
揭开“视频超分”黑科技的神秘面纱
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
01

数字相机在将真实世界转换为图片时,对真实的光信号进行了离散化,每个像素是一个采样,像素与像素之间是有间隔的。当图像分辨率较低时,采样率就比较低,或者可以理解为像素与像素之间的间隔是较大的;分辨率提高,像素与像素之间的间隔就变小,最终在显示图像时,就会对场景有更加精细的呈现。因此我们希望图像的分辨率越高越好,可以得到更加清晰的图像。但是,由于采集设备的能力,或者编码压缩、传输等方面的限制,图像的分辨率有时会比较低,为了提高这些图像的质量,可以通过提升分辨率来得到更高质量的图像。最直接朴素的想法就是用相邻的像素来填补空白,即近邻取样插值。但是这样的算法会出现有阶梯状锯齿,明显不能很好地提高图像的质量。双线性插值、双三次插值、Lanczos插值等算法可以提高比近邻取样插值更好的效果。这一类传统的算法,往往被归为图像缩放技术。一般缩放的比例不会太高。
随着深度学习技术的发展,将低分辨率图像进行处理,得到一张高分辨率图像,同时恢复出自然、清晰的纹理,就是我们常听到的超分辨率技术,往往针对较高倍数的缩放,如4倍8倍缩放等。经典的图像超分算法SRCNN,首次将卷积神经网络应用于图像超分辨率技术,相较于传统的算法,SRCNN在图像的重建质量上取得了极大的提升。与传统方法类似,它实际上也是利用低分辨率图像对空缺信息进行填补,从而提高分辨率和质量。在学习阶段,有同一幅图的高分辨率和低分辨率两个版本,输入低分辨率图,通过CNN网络后,输出高分辨率图像,同时与原有的高分辨率图进行对比,更新迭代下一次的学习,最后得到的CNN网络,就可以用来恢复低分辨率图像。如图3所示,首先将低分辨率图输入到网络,经过特征提取、非线性映射、重建等步骤,输入高分辨率图像。SRCNN之所以比传统网络更加优秀,是因为它即通过对低分辨率图像的特征进行学习和提取,针对不同的纹理特征,然后根据特征的不同,从而可以更加合理地进行高频信息的生成。
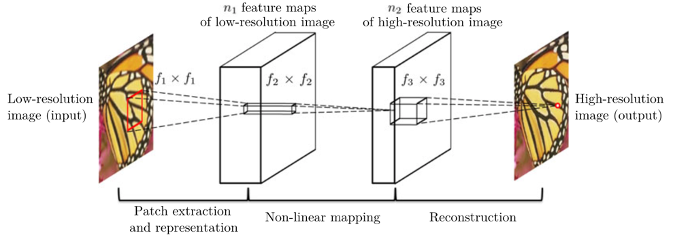
图3 SRCNN模型中的卷积结构
视频与图像类似,分辨率的提升对于提升视频质量也至关重要。与图像超分最大的不同,就是视频可以利用多个连续的图像/帧之间的相关信息,提升目标图像/帧的分辨率。虽然可以将视频拆分成多幅图像,然后用图像超分算法进行处理,但是会造成帧与帧之间出现不连贯的失真。近年来出现了一大批优秀的应用于视频的超分算法,以图像超分算法为基础,通过增加相应的模块来挖掘帧与帧之间的特征,从而提高视频超分算法的性能。
视频超分,假设低分辨率视频是从高分辨率的视频经过一系列的退化操作而得到,超分算法就是将该退化操作进行求逆,从而可以将低分辨率视频恢复成高分辨率视频。该退化操作可以表达为:
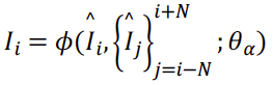
