
来聊聊可形变卷积及其应用
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


转载自AI算法修炼营
使用可变形卷积,可以提升Faster R-CNN和R-FCN在物体检测和分割上的性能。只要增加很少的计算量,就可以得到性能的提升。
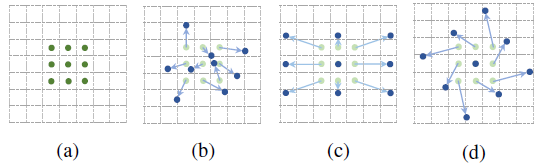
(a) Conventional Convolution, (b) Deformable Convolution, (c) Special Case of Deformable Convolution with Scaling, (d) Special Case of Deformable Convolution with Rotation
传统/常规卷积基于定义的滤波器大小,在输入图像或一组输入特征图的预定义矩形网格上操作。该网格的大小可以是3×3和5×5等。然而,我们想要检测和分类的对象可能会在图像中变形或被遮挡。
在DCN中,网格是可变形的,因为每个网格点都可以通过一个可学习的偏移量移动。卷积作用于这些移动的网格点上,因此称为可变形卷积,类似于可变形RoI池化的情况。通过使用这两个新模块,DCN提高了DeepLab、Faster R-CNN、R-FCN、和FPN等的准确率。
最后,MSRA使用DCN+FPN+Aligned Xception在COCO Detection Challenge中获得第二名,Segmentation Challenge中获得第三名。发表于2017 ICCV,引用次数超过200次。
1.1 可变形卷积
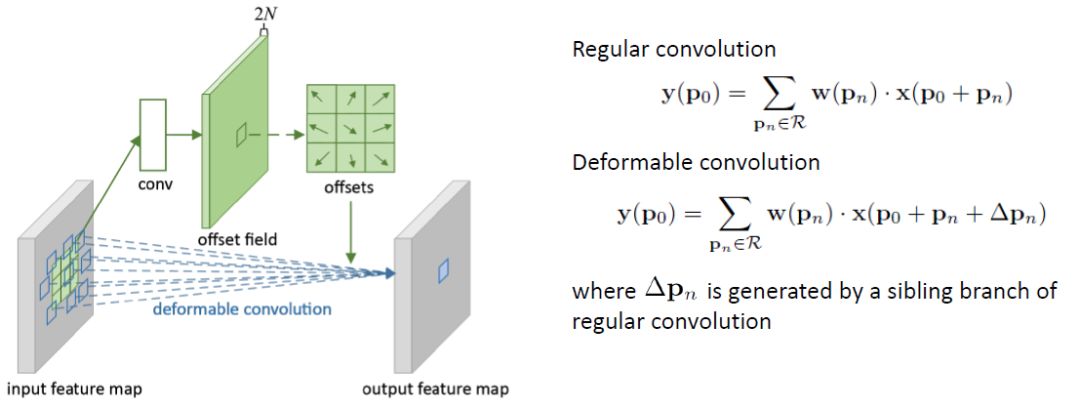
可变形卷积
规则的卷积是在一个规则的网格R上操作的。
对R进行可变形卷积运算,但每个点都增加一个可学习的偏移∆pn。
卷积生成2N个特征图,对应N个2D个偏移量∆pn(每个偏移量对应有x-方向和y-方向)。
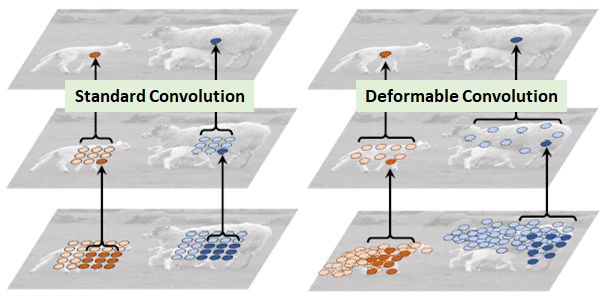
如上所示,可变形卷积将根据输入图像或特征图在不同位置为卷积选择值。
与Atrous convolution相比,Atrous convolution在卷积过程中具有较大但固定的膨胀值。(Atrous convolution也称为dilated convolution或hole算法。
与Spatial Transformer Network (STN)比较:STN对输入图像或特征图进行变换,而可变形卷积可以被视为一个非常轻量级的STN。
2. Deformable RoI Pooling
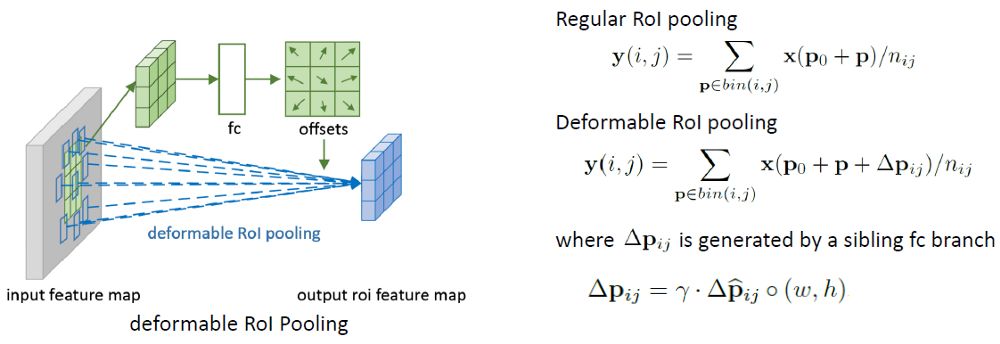
Deformable RoI Pooling
常规RoI Pooling将任意大小的输入矩形区域转换为固定大小的特征。
在Deformable RoI Pooling中,首先,在top path中,我们仍然需要常规的RoI Pooling来生成池化的feature map。
然后,使用一个全连接(fc)层生成归一化的偏移∆p̂ij,然后转化为偏移∆pij(方程在右下角)其中γ= 0.1。
