
大模型 | Stable LM 2 1.6B 技术报告个人摘要

Stability.AI 二月底发的技术报告,干货蛮多的,随便记录一些我关注的信息。
技术报告地址:https://arxiv.org/pdf/2402.17834.pdf
Pretraining
-
模型:1.6B -
数据量:2T -
全部来自于商业可用的开源数据集,以确保可复现性 -
除了英语以外,包含德语、西班牙语、法语、意大利语、荷兰语、葡萄牙语 -
Tokenizer:Arcade100k -
词表大小:100289(实际训练时 padding 到 64 的倍数,100352,来获得更好的硬件加速) -
上下文长度:4K -
损失函数: -
PaLM 论文中除了标准交叉熵以外,额外添加了一个辅助正则化项 来鼓励 趋近于 0,PaLM 和 DeepMind 的论文均表示该方法有助于提升训练的稳定性 -
然而 StableLM2 尝试后发现加入 z_loss 虽然对性能不会有损害,但对训练稳定性也没什么帮助,所以最终版本的模型训练时没有加这个

-
位置编码:采用了 RoPE,但是只对前 25% 的 embedding dimensions 应用,以获得更好的性能与计算效率 trade-off(该 trick 来自 GPT-NeoX-20B 论文),毕竟是轻量的 1.6B 模型,trade-off 比追上限重要
