt格式文件。如果是文本,直接复制在 text,再执行下文即可。)
我们代码模板,实际是下面这个模板:
def create_ciyun():
text = ""
with open ("news_title.txt", encoding="utf-8") as fo:
text = fo.read()
split_list = jieba.lcut(text)
final_text = " ".join(split_list)
stopwords= ["的", "是", "了"]
# Windows 系统的 font_path 替换为'C:\Windows\Fonts\STZHONGS.ttf'
wc = wordcloud.WordCloud(font_path = r"C:\Windows\Fonts\STZHONGS.TTF", width=1000, height=700, background_color="white",max_words=100,stopwords = stopwords)
wc.generate(final_text)
plt.imshow(wc)
plt.axis("off")
plt.show()
替换说明:
替换为你准备的网页或者文本文件的文件名。
PS:上面的模板生成的词语适合非专业的使用,毕竟如果要较真的话,还是很糙的。
代码:https://github.com/AndersonHJB/AIYC_DATA/tree/main/02-玩转图表,实现数据可视化/2.2%20从文本文件中生成词云
“AI悦创·推出辅导班啦,包括「Python 语言辅导班、C++辅导班、算法/数据结构辅导班、少儿编程、pygame 游戏开发」,全部都是一对一教学:一对一辅导 + 一对一答疑 + 布置作业 + 项目实践等。QQ、微信在线,随时响应!V:Jiabcdefh
”
黄家宝丨AI悦创
隐形字
摄影公众号「悦创摄影研习社」
在这里分享自己的一些经验、想法和见解。


长按识别二维码关注