
大数据云原生系列| 微信 Flink on Kubernetes 实战总结
前言
架构转型,拥抱云原生服务生态
当前微信内部的大数据计算平台是基于自研的 Yard 资源调度系统[1]来建设,Yard 的设计初衷除了提供在线服务资源隔离外,另一方面是为了提高在线服务机器的整体资源利用率,其核心策略是在机器空闲时能在上面跑一些大数据离线任务。但是对接业界各种大数据计算框架(例如 Hadoop MapReduce、Spark、Flink 等)都需要专门定制化开发,迭代维护非常不灵活,难以跟上开源社区发展的步伐。为此,我们开始转向使用Kubernetes,并基于腾讯云 TKE 容器平台逐步搭建我们的大数据计算平台。
考虑到我们 Yard 平台上 Flink 作业还不是特别多,历史包袱相对较少,所以我们首先开始 Flink on Kubernetes 实战之路。
微信 Flink 实时计算平台整体概况
微信 Flink 作业数据流转图
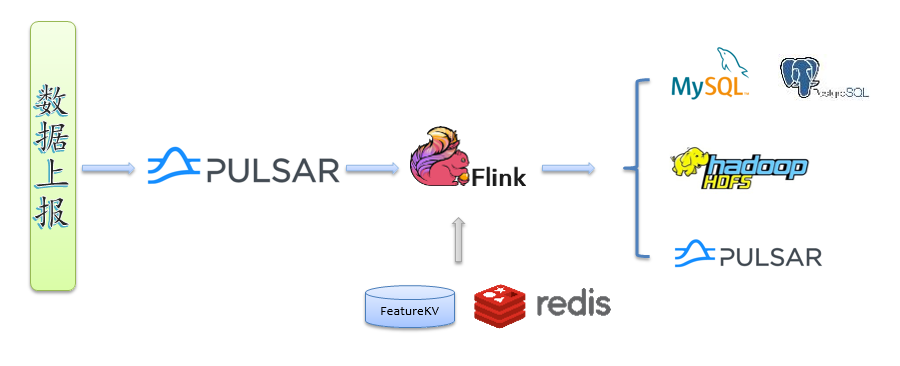
下图是我们大多数业务的 Flink 作业实时计算数据流转图,数据经采集上报到消息队列 Pulsar,用户的 Flink 作业消费 Pulsar 计算(必要时也会访问其他外部存储,如Redis、FeatureKV等),计算结果可以落地到多种存储系统,例如对于报表类业务,计算结果写入 mysql/pg;对于实时样本特征拼接作业,计算结果写入 hdfs,为下游模型训练不断提供样本;对于一些中间结果,则写入Pulsar,以便对接下游 Flink 作业。
下面详细阐述上图中 Flink 作业是如何提交部署的。
集群及 Flink 作业部署
Flink on TKE 半托管服务,极致的Flink云原生使用体验
Flink on TKE 半托管服务提供了Flink集群部署、日志、监控、存储等一站式的服务,用户可以将其他在线业务与Flink运行在同一个集群中,从而最大程度提高资源资源使用率,达到统一资源、统一技术栈、统一运维等能力。
我们基于 TKE 容器平台构建 Flink Kubernetes 计算集群。根据已有的 Flink 作业运行情况,我们发现绝大多数 Flink 作业主要是耗费内存,而CPU利用率普遍较低,在机型选择上我们推荐选择内存型机器。
对于 Flink 作业的提交部署,Flink on K8s 有多种部署模式(详细介绍请参考TKE团队出品的文章:Flink on kubernetes 部署模式分析[2]),Flink 开源社区先后推出了基于 Standalone 的 Kubernetes 声明式部署以及 Kubernetes Native 部署方式,基于 Standalone 的 Kubernetes 声明式部署步骤繁琐且不易管理,所以不考虑,另外社区的 Flink on Kubernetes Native 部署方式是从1.12起正式推出,功能还不够完善,并且尚未被大规模生产验证,我们在这之前其实已经开始调研部署,经过一番比较后,我们使用的是TKE容器团队提供的 Flink on TKE 半托管服务(基于K8s Operator),其提交部署流程大致如下图所示。
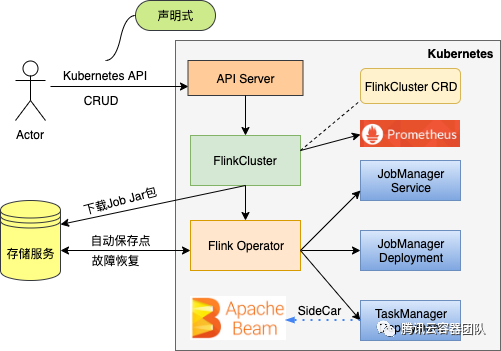
通过 Flink Operator,客户端就可以通过一个简单的声明式 API 提交部署 Flink 作业,各组件的生命周期统一由 Operator 控制,例如:
apiVersion: flinkoperator.Kubernetes.io/v1beta1
kind: FlinkCluster
metadata:
name: flink-hello-world
spec:
image:
