
揭开http报文的神秘面纱


点击上方蓝色“迈莫coding”,选择“设为星标”
今天是计网的第二弹,主要叙述http报文的神秘面纱。相信大家在写项目中,或多或少遇到过,进行http访问时,header头部上需要加上Content-Type、Host等等,但有时候为了项目顺利完成,可能没有时间思考为什么需要加上他们,他们的含义是什么?......
今天就会揭开http报文的什么面纱,拭目以待......
计网以往文章
前言
在上一篇文章中谈了谈http的特点及其含义,由<<http到底有什么魔性,备受青睐>>文章知:http是超文本传输协议。那么问题来了,http传输的内容到底是什么,http报文组成成分又是什么?
接下来,泡一杯枸杞,慢慢聊一聊http报文的组成成分
http报文结构
http的请求报文和http响应报文结构基本类似,都是由三部分组成:
起始行(start line):描述请求或响应的基本信息
头部字段集合(header):使用 key-value 形式更详细地说明报文
消息正文(entity):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据
这其中前两部分起始行和头部字段经常又合称为“请求头”或“响应头”,消息正文又称为“实体”,但与“header”对应,很多时候就直接称为“body”。
HTTP 协议规定报文必须有 header,但可以没有 body,而且在 header 之后必须要有一个“空行”,也就是“CRLF”,十六进制的“0D0A”。
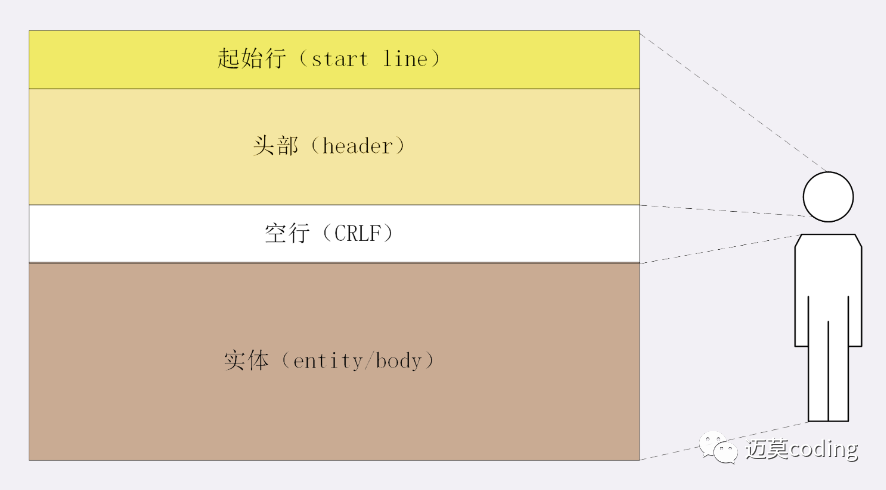
所以,一个完整的 HTTP 报文就像是下图的这个样子,注意在 header 和 body 之间有一个“空行”。
http 请求行
聊完http的报文结构,那么接下里看一下http请求报文组成结构的第一组成部分:http起始行(http请求行)。

由图可知,http请求行有三部分组成:
请求方法:如GET、POST请求方式,表示对资源的操作
请求地址:表示请求方法要操作的资源
版本号:表示报文所使用的http版本号
拿个实际的请求行来解释一下,加深影响
GET / HTTP/1.1在这个请求行里,“GET”是请求方法,“/”是请求目标,“HTTP/1.1”是版本号,把这三部分连起来,意思就是“服务器你好,我想获取网站根目录下的默认文件,我用的协议版本号是 1.1,请不要用 1.0 或者 2.0 回复我。”
http请求头部header
http请求头部用来说明服务器要使用的附加信息,他的结构类型是key-value形式。key和 value 之间用“:”分隔,最后用 CRLF 换行表示字段结束。比如请求头中"host:127.0.0.1",在这一行中"host"为key值,"127.0.0.1"为value值。
下面这张图展示了http请求报文所包含的信息,也会借此图详细说明每个header信息的作用及其含义。
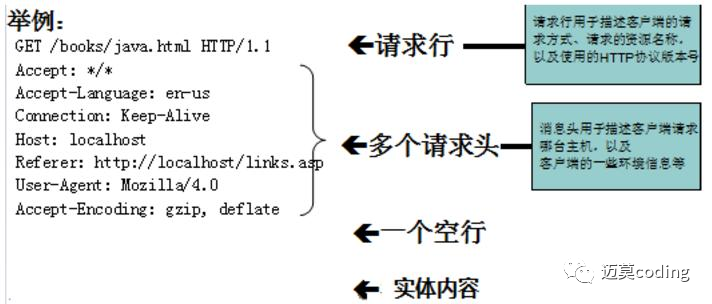
以这个图中的header头字段进行解释,比如Accept、Accept-Language、Connection、Host、Referer、User-Agent等等。
Host
Host表示将请求发送的目的地-服务端。告诉服务端由那些主机进行处理,当一台计算机上托管了多个虚拟主机的时候,服务器端就需要用 Host 字段来选择,有点像是一个简单的“路由重定向”。
Connection
Connection 表示当client和server通信时对于长链接如何进行处理,取值范围为【"Keep-Alive", "Close"】。
