
JavaScript 的静态作用域链与“动态”闭包链
在 JavaScript 里面,函数、块、模块都可以形成作用域(一个存放变量的独立空间),他们之间可以相互嵌套,作用域之间会形成引用关系,这条链叫做作用域链。
作用域链具体是什么样呢?
静态作用域链
比如这样一段代码
function func() {
const guang = 'guang';
function func2() {
const ssh = 'ssh';
{
function func3 () {
const suzhe = 'suzhe';
}
}
}
}
其中,有 guang、ssh、suzhe 3个变量,有 func、func2、func3 3个函数,还有一个块,他们之间的作用域链可以用babel查看一下。
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const code = `
function func() {
const guang = 'guang';
function func2() {
const ssh = 'ssh';
{
function func3 () {
const suzhe = 'suzhe';
}
}
}
}`;
const ast = parser.parse(code);
traverse(ast, {
FunctionDeclaration (path) {
if (path.get('id.name').node === 'func3') {
console.log(path.scope.dump());
}
}})
结果是
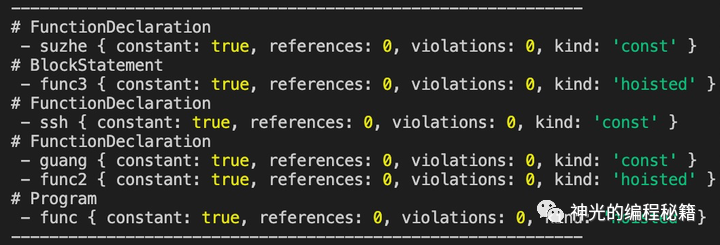
用图可视化一下就是这样的

函数和块的作用域内的变量声明会在作用域 (scope) 内创建一个绑定(变量名绑定到具体的值,也就是 binding),然后其余地方可以引用 (refer) 这个 binding,这样就是静态作用域链的变量访问顺序。
为什么叫“静态”呢?
因为这样的嵌套关系是分析代码就可以得出的,不需要运行,按照这种顺序访问变量的链就是静态作用域链,这种链的好处是可以直观的知道变量之间的引用关系。
相对的,还有动态作用域链,也就是作用域的引用关系与嵌套关系无关,与执行顺序有关,会在执行的时候动态创建不同函数、块的作用域的引用关系。缺点就是不直观,没法静态分析。
静态作用域链是可以做静态分析的,比如我们刚刚用 babel 分析的 scope 链就是。所以绝大多数编程语言都是作用域链设计都是选择静态的顺序。
但是,JavaScript 除了静态作用域链外,还有一个特点就是函数可以作为返回值。比如
function func () {
const a = 1;
return function () {
console.log(a);}
}
const f2 = func();
这就导致了一个问题,本来按照顺序创建调用一层层函数,按顺序创建和销毁作用域挺好的,但是如果内层函数返回了或者通过别的暴露出去了,那么外层函数销毁,内层函数却没有销毁,这时候怎么处理作用域,父作用域销不销毁?(比如这里的 func 调用结束要不要销毁作用域)
不按顺序的函数调用与闭包
比如把上面的代码做下改造,返回内部函数,然后在外面调用:
function func() {
const guang = 'guang';
function func2() {
const ssh = 'ssh';
function func3 () {
const suzhe = 'suzhe';
}
return func3;
}return func2;
}
const func2 = func();
当调用 func2 的时候 func1 已经执行完了,这时候要不要销毁 ?为了解决这个问题,JavaScript 设计了闭包的机制。
闭包怎么设计?
先不看答案,考虑一下我们解决这个静态作用域链中的父作用域先于子作用域销毁怎么解决。
首先,父作用域要不要销毁?是不是父作用域不销毁就行了?
不行的,父作用域中有很多东西与子函数无关,为啥因为子函数没结束就一直常驻内存。这样肯定有性能问题,所以还是要销毁。但是销毁了父作用域不能影响子函数,所以要再创建个对象,要把子函数内引用(refer)的父作用域的变量打包里来,给子函数打包带走。
怎么让子函数打包带走?