name: flink:1.11.3
jobManager:
resources:
limits:
memory: "1024Mi"
cpu: "200m"
taskManager:
replicas: 2
resources:
limits:
memory: "2024Mi"
cpu: "200m"
job:
jarFile: /opt/flink/examples/streaming/helloword.jar
className: org.apache.flink.streaming.examples.wordcount.WordCount
args: ["--input", "/opt/flink/README.txt"]
parallelism: 2
flinkProperties:
taskmanager.numberOfTaskSlots: "2"
Flink Operator 提交流程大致如下图所示,首先会启动一个 Flink Standalone Session Cluster,然后拉起一个 Job Pod 运行用户代码,向 Standalone Session Cluster 提交 Job,提交完成后会不断去跟踪 Job 的运行状态。所以运行过程中会有三类 Pod,即 JobManager、TaskManager、Job Pod。
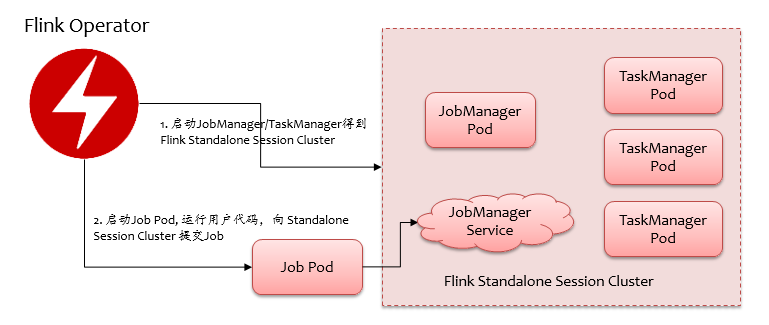
使用 Flink Operator 部署 Flink 作业的好处不言而喻,客户端不需要像 Flink on Kubernetes Native 部署方式那样需要 kubeconfig,可以直接通过 http 接口访问 API Server。虽然 Flink on Kubernetes Native 部署可以做到按需自动申请 TM,但是实际上我们的应用场景基本都是单 Job 的流计算,用户事先规划好资源也可接受,而且基于 Flink Operator,我们可以做批调度,即 Gang Schedule,可以避免资源有限的情况下作业之间互相等待资源 hold 住的情况(例如大作业先提交,部分 TaskManager 长时间处于资源等待状态,小作业后提交,小作业申请不到资源也 hold 在那里傻等)。
自动下载用户上传资源
作业与 Flink 内核动态分离,提高灵活性
通过上述的声明式 API 方式提交部署,我们可以看到用户 jar 包需要事先打到 image 里,作为平台提供方,当然不可能让每个用户自己去打 docker image,有些用户甚至都不知道怎么用 docker,所以我们应该对用户屏蔽 docker image,用户只需要上传 jar 包等资源即可。Flink Operator 提供了 initContainer 选项,借助它我们可以实现自动下载用户上传资源,但是为了简单,我们直接修改 docker entrypoint 启动脚本,先下载用户上传的资源,再启动 Flink 相关进程,用户上传的资源通过环境变量声明。例如:
apiVersion: flinkoperator.Kubernetes.io/v1beta1
kind: FlinkCluster
metadata:
name: flink-hello-world
spec:
image:
name: flink:1.11.3
envVars:
- name: FLINK_USER_JAR
value: hdfs://xxx/path/to/helloword.jar
- name: FLINK_USER_DEPENDENCIES
value: hdfs://xxx/path/to/config.json,hdfs://xxx/path/to/vocab.txt
...