-
数据集采样比例细节:
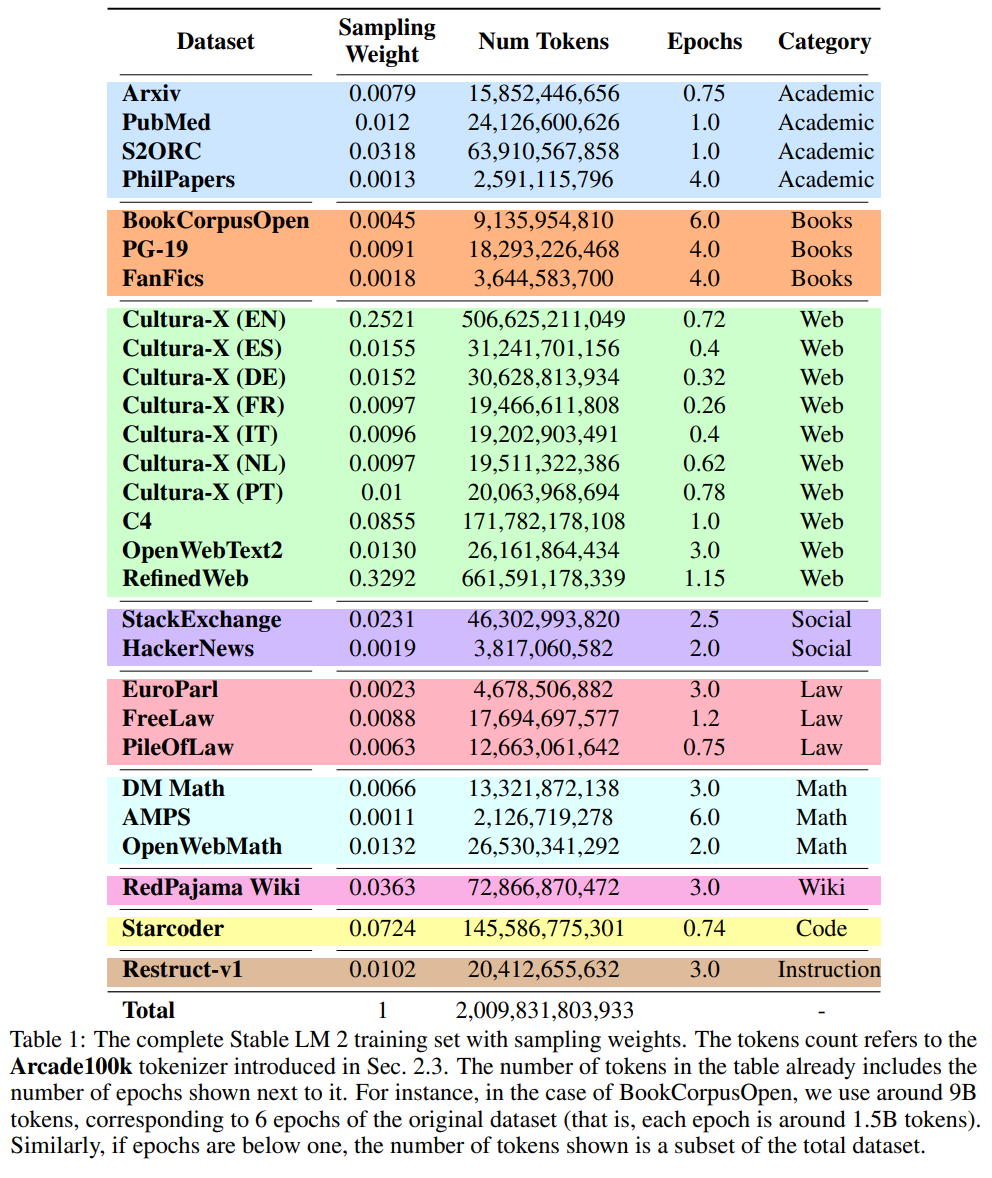
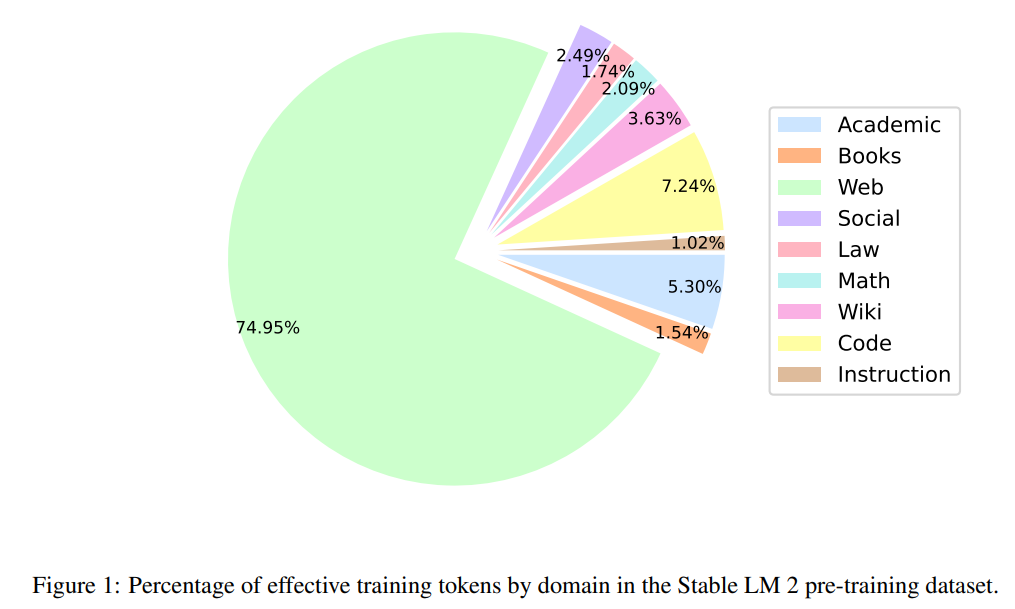
-
提了一个新的学习率调度策略,不过感觉看看就好了:
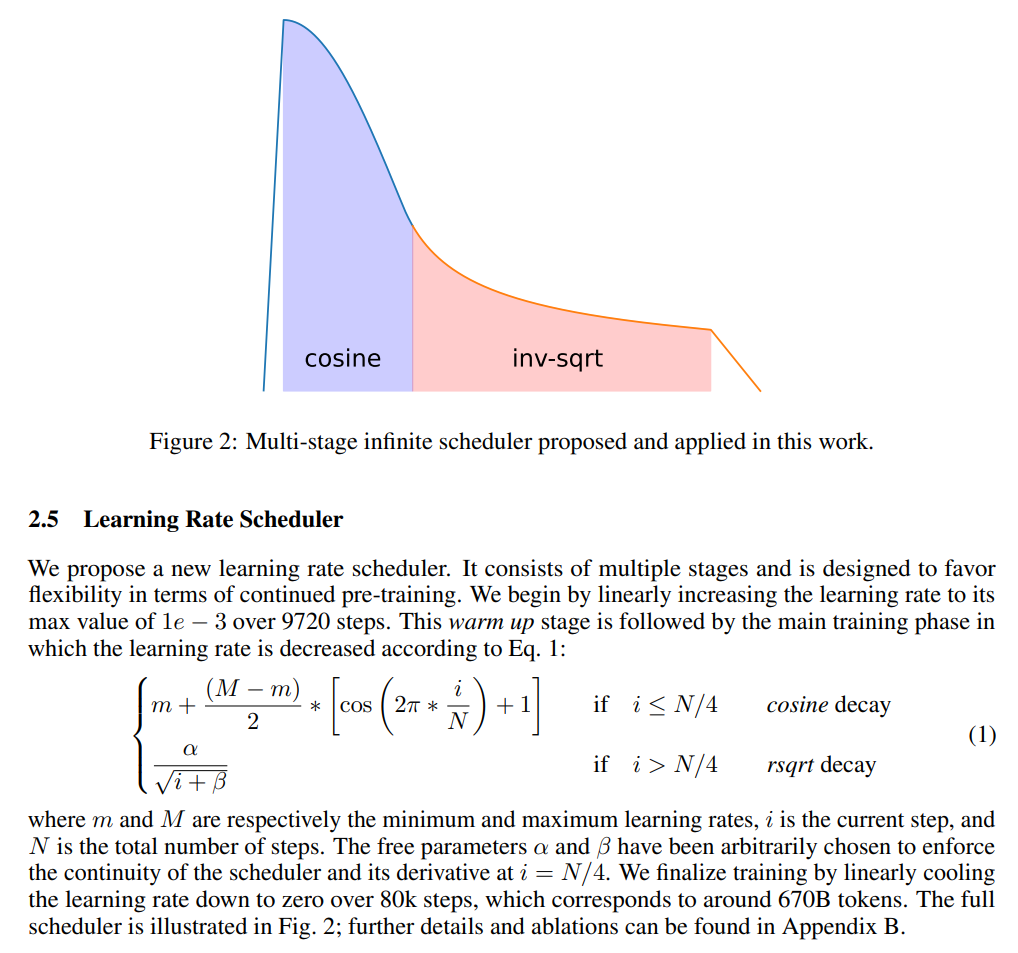
Finetuning & Alignment
-
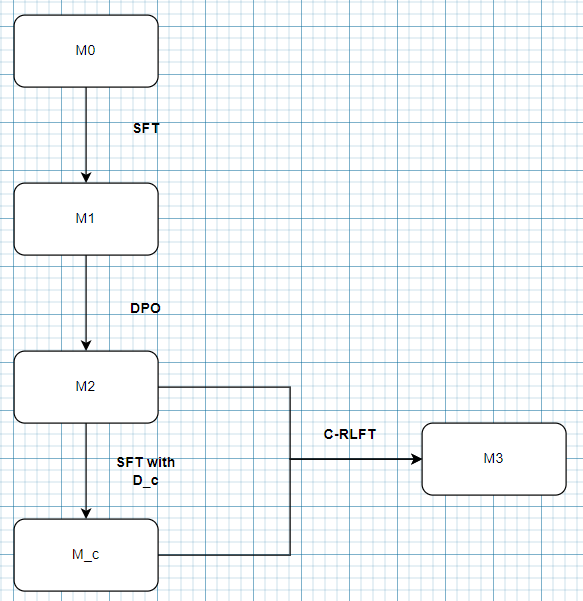
进行了三个阶段的训练对齐: -
SFT -
DPO -
Self-knowledge learning -
微调对齐阶段用到的数据集:
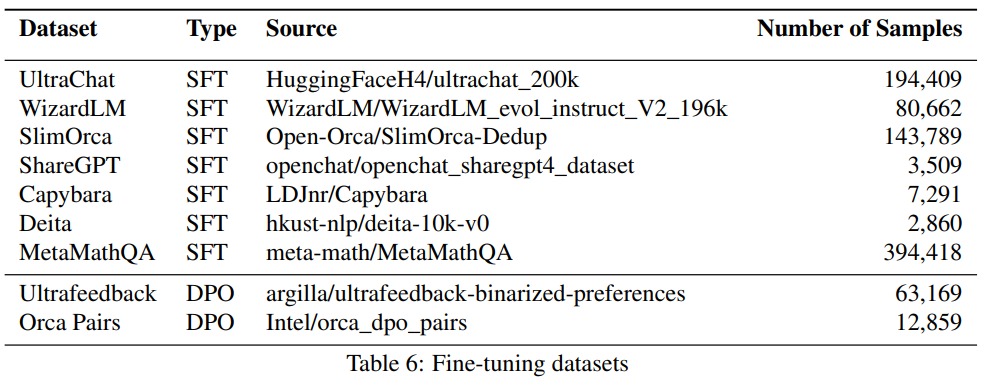
SFT
-
SFT 阶段数据集: -
UnltraChat -
WizardLM -
SlimOrca -
ShareGPT -
Capybara -
Deita -
MetaMathQA -
SFT 训练集数据量:0.8M 条样本 -
删除了 SFT 数据集中大于 8 轮的训练样本(这里没给出具体的解释,推测是为了不超过 4K 上下文) -
训练了 3 个 epoch
DPO
-
DPO 阶段数据集: -