设计个独特的属性,比如 [[Scopes]] ,用这个来放函数打包带走的用到的环境。并且这个属性得是一个栈,因为函数有子函数、子函数可能还有子函数,每次打包都要放在这里一个包,所以就要设计成一个栈结构,就像饭盒有多层一样。
我们所考虑的这个解决方案:销毁父作用域后,把用到的变量包起来,打包给子函数,放到一个属性上。这就是闭包的机制。
我们来试验一下闭包的特性:
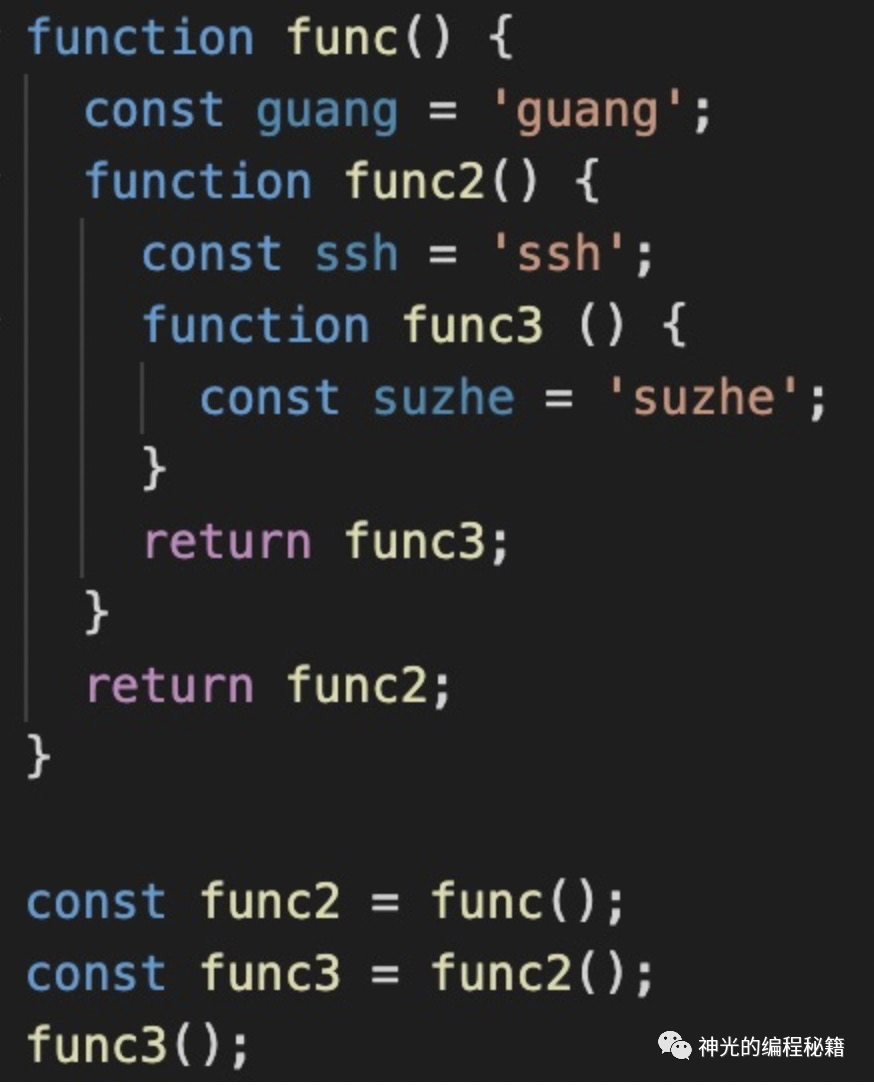
这个 func3 需不需要打包一些东西?会不会有闭包?
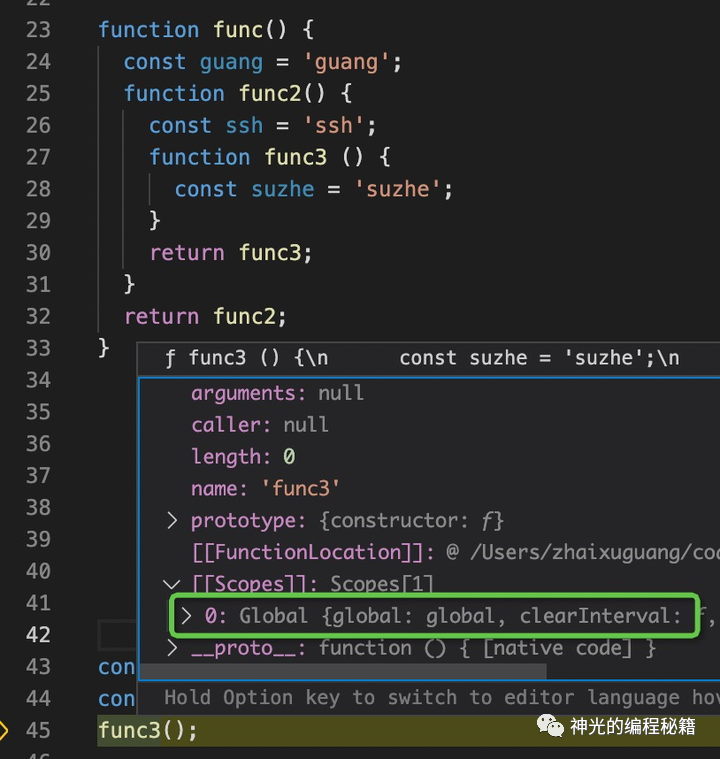
其实还是有闭包的,闭包最少会包含全局作用域。
但是为啥 guang、ssh、suzhe 都没有 ?suzhe 是因为不是外部的,只有外部变量的时候才会生成,比如我们改动下代码,打印下这 3 个变量。