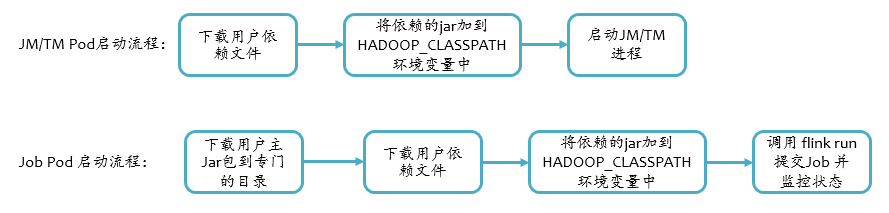
用户上传的依赖可以是任意文件,跟 Flink on Yarn 的方式不同,我们不用通过 submit 来分发依赖,而是在容器 docker entrypoint 启动脚本中直接下载到工作目录,以便用户可以在代码里以相对路径的方式(例如 ./config.json)访问到,如果依赖文件是 jar,则需要将其附加到 classpath 中,为了不修改 flink 的脚本,我们将 jar 附加到环境变量 HADOOP_CLASSPATH上,最后 Flink 相关进程启动的时候会被加到 Java 的 classpath 中。
对于用户主类所在的 jar(即环境变量FLINK_USER_JAR),只需要在 Job Pod 的 Container 中下载,如果同样下载到当前目录,那么它也会被附加到classpath中,在提交的时候可能会出现如下类加载链接错误,这是因为 Java 启动的时候加载了一遍,在执行用户main函数的时候 Flink 又会去加载一遍,所以我们将主 jar 包下载到一个专门固定目录,例如/opt/workspace/main/,那么提交时通过spec.job.jarFile
参数指定到 /opt/workspace/main/xxx.jar 即可。
java.lang.LinkageError: loader constraint violation: loader (instance of sun/misc/Launcher$AppClassLoader) previously initiated loading for a different type with name "org/apache/pulsar/client/api/Authentication"
at java.lang.ClassLoader.defineClass1(Native Method) ~[?:1.8.0_152]
at java.lang.ClassLoader.defineClass(ClassLoader.java:763) ~[?:1.8.0_152]
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142) ~[?:1.8.0_152]
at java.net.URLClassLoader.defineClass(URLClassLoader.java:467) ~[?:1.8.0_152]
at java.net.URLClassLoader.access$100(URLClassLoader.java:73) ~[?:1.8.0_152]
at java.net.URLClassLoader$1.run(URLClassLoader.java:368) ~[?:1.8.0_152]
at java.net.URLClassLoader$1.run(URLClassLoader.java:362) ~[?:1.8.0_152]
与微信后台服务打通
云原生架构下的资源类型 Demonsets,简化架构转型复杂度
用户的 Flink 作业经常需要在运行过程中与微信的后台服务进行交互,在传统的裸机上访问微信的后台服务需要机器部署 Agent 及路由配置,对于 Kubernetes 集群,在我们基础架构中心的同事支持下,微信后台基础 Agent 以 DeamonSet 方式打包到部署到每个节点上,我们在起 Flink 相关 Container 的时候,带上 HostIPC 选项并挂载路由配置路径,就可以像使用裸机一样访问微信的后台服务。