式中符号分别表示低分辨率视频的第i帧,高分辨率视频的第i帧,以i帧为中心的2N+1个高分辨率视频帧,及退化操作。通常退化操作为下采样,模糊,以及运动形变等。现实情况中,退化可能更加复杂,如颜色空间转换、压缩等。超分算法的目标即求解该退化过程的逆操作:
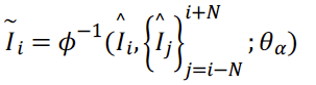
02
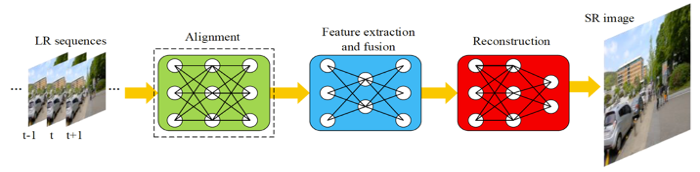
视频超分可以利用相邻帧间的信息,从而极大提高超分算法的性能。根据使用相邻帧间的信息的方法,对超分算法进行简单的分类:相邻帧进行对齐和非对齐两类。其中对齐算法又可以分成使用运动估计和运动补偿(MEMC)以及使用可变卷积两类。非对齐算法可分成二维卷积、三维卷积、RCNN、Non-Local。具体分类可图5,
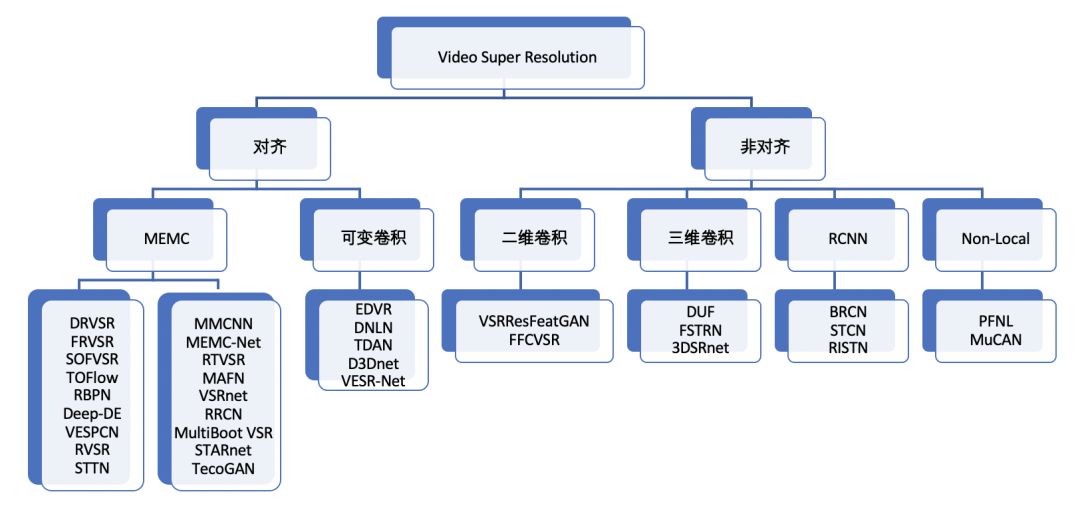
图5 视频超分算法分类
运动估计和补偿算法在视频超分中有着非常重要的作用,很多算法都以此为基础。运动估计是为了提取出帧间的运动信息,然后根据运动信息将不同的帧进行对齐。运动估计大多采用光流法,即通过计算帧间的时域相关性和变化,得到运动信息,如图6所示。运动补偿即利用运动信息来对相邻的帧进行处理,从而与要处理的帧进行对齐。常用的方法有线性插值和空域变换网络(STN)。

VSRnet
VSRnet是图像超分算法SRCNN在视频上的扩展,最大的改进就是增加了运动估计和运动补偿模块,输入图像由一幅变成多帧。运动信息的提取采用了Druleas算法。
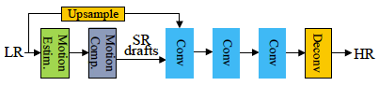
VESPCN
VESPCN即Video efficient sub-pixel convolutional network,引入了一个空域运动补偿变换模块(MCT),运动补偿后的帧作为卷积网络的输入,再经过特征提取和融合,最后经过一个亚像素卷积层做上采样得到高分辨率视频。MCT模块采用CNN由粗到精来提取运动信息、进行运动补偿。粗估网络以2个连续帧作为输入,经过5层卷积和1层亚像素卷积,得到粗略的光流运动信息,然后进行运动补偿。粗估网络的输入为粗估网络得到的光流信息和运动补偿帧,经过卷积网络得到更精细的运动信息和运动补偿帧。
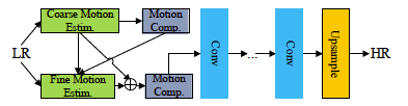
RBPN
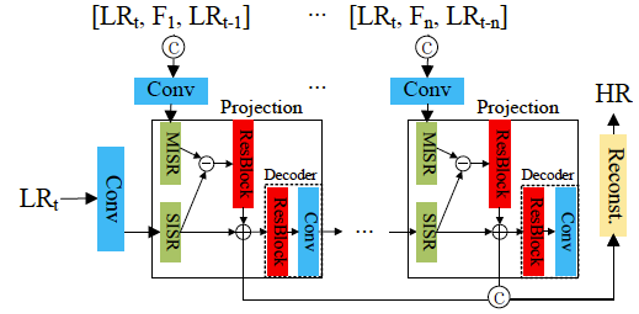
受后向投影算法的启发,RBPN算法设计了一个投影模块。投影模块位于特征提取模块和重建模块之间。特征提取分为两个部分,一是对目标帧的低分辨率进行特征提取,二是对目标帧、相邻帧、及两帧的光流图的组合进行特征提取。投影模块由编码器和解码器组成。编码器由单图超分模块(处理目标图得到的特征图)、多图超分模块(处理目标帧、相邻帧、及两帧的光流图的组合得到的特征图)和残差块组成(处理前述两个模块,得到残差),将残差图与单图超分的结果叠加,送入解码器,解码器由残差块和下采样卷积组成。解码器的输出进入下一个投影模块,将所有投影模块的解码器的输出送入重建模块,得到超分帧。投影模块可以重复使用,直到遍历所有的帧。