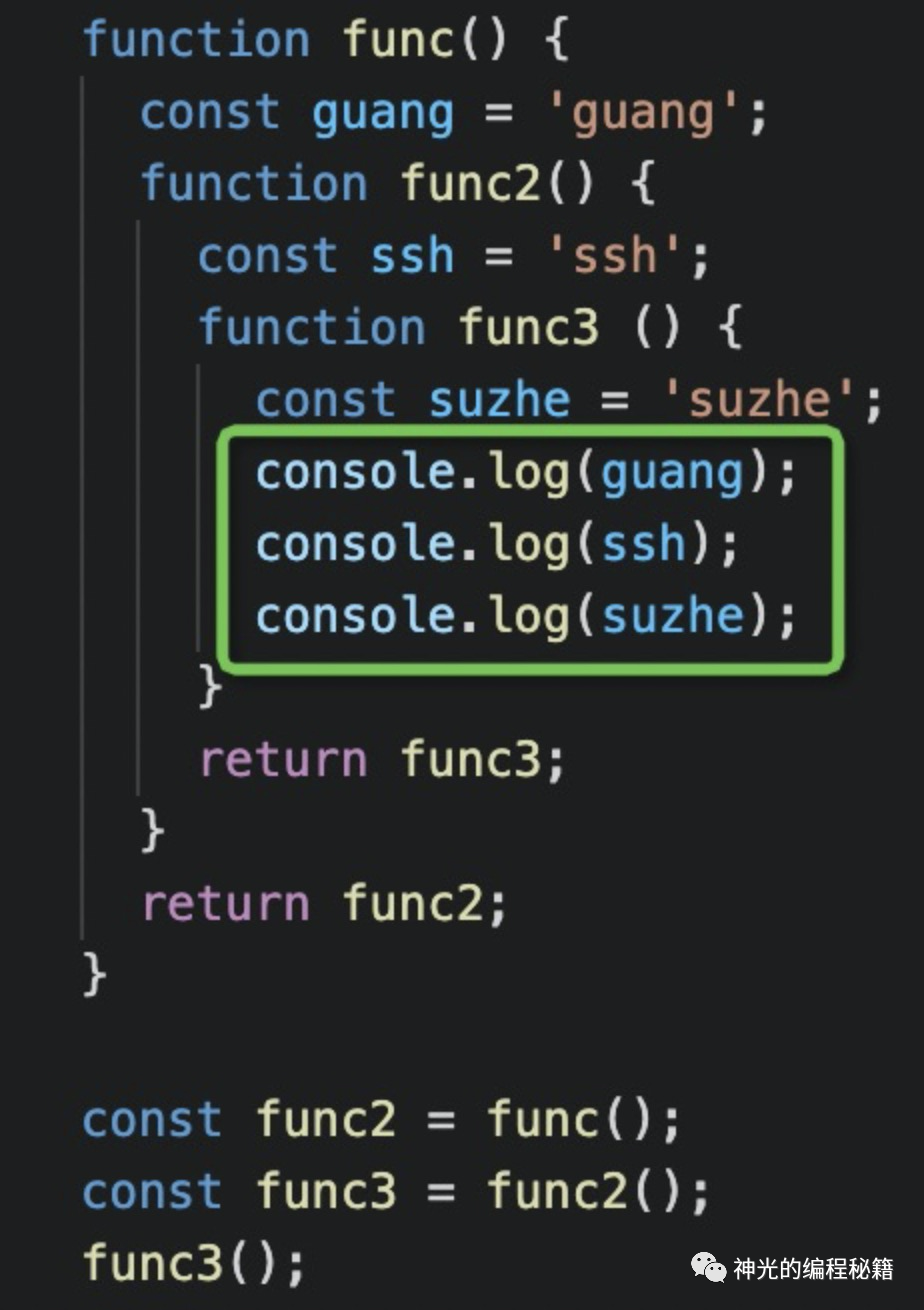
再次查看 [[Scopes]] (打包带走的闭包环境):
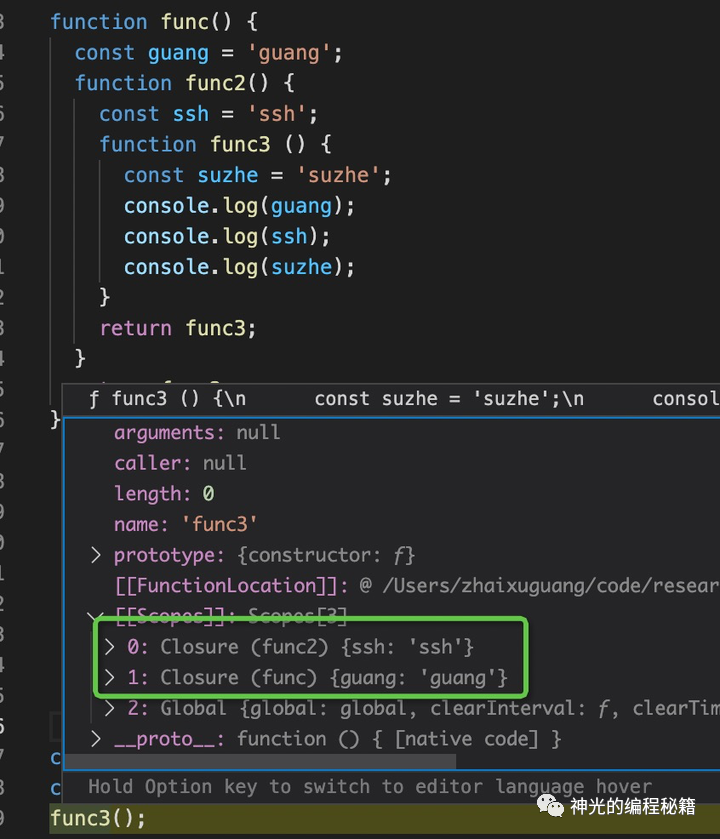
这时候就有俩闭包了,为什么呢?suzhe 哪去了?
首先,我们需要打包的只是环境内没有的,也就是闭包只保存外部引用。然后是在创建函数的时候保存到函数属性上的,创建的函数返回的时候会打包给函数,但是 JS 引擎怎么知道它要用到哪些外部引用呢,需要做 AST 扫描,很多 JS 引擎会做 Lazy Parsing,这时候去 parse 函数,正好也能知道它用到了哪些外部引用,然后把这些外部用打包成 Closure 闭包,加到 [[scopes]] 中。
所以,闭包是返回函数的时候扫描函数内的标识符引用,把用到的本作用域的变量打成 Closure 包,放到 [[Scopes]] 里。