此外,因为部分 Agent 的 unix sock 文件在母机 /tmp 下,我们需要在容器里挂载目录 /tmp,然而 Flink 运行过程中 shuffle、web 以及一些临时文件(例如解压出来的so等)默认都是放到 /tmp 目录下,这就会导致作业即使失败也会残留一些垃圾到母机上,长此以往,/tmp 目录势必会被撑爆,所以我们在启动 Java 进程时设置参数 -Djava.io[3].tmpdir=/opt/workspace/tmp,将 Java 的默认临时目录改到容器内的路径,这样作业失败,容器销毁不至于残留垃圾。
属性配置、日志及监控
日志与监控,提升可观测性
从上面的声明式 yaml 配置可以看到,提交 Flink 作业时是通过flinkProperties 选项来指定 Flink 属性参数,事实上 Flink Operator 会将flinkProperties指定的属性参数以 ConfigMap 形式部署,会覆盖 image 中的 flink/conf 目录,所以我们不能将系统默认属性配置放到 flink image 中,为此,我们在客户端维护一份 Flink 系统默认配置,在提交的时候会合并用户填的属性配置,填充到 flinkProperties 选项中,可以方便我们灵活调整 Flink 系统默认配置。
默认情况下,Flink on Kubernetes 部署的作业,其在 Docker Container 中运行的进程都是前台运行的,使用 log4j-console.properties配置,日志会直接打到控制台,这样就会导致 Flink UI 无法展示 log,只能去查看 Pod 日志,此外用户通过 System.out.println 打的日志也会混在 log4j 的日志中,不易区分查看。所以我们重新定义了 log4j-console.properties,将 log4j 日志打到FLINK_LOG_DIR 目录下的文件中,并按大小滚动,为了能在 Flink UI 上也能看到用户 stdout 的输出,在进程启动命令flink-console.sh 最后加上 2>&1 | tee ${FLINK_LOG_PREFIX}.out,可以把控制台输出的日志旁路一份到日志目录的文件中。最后 Flink UI 展示的日志如下图所示:
对于历史失败作业,我们在Kubernetes上也部署了一个 Flink History Server,可以灵活地扩缩容,从此再也不用担心半夜作业挂了自动重启无法追溯原因了。
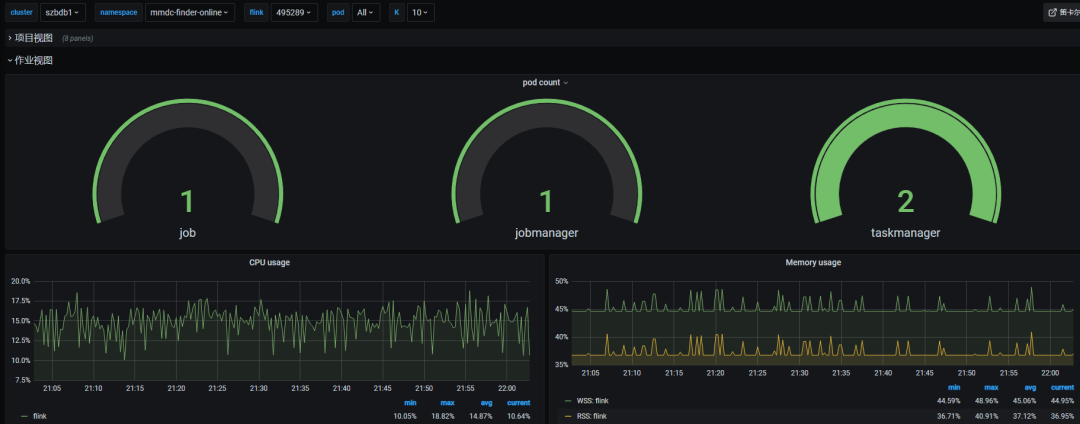
对于资源及作业的监控,TKE 提供了免费的云原生 Prometheus 服务 TPS,可以一键部署并关联我们的 TKE 集群,然而我们在早期已经采用主流的 Prometheus + Grafana 组合部署了监控平台,这里就没有使用TPS。当前我们有集群资源、应用组(Namespace)资源、作业资源利用情况的监控,大致如下图所示。后面我们会再将每个作业 Flink Metric 推到 Prometheus,便于监控作业级别的反压、gc、operator 流量等信息。
数据应用平台对接