取值为【Keep-Alive】:若 client使用http1.1协议,但希望使用长链接,则需要在header中指明connection的值为Keep-Alive;如果server方 也想支持长链接,则在response中也需要明确说明connection的值为Keep-Alive。
取值为【Close】:若 client使用http1.1协议,但又不希望使用长链接,则需要在header中指明connection的值为close;如果server方 也不想支持长链接,则在response中也需要明确说明connection的值为close。
不论request还是response的header中包含了值为close的connection,都表明当前正在使用的tcp链接在当天请求处理完毕后会被断掉。以后client再进行新的请求时就必须创建新的tcp链接了。
User-Agent
User-Agent 用一个字符串表示发起请求的http客户端,服务器可以依据它来返回浏览器最适合的页面。
但由于历史的原因,User-Agent 非常混乱,每个浏览器都自称是“Mozilla”“Chrome”“Safari”,企图使用这个字段来互相“伪装”,导致 User-Agent 变得越来越长,最终变得毫无意义。
不过有的比较“诚实”的爬虫会在 User-Agent 里用“spider”标明自己是爬虫,所以可以利用这个字段实现简单的反爬虫策略。
Accept
Accept 标记客户端可以识别的MIME type,若支持多个类型的话,则用逗号进行分割;这样让服务端选择适合的类型进行返回。
例如 如下这个Accept 结构:
Accept: text/html,application/xml,image/webp,image/png这表示:告诉服务端,我(客户端)支持四种类型,HTML、XML 的文本,还有 webp 和 png 的图片,你需要按照我支持的类型进行返回,其他的类型我不认识。
Accept-Encoding
Accept-Encoding 表示客户端支持的压缩格式,例如gzip、deflate等,如果支持多个的话,也是以逗号进行分割。服务端就会按照客户端支持的压缩格式选择其中一种来进行压缩。
例如 如下Accept-Encoding 结构:
Accept-Encoding: gzip, deflate, br这表示:告诉服务端,我(客户端)支持的压缩格式有三种,你需要按照我支持的压缩格式进行压缩返回。
Accept-Language
Accept-Language 表示客户端支持的自然语言,如果支持多个话,也是以逗号进行分割。
例如 如下Accept-Language 结构
Accept-Language: zh-CN, zh, en这表示:告诉服务端,我(客户端)支持的自然语言有三种,但最后以zh-CN 格式给我,如果没有就用其他的汉语方言,如果还没有就给英文。
Content-Type
content-type 标记客户端中实体字段类型,指明body数据的类型,如果使用POST请求的话,需要添加上该字段属性。
例如 如下Content-Type 结构
Content-Type: application/json这表示:告诉服务端,我(客户端)传输的数据类型为application/json格式,你需要按照此格式类型进行解析数据。
到这里,http请求报文的细节已经到达尾声了,接下来,一起看一下http响应报文那些事儿~~~
http响应行
聊完了http请求行、请求头部的一些字段属性,那么接下里聊一聊http响应报文的响应行、响应头部。首先,我们先聊一聊响应行,格式如下所示:

由图可知,响应行由三部分组成:
版本号:http协议版本号。
状态码:一个三位数,用代码的形式表示处理的结果,比如 200 是成功,500 是服务器错误。
原因:作为数字状态码补充,是更详细的解释文字,帮助人理解原因。
举例说明一下响应行:
HTTP/1.1 200 OK这表示:浏览器你好,我已经处理完了你的请求,这个报文使用的协议版本号是 1.1,状态码是 200,一切OK。”
http响应头部
说完了响应行,那么接下来看一下http的响应头部。下面这张图展示了http响应报文所包含的信息,也会借此图详细说明每个header信息的作用及其含义。
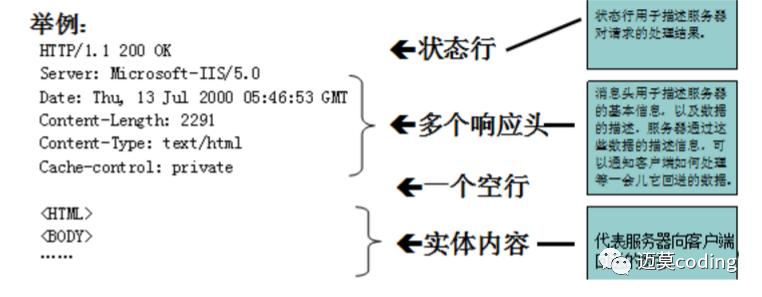
Server
Server 响应字段,它告诉客户端正在提供web服务的软件名称和版本号,但这个字段不是非必须的,一般网站都不会暴露自己真实的服务名称,反正黑客进行攻击,一般会填写无关紧要的信息,比如 Nginx.com。
比如GitHub网址,server 字段中看不出是使用了nginx还是Apache。server字段如下:
Server: GitHub.comDate
Date 表示http报文创建的时间,目的让客户端使用该字段和其他字段配合起来决定缓存策略。
Content-Type
Content-Type 标记服务端返回给客户端的结构类型,和请求头部中的Content-Type使用方式一样。
例如 Content-Type格式如下
Content-Type: application/json这表示:服务端返回给客户端的数据结构类型为application/json。
Content-Length
Content-Length 报文里body 的长度,也就是请求头或响应头空行后面数据的长度。服务器看到这个字段,就知道了后续有多少数据,可以直接接收。如果没有这个字段,那么 body 就是不定长的,需要使用 chunked 方式分段传输。
Content-Language
Content-Language 告诉客户端实体数据使用的实际语言类型
Content-Encoding
Content-Encoding 告诉客户端实体数据是使用那个压缩格式进行压缩的
到这里,http响应报文的细节已经到达尾声了,相信大家都有不一样的体会~~~
总结
今天我们聊了一下http报文那些事儿,在这儿做一个简单的小结。
http报文结构由三部分组成:起始行+头部字段集合+消息主体
http报文可以没有消息主体,但一定有起起始行+头部字段集合
请求报文中请求行由三部分组成:请求方法+请求URI资源地址+http协议版本号
响应报文中响应行由三部分组成:http协议版本号+状态码+原因
头部字段是 key-value 的形式,用“:”分隔,不区分大小写,顺序任意,除了规定的标准头,也可以任意添加自定义字段,实现功能扩展
http请求头字段中常用的字段:Host、Accept、Accept-Encoding、Accept-Language、Content-Type、Connection
http响应字段中常用的字段:Server、Date、Content-Type、Content-Language、Content-Encoding、Content-Length
读到这里,相信大家也对http报文有了不一样的理解。好了,今天就到这里,我们下期再见~~~
我叫迈莫,普普通通的互联网打工人
分割线
往期推荐
文章也会持续更新,可以微信搜索「 迈莫coding 」第一时间阅读。每天分享优质文章、大厂经验、大厂面经,助力面试,是每个程序员值得关注的平台。
你点的每个赞,我都认真当成了喜欢