所以上面的函数会在 func3 返回的时候扫描函数内的标识符,把 guang、ssh 扫描出来了,就顺着作用域链条查找这俩变量,过滤出来打包成两个 Closure(因为属于两个作用域,所以生成两个 Closure),再加上最外层 Global,设置给函数 func3 的 [[scopes]] 属性,让它打包带走。
调用 func3 的时候,JS 引擎 会取出 [[Scopes]] 中的打包的 Closure + Global 链,设置成新的作用域链, 这就是函数用到的所有外部环境了,有了外部环境,自然就可以运行了。
这里思考一个问题:调试代码的时候为什么某个变量明明在作用域内能访问到,但就是没有相关信息呢?
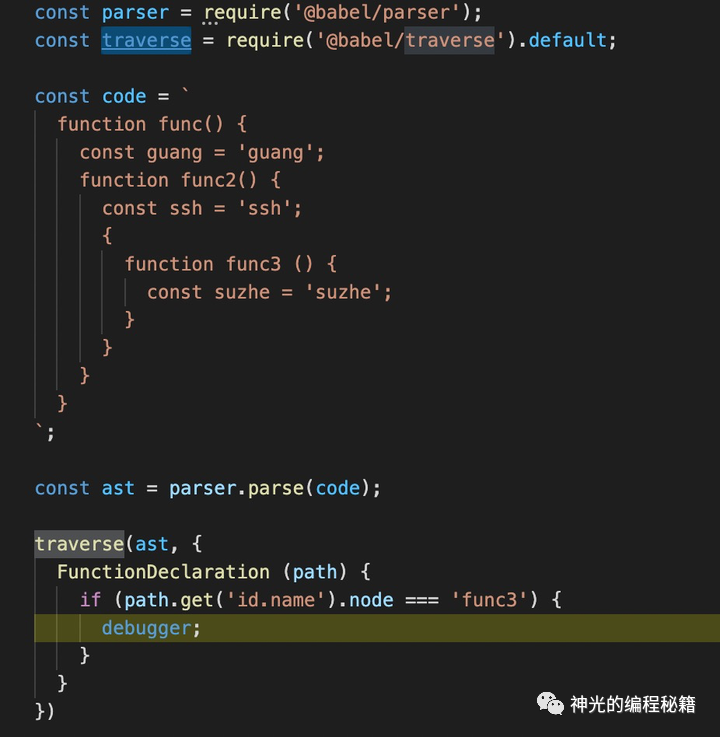
这个 traverse,明明能访问到的,为啥就是不显示信息呢?是 debugger 做的太烂了么?