基于上述基础的 Flink-on-Kubernetes 能力,就可以将 Flink 对接到我们的各种数据应用平台上。如下图所示,我们已经支持用户使用多样化的方式使用 Flink,用户可以在机器学习平台拖拽节点或者注册定制化节点以 Jar 包或 PyFlink 的方式使用,另外也可以在SQL分析平台上写 Flink SQL。
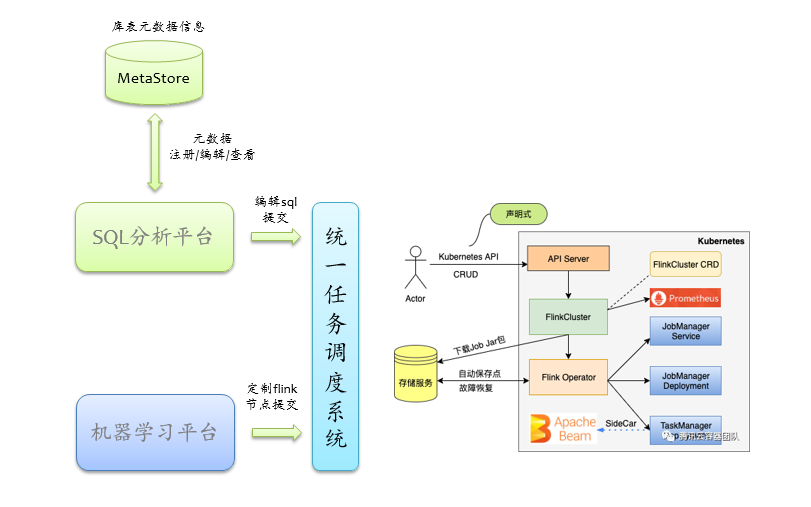
对于 Jar、PyFlink 的方式使用就不详细展开,对于 Flink SQL 的支持,我们目前是结合我们自身的元数据体系,利用 Flink 已有的 SQL 功能。当前实时数仓被业界广泛提起,我们知道传统的离线数仓,如 Hive,无外乎是在 HDFS 上套了一层 Schema,那么实时数仓也类似,数据源通常是 Kafka、Pulsar 这类消息队列系统,在这之上套一层 Schema 将实时数据管理起来,就可以称之为实时数仓了。我们基于SQL分析平台的元数据管理体系,构建 Flink SQL 能力,用户可以在SQL分析平台上注册/管理库表元数据,为了架构简单,我们并没有去实现自己的 Flink Catalog(元数据操作直接在 SQL分析平台上完成,无需实现 create、drop 等 API),而是采用如下图所示的流程来提交 SQL。
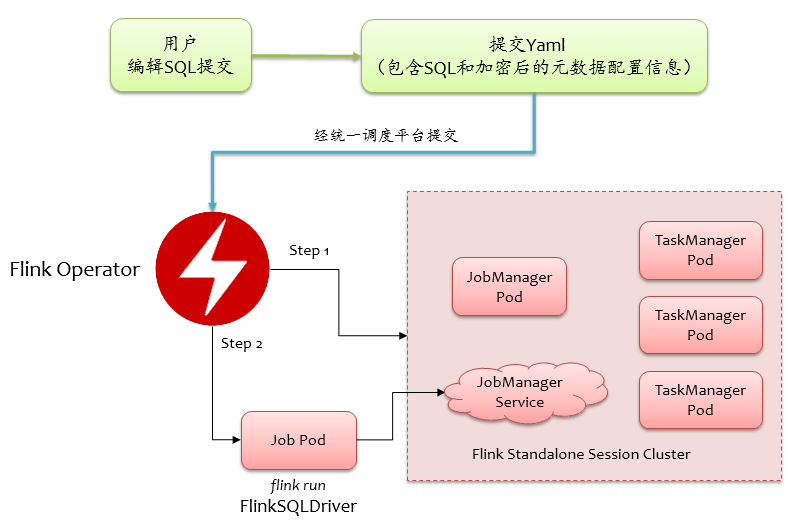
用户在SQL分析平台上注册库表元数据(可以精细授权管控),然后编辑 SQL 提交,首先SQL分析平台会做语法校验、权限及合法性校验,没问题后,将 SQL 涉及到的元数据加密打包,连同声明式配置 Yaml 提交给统一调度平台,在统一调度平台上我们开发了一个 FlinkSQL 类型的作业,本质上就是一个常规的 Flink Jar 作业,即 FlinkSQLDriver ,用于接受 SQL 及其附属的参数,FlinkSQLDriver 被提交后,解析传过来的配置,组装完整的 SQL 语句(包括 DDL、DML),然后调用 tableEnvironment.executeSql逐条执行,所以本质上是将库表临时注册到 default catalog 中。
小结
本文从整体上介绍了微信 Flink-on-Kubernetes实战经验以及 Flink 数据应用平台的概况,一方面我们提供最基础的 Flink 计算平台能力,借助 Kubernetes 有效管控集群,另一方面我们在已有的数据通道及元数据平台上构建实时数仓,提供 Flink SQL 能力,进一步降低用户使用门槛,对于 Flink SQL 的支持目前还比较初级和原始,后面我们将结合业务使用情况探索更多深层次的优化。
参考资料
Yard 资源调度系统: 【https://www.infoq.cn/article/uC3BKkza0cmBKDElHyca】
[2]Flink on kubernetes 部署模式分析:【 https://mp.weixin.qq.com/s/61AQTG-LjkSThcHN4gSrNQ】
[3]Djava.io: 【http://djava.io/】
答题赢好礼

在本篇文后留言处
回答2位作者的提问:
① Flink on Kubernetes 通常有哪几种部署模式?对于当前的Flink版本,你在生产实践中使用哪种部署模式?
② Flink UI你们是如何暴露给外部访问?
3月26日由作者选出最先回答的最佳答案
前三名送出鹅厂萌新蓝鹅一只

注:截止时间:2021年3月26日11点。
获奖情况将于3月26日在本篇文章留言处公布,请关注。




往期精选推荐
 插播福利!!!
插播福利!!!