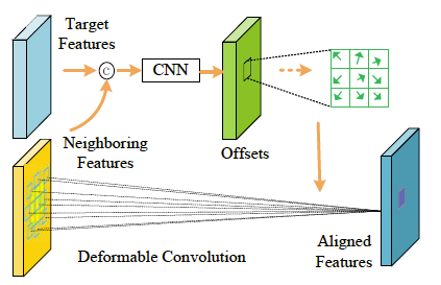
上述这一类的超分算法,其共同点是都运用运动估计和运动补偿技术来将相邻的图像与目标图像进行对齐,但是都无法保证运动信息的准确性,特别是当有光线变化或者较大的运动的时候。针对这点,可变形卷积被用来代替运动估计和补偿,来对齐图像。下述算法将对这种方法进行简要介绍。
可变卷积于2017年提出,与传统的卷积层不同的点是,传统卷积层,每一层都的核都是固定大小;可变卷积在核中加入了偏移量,如此以来,输入特征通过卷积操作,便可以更好地对几何模型进行变换。采用可变卷积的视频超分算法主要有EDVR,DNLN,TDAN,D3Dnet,VESR-Net。本文选取EDVR和VERSR-Net进行简要介绍。
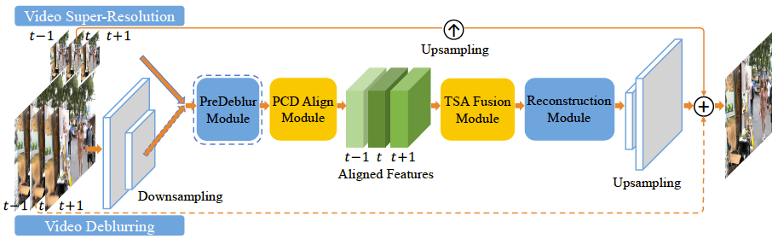
EDVR
该算法夺取了NTIRE19 Challenge的冠军。该算法有两个关键的模块:a、金字塔、级联和可变形对齐模块(PCD),用来解决复杂运动和大运动;b、时空注意融合模块(TSA),用来融合多个对齐的特征图。最后是重建模块。此外,输入模糊图像时,可以增加预处理模块来去模糊。该框架也可以用来进行其它类型的视频处理。
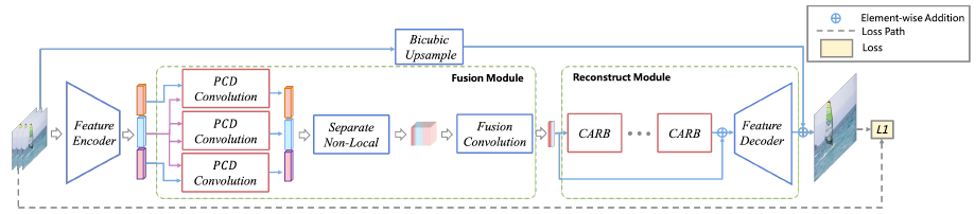
该算法夺得优酷视频增强和超分算法挑战赛的冠军。它由特征编码器,特征融合器和重建模块组成。特征编码器由一个卷积层和多个CARB组成。特征融合模式借鉴了EDVR算法中的PCD模块,用来进行特征帧对齐。然后将特征图分解,形成空域,时域和不同颜色通道的特征,然后将这些特征进行融合。重建模块先经过CARB模块,然后进行特征解码,最后将特征与双三次插值的得到的高分辨图进行叠加,得到最终结果。
非对齐超分算法
03
虽然视频超分的性能已经有了显著的提升,但深度神经网络的引入,使得训练和预测的计算复杂度、存储开销都非常高。随着移动设备的发展,高效轻量级网络的需求变得更为迫切。特别是在实时通信领域,对视频超分提出了更高的要求,由于实时通信还有更多模块使用计算资源,因此实时通信中的超分,不但需要极为简洁的设计,10毫秒级的处理算法才能真正落地;另外对帧的时延也有较高要求,往往目标帧之后的帧是不能作为输入,以减少时延,这对网络结构的设计也有更高的要求。
随着人工智能和设备运算能力的持续进步,视频质量恢复(Video Restoraion)在RTC系统中的地位必将水涨船高,而视频超分是视频质量恢复的最核心组件。在前文提到的技术基础之上,拍乐云也自研了可适配于主流移动设备的超分算法,并将持续投入开发,为用户提供更高品质的实时视频体验。
参考文献

交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