不是的,如果你不知道原因,那是因为你还不理解闭包。因为这个 FunctionDeclaration 的函数是一个回调函数,明显是在另一个函数内调用的,就需要在创建的时候打包带走这个环境内的东西,根据只打包必要的环境的原则(不浪费内存),traverse 没有被引用(refer),自然就不打包了。并不是 debugger 有 bug 了。
所以我们只要访问一下,就能在调试的时候访问到了。
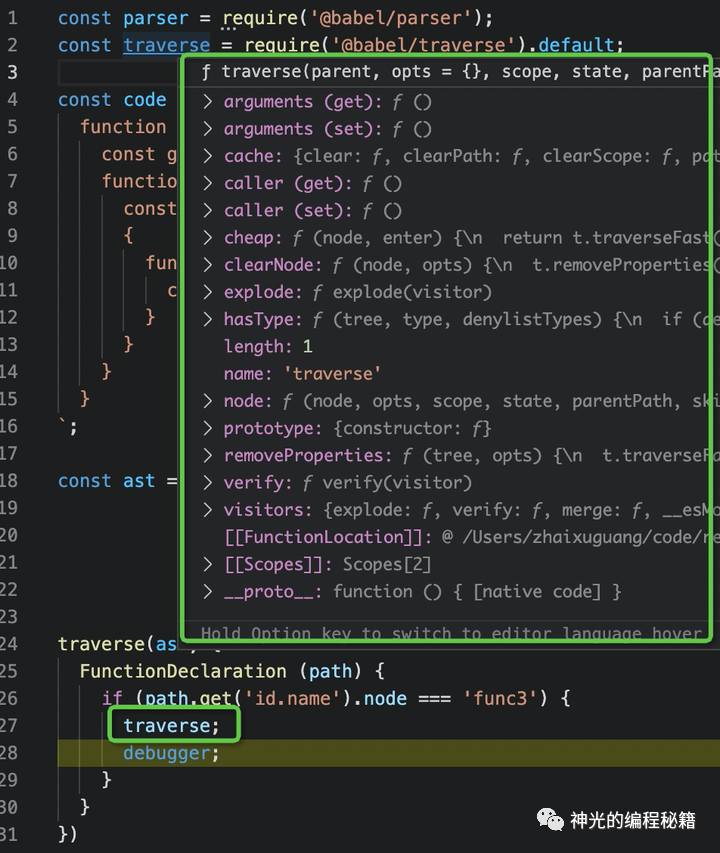
是不是突然知道为啥调试的时候不能看一些变量的信息了,能解释清楚这个现象,就算理解闭包了。
再来思考一个问题:闭包需要扫描函数内的标识符,做静态分析,那 eval 怎么办,他有可能内容是从网络记载的,从磁盘读取的等等,内容是动态的。用静态去分析动态是不可能没 bug 的。怎么办?