偏移量归一化是必要的,使偏移量的学习不受RoI大小的影响。
最后,在底部路径,我们执行deformable RoI pooling。输出特征图是基于具有增强偏移量的区域进行池化的
3. Deformable Positive-Sensitive (PS) RoI Pooling
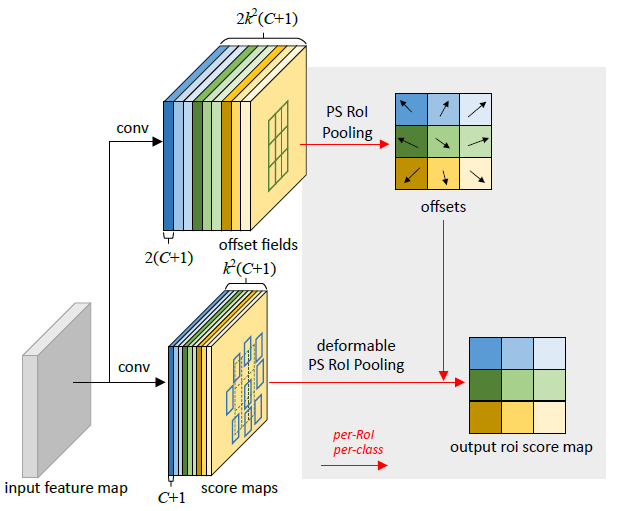
Deformable Positive-Sensitive (PS) RoI Pooling (在这里颜色很重要)
对于原始的R-FCN中的Positive-Sensitive (PS) RoI pooling,所有的输入特征图首先转换为每个类别k²个得分图(假设背景类总共C + 1个类别)(最好是读一下R-FCN,理解一下最初的PS RoI pooling)
在deformable PS RoI pooling中,首先,在顶部路径上,和原始的相似, 卷积用于生成2k²(C + 1)得分图。
这意味着,对于每个类别,有k²个特性图,这些特征图代表了我们要学习的物体的偏移量{上左(TL),上中(TC), . .,右下(BR)}。
偏移量(顶部路径)的原始的PS RoI Pooling是使用图中相同的区域和相同的颜色来池化的。我们在这里得到偏移量。
最后,在底部路径中,我们执行deformable PS RoI pooling来池化偏移量增强的特征图。
论文地址:https://arxiv.org/abs/1904.11490
目前,Bounding Box(即包含物体的一个紧致矩形框)几乎主导了计算机视觉中对于物体的表示,其广泛流行得益于它简便且方便物体特征提取的特点,但另一方面也限制了对物体更精细的定位和特征提取。
北大、清华和微软亚研的研究者们提出了一种新的视觉物体表示方法,称作 RepPoints(representative points,代表性点集),这种方法能更精细地描述物体的几何位置和进行图像特征的提取,同时也兼有简便和方便特征提取的特点。利用这种表示,很自然能得到一个 anchor-free 的物体检测框架,取得了和目前 anchor-based 方法可比的性能。
2.1 动机
在目标检测任务中,边界框描述了目标检测器各阶段的目标位置。
虽然边界框便于计算,但它们仅提供目标的粗略定位,并不完全拟合目标的形状和姿态。因此,从边界框的规则单元格中提取的特征可能会受到背景内容或前景区域的无效信息的严重影响。这可能导致特征质量降低,从而降低了目标检测的分类性能。
本文提出一种新的表示方法,称为 RepPoints,它提供了更细粒度的定位和更方便的分类。
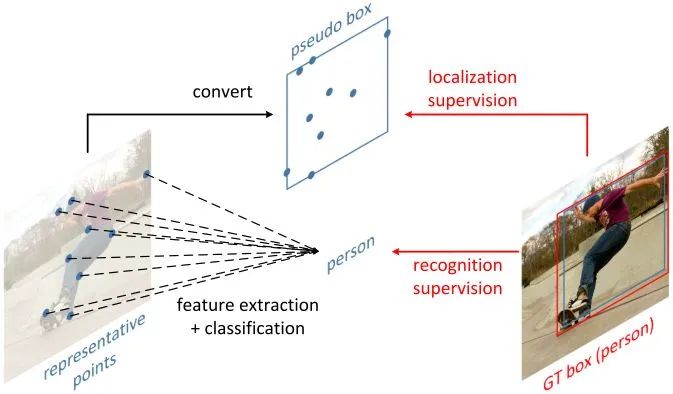
如图所示,RepPoints 是一组点,通过学习自适应地将自己置于目标之上,该方式限定了目标的空间范围,并且表示具有重要语义信息的局部区域。
RepPoints 的训练由目标定位和识别共同驱动的,因此,RepPoints 与 ground-truth 的边界框紧密相关,并引导检测器正确地分类目标。
2.2 Bounding Box Representation
边界框是一个4维表示,编码目标的空间位置,即  ,
,  表示中心点,
表示中心点,  表示宽度和高度。