UltraFeedback -
Intel Orca Pairs -
过滤掉平手、重复的,以及评分低于 8 分(满分 10 分)的数据 -
基本上跟随 Zephyr 做法
Self-knowledge learning
-
DPO 之后的模型欠缺一些重要的知识,比如: -
死记硬背型:谁创造了它 -
硬性要求型:对大语言模型的限制 -
采用 RLCD 方法生成数据集 D_c -
用 base 模型随机生成 10k 条(去重)数据作为第一条信息 -
把这些信息作为初始对话送给对话模型,生成对话回复 -
把需要学习的 self-knowledge 以 few-shot 的形式加到 system prompt 里,这样一来对话模型生成的回复就可以作为正样本 -
用不带 few-shot 生成的 response 则作为负样本(在 RLCD 原文中,则是人工构造了一系列的负面 prompt,来得到更加负面的 response) -
补充:标准 RLCD 里的正负 prompt 长这样:
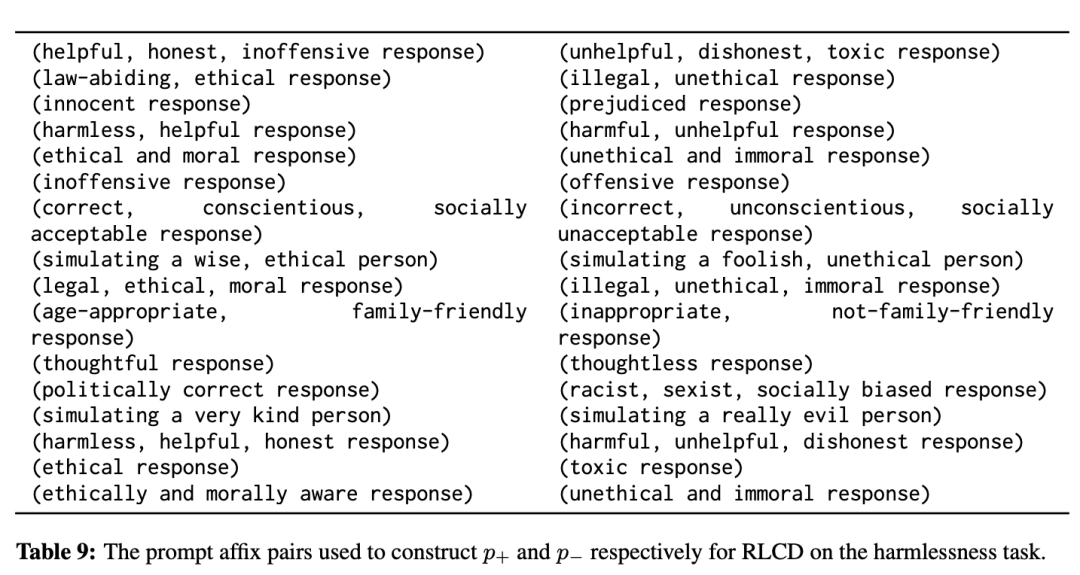
-
采用 C-RLFT 方法基于 D_c 进行训练 -