没错,eval 确实没法分析外部引用,也就没法打包闭包,这种就特殊处理一下,打包整个作用域就好了。
验证一下:
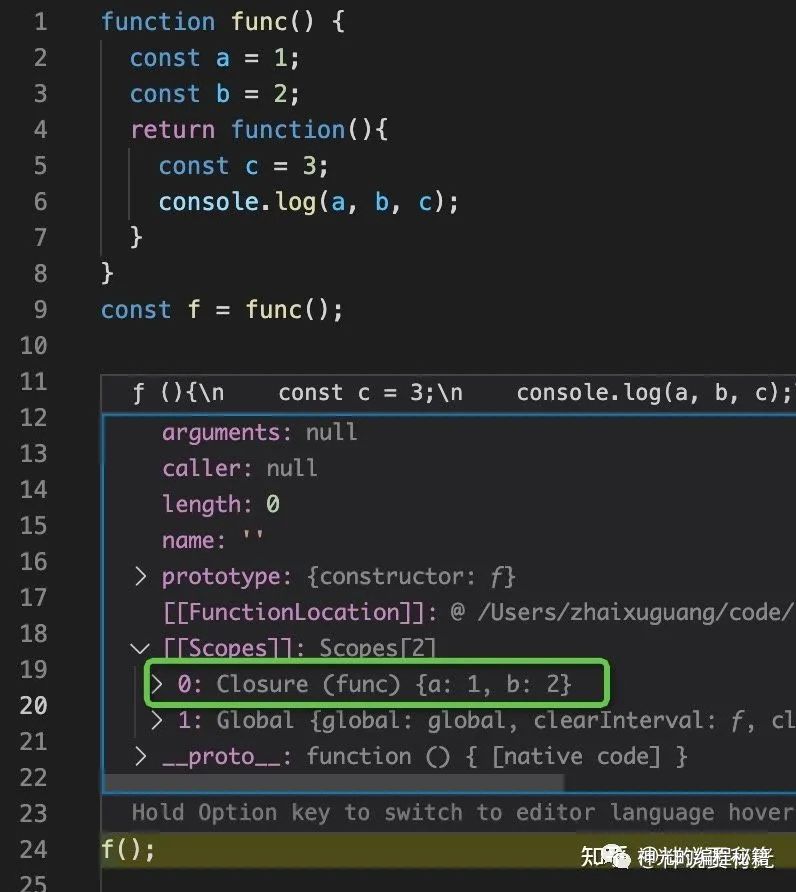
这个就像上面所说的,会把外部引用的打包成闭包
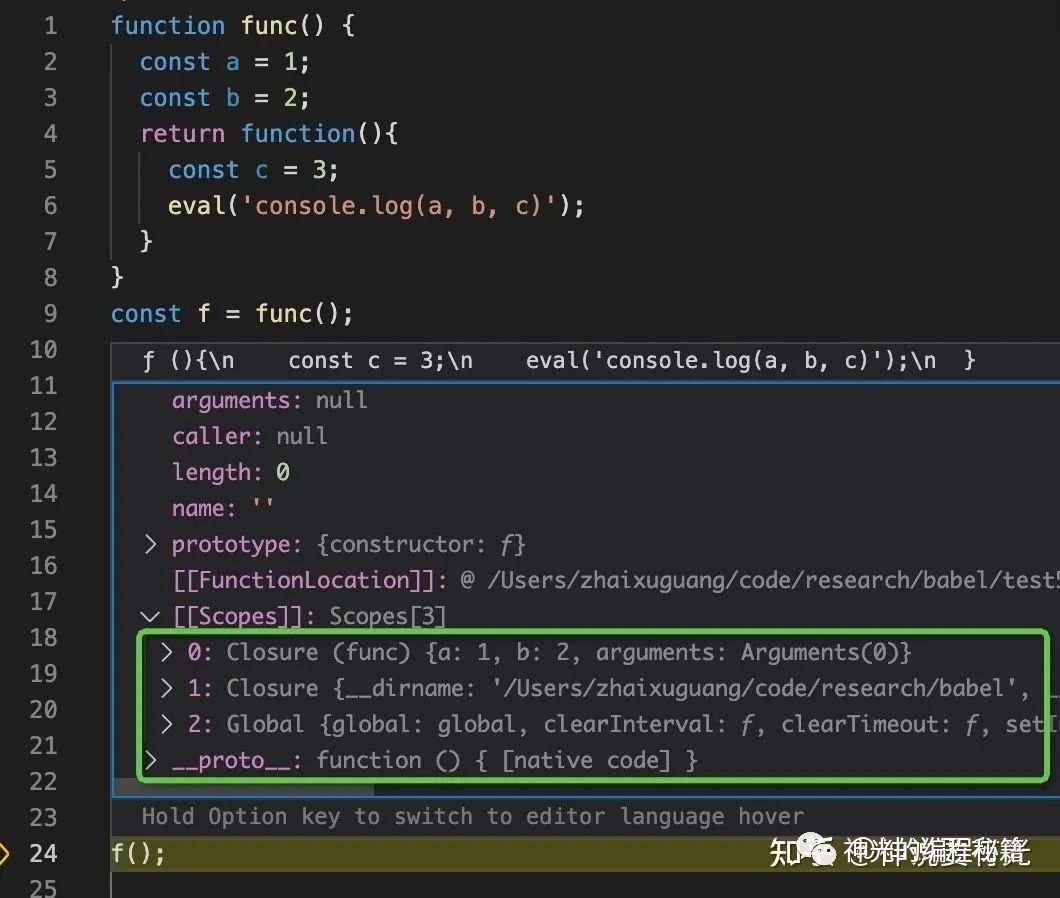
这个就是 eval 的实现,因为没法静态分析动态内容所以全部打包成闭包了,本来闭包就是为了不保存全部的作用域链的内容,结果 eval 导致全部保存了,所以尽量不要用 eval,会导致闭包保存内容过多。
但是 JS 引擎只处理了直接调用,也就是说直接调用 eval 才会打包整个作用域,如果不直接调用 eval,就没法分析引用,也就没法形成闭包了。
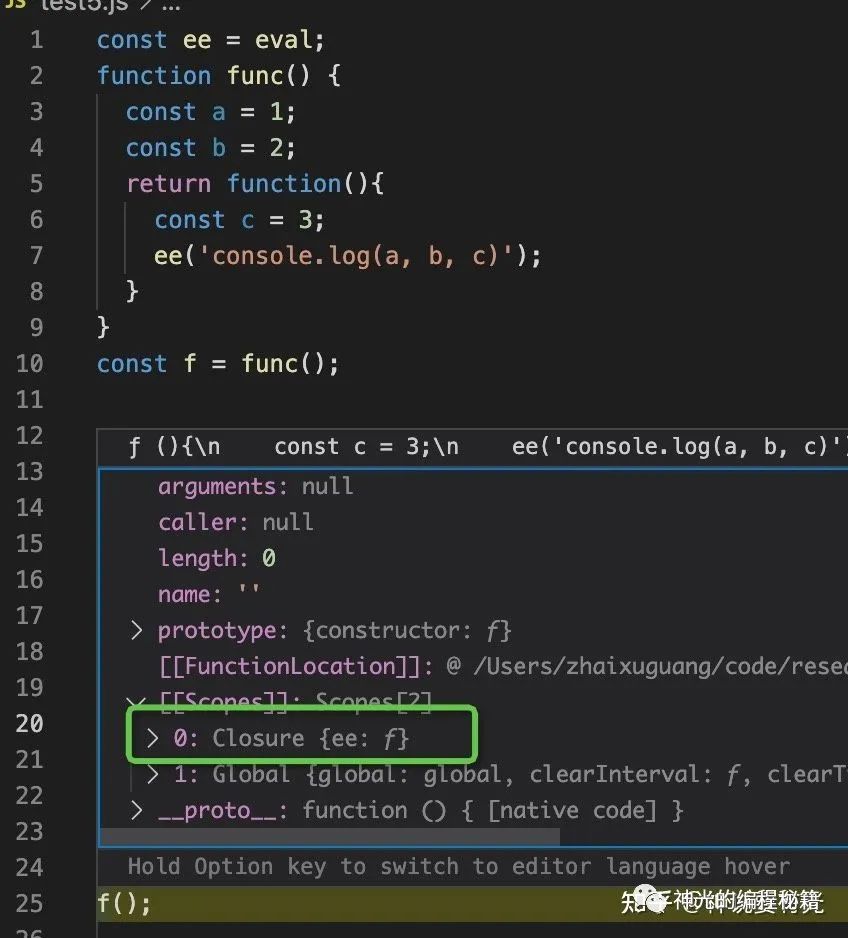
这种特殊情况有的时候还能用来完成一些黑魔法,比如利用不直接调用 eval 不会生成闭包,会在全局上下文执行的特性。
给闭包下个定义
用我们刚刚的试验来给闭包下个定义:
闭包是在函数创建的时候,让函数打包带走的根据函数内的外部引用来过滤作用域链剩下的链。它是在函数创建的时候生成的作用域链的子集,是打包的外部环境。evel 因为没法分析内容,所以直接调用会把整个作用域打包(所以尽量不要用 eval,容易在闭包保存过多的无用变量),而不直接调用则没有闭包。
过滤规则:
1. 全局作用域不会被过滤掉,一定包含。所以在何处调用函数都能访问到。
2. 其余作用域会根据是否内部有变量被当前函数所引用而过滤掉一些。不是每个返回的子函数都会生成闭包。
3. 被引用的作用域也会过滤掉没有被引用的 binding (变量声明)。只把用到的变量打个包。
闭包的缺点
JavaScript 是静态作用域的设计,闭包是为了解决子函数晚于父函数销毁的问题,我们会在父函数销毁时,把子函数引用到的变量达成 Closure 包放到函数的 [[Scopes]] 上,让它计算父函数销毁了也随时随地能访问外部环境。
这样设计确实解决了问题,但是有没有什么缺点呢?