表示宽度和高度。
由于其使用简单方便,现代目标检测器严重依赖于边界框来表示检测 pipeline 中各个阶段的对象。
性能最优的目标检测器通常遵循一个 multi-stage 的识别范式,其中目标定位是逐步细化的。其中,目标表示的角色如下:
2.3 RepPoints
如前所述,4维边界框是目标位置的一个粗略表示。边界框表示只考虑目标的矩形空间范围,不考虑形状、姿态和语义上重要的局部区域的位置,这些可用于更好的定位和更好的目标特征提取。
为了克服上述限制,RepPoints 转而对一组自适应样本点进行建模:

其中  为表示中使用的样本点的总数。在这项工作中, 默认设置为 9。
为表示中使用的样本点的总数。在这项工作中, 默认设置为 9。
2.4 Learning RepPoints
RepPoints 的学习是由目标定位损失和目标识别损失共同驱动的。为了计算目标定位损失,我们首先用一个转换函数  将 RepPoints 转换为伪框 (pseudo box)。然后,计算转换后的伪框与 ground truth 边界框之间的差异。
将 RepPoints 转换为伪框 (pseudo box)。然后,计算转换后的伪框与 ground truth 边界框之间的差异。
2.5 RPDet
作者设计了一种不使用 anchor 的对象检测器,它利用 RepPoints 代替边界框作为目标的基本表示。
目标表示的演化过程如下:
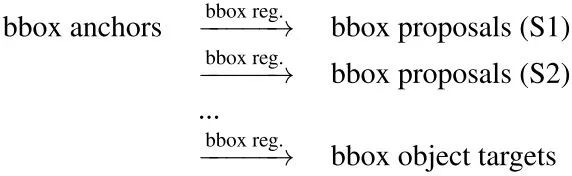
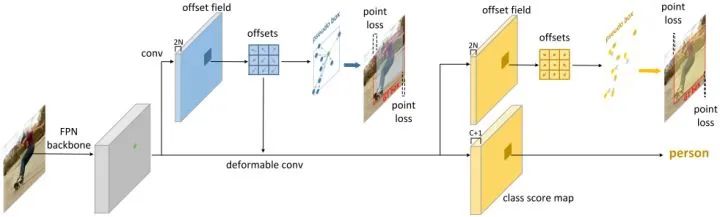
RepPoints Detector (RPDet) 由两个基于可变形卷积的识别阶段构成,如图所示。
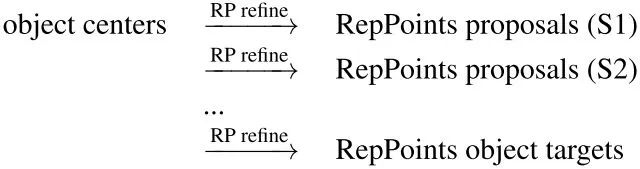
可变形卷积与 RepPoints 很好地结合在一起,因为它的卷积是在一组不规则分布的采样点上计算的,另外,它的分类可以指导训练这些点的定位。
上图的第一个偏移量通过对角点监督学习得到,第二个偏移量在前一个偏移量的基础上通过分类监督学习得到。
可形变卷积通过最后的分类分支和回归分支的监督,自适应的关注到合适的特征位置,提取更好的特征,但是我一直没想明白的是可形变卷积真的能够关注到合适的特征位置吗,可形变卷积的偏移量学习是非常自由的,可能会跑到远离目标的位置,那么这些特征真的是有帮助的吗,这些问题一直困扰着我,我觉得可形变卷积的中间过程太模糊了,太不直接了,是难以解释的。而RepPoints通过定位和分类的监督信号来直接监督偏移量的学习,这样偏移量不就有可解释性了吗,偏移的位置使得定位和分类更加准确(即偏移的位置可定位目标并且语义信息可识别目标),这样偏移量就不会乱跑了,而且是可解释的。
从这个角度来想,RepPoints其实是对可形变卷积进一步的改进,相比可形变卷积有两个优点:
1.通过定位和分类的直接监督来学习可形变卷积的偏移量,使得偏移量具有可解释性。
2.可以通过采样点来直接生成伪框 (pseudo box),不需要另外学习边界框,并且分类和定位有联系。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~