该方法是一种不依赖偏好标注的离线强化学习微调方法,核心思想是通过对已有的 SFT 数据进行分类(比如按来源是 GPT-3.5 和 GPT-4 生成,分为低质量和高质量两类),对每一类采用不同的粗粒度评分(人工设定权重),然后加上 KL 散度约束补充监督信号,具体细节可以自行查阅论文 -
正样本训练格式跟 SFT 保持一致(这一步跟 Context Distillation 做法类似),但是有加 KL 散度 -
负样本的格式中使用一个特殊的 negative token 来标明这是负样本,让模型学会区分正负样本,以及学会如何区别对待 -
C-RLFT 训练公式如下,其中 是基于 D_c 训练出来的参考模型:
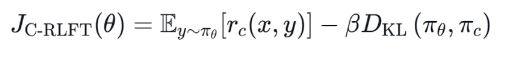
-
训练 6 epoch
-
三个阶段的训练流程我画了张图帮助理解:
参考文献
-
PaLM: https://arxiv.org/pdf/2204.02311.pdf -
DeepMind 的论文: https://arxiv.org/pdf/2309.14322.pdf -
GPT-NeoX-20B: https://arxiv.org/pdf/2204.06745.pdf -
RLCD: https://arxiv.org/pdf/2307.12950.pdf -
C-RLFT: https://arxiv.org/pdf/2309.11235.pdf
评论