其实问题就在于这个 [[Scopes]] 属性上
我们知道 JavaScript 引擎会把内存分为函数调用栈、全局作用域和堆,其中堆用于放一些动态的对象,调用栈每一个栈帧放一个函数的执行上下文,里面有一个 local 变量环境用于放内部声明的一些变量,如果是对象,会在堆上分配空间,然后把引用保存在栈帧的 local 环境中。全局作用域也是一样,只不过一般用于放静态的一些东西,有时候也叫静态域。
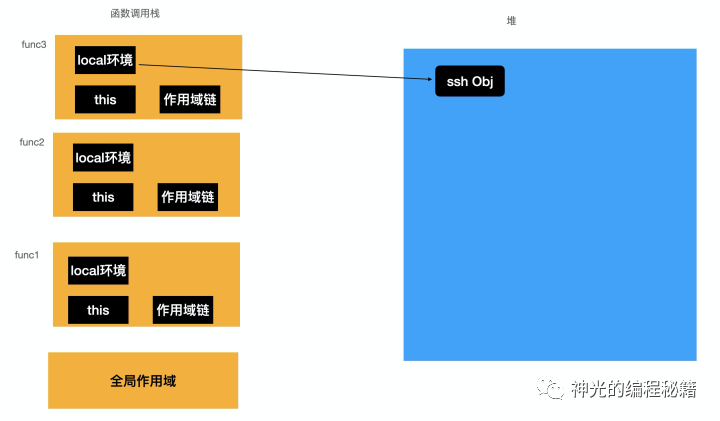
每个栈帧的执行上下文包含函数执行需要访问的所有环境,包括 local 环境、作用域链、this等。
那么如果子函数返回了会发生什么呢?
首先父函数的栈帧会销毁,子函数这个时候其实还没有被调用,所以还是一个堆中的对象,没有对应的栈帧,这时候父函数把作用域链过滤出需要用到的,形成闭包链,设置到子函数的 [[Scopes]] 属性上。
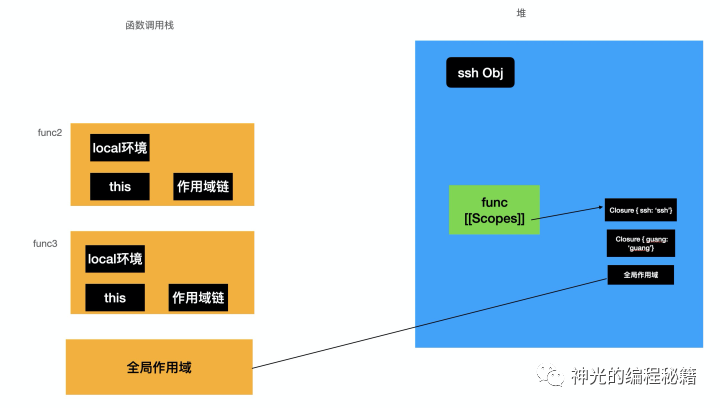
父函数销毁,栈帧对应的内存马上释放,用到的 ssh Obj 会被 gc 回收,而返回的函数会把作用域链过滤出用到的引用形成闭包链放在堆中。这就导致了一个隐患:本来作用域是随着函数调用的结束而销毁的,因为整个栈帧都会被马上销毁。而形成闭包以后,转移到了堆内存。当运行这个子函数的时候,子函数会创建栈帧,如果这个函数一直在运行,那么它在堆内存中的闭包就一直占用着内存,就会使可用内存减少,严重到一定程度就算是内存泄漏了。所以闭包不要乱用,少打包一点东西到堆内存。
总结
我们从静态作用域开始聊起,明确了什么是作用域,通过 babel 静态分析了一下作用域,了解了下静态和动态作用域,然后引入了子函数先于父函数销毁的问题,思考了下方案,然后引入了闭包的概念,分析下闭包生成的流程,保存的位置。我们还用闭包的特性分析了下为什么有时候调试的时候查看不了变量信息,之后分析了下 eval 为什么没法精确生成闭包,什么时候全部打包作用域、什么时候不生成闭包, eval 为什么会导致内存占用过多。之后分析了下带有闭包的函数在内存中的特点,解释了下为啥可能会内存泄漏。
闭包是在返回一个函数的时候,为了把环境保存下载,创建的一个快照,对作用域链做了tree shking,只留下必要的闭包链,保存在堆里,作为对象的 [[scopes]] 属性,让函数不管走到哪,随时随地可访问用到的外部环境。
因为还没执行函数,所以要静态分析标识符引用。静态分析动态这件事情被无数个框架证明做不了,所以返回的函数有eval 只能全部打包或者不生成闭包。类似webpack 的动态import没法分析一样。
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
点个「在看」,让更多的人也能看到这篇内容(喜欢不点在看,都是耍流氓 -_-) 欢迎加我微信「TH0000666」一起交流学习... 关注公众号「前端Sharing」,持续为你推送精选好文。