
MySQL 8.0 MVCC 核心源码解析
并发事务带来的问题(现象)
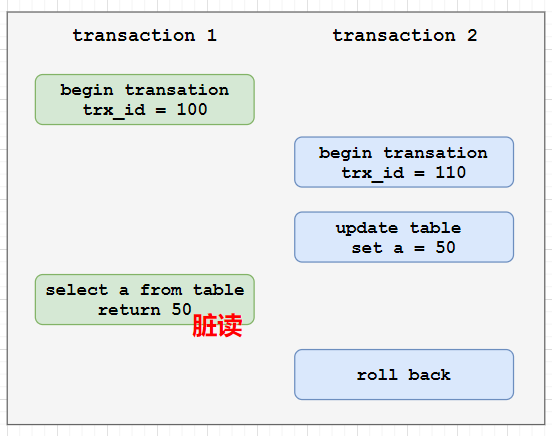
脏读:一个事务读取到另一个事务更新但还未提交的数据,如果另一个事务出现回滚或者进一步更新,则会出现问题。
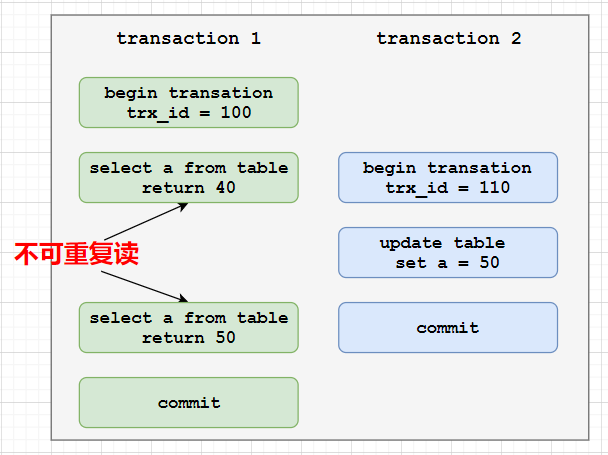
不可重复读:在一个事务中两次次读取同一个数据时,由于在两次读取之间,另一个事务修改了该数据,所以出现两次读取的结果不一致。
核心数据结构
trx_sys_t:事务系统中央存储器数据结构
struct trx_sys_t {TrxSysMutex mutex; /*! 互斥锁 */MVCC *mvcc; /*! mvcc */volatile trx_id_t max_trx_id; /*! 要分配给下一个事务的事务id*/std::atomic<trx_id_t> min_active_id; /*! 最小的活跃事务Id */// 省略...trx_id_t rw_max_trx_id; /*!< 最大读写事务Id */// 省略...trx_ids_t rw_trx_ids; /*! 当前活跃的读写事务Id列表 */Rsegs rsegs; /*!< 回滚段 */// 省略...};
MVCC:MVCC 读取视图管理器
class MVCC {public:// 省略.../** 创建一个视图 */void view_open(ReadView *&view, trx_t *trx);/** 关闭一个视图 */void view_close(ReadView *&view, bool own_mutex);/** 释放一个视图 */void view_release(ReadView *&view);// 省略.../** 判断视图是否处于活动和有效状态 */static bool is_view_active(ReadView *view) {ut_a(view != reinterpret_cast(0x1)); return (view != NULL && !(intptr_t(view) & 0x1));}// 省略...private:typedef UT_LIST_BASE_NODE_T(ReadView) view_list_t;/** 空闲可以被重用的视图*/view_list_t m_free;/** 活跃或者已经关闭的 Read View 的链表 */view_list_t m_views;};
ReadView:视图,某一时刻的一个事务快照
class ReadView {// 省略...private:/** 高水位,大于等于这个ID的事务均不可见*/trx_id_t m_low_limit_id;/** 低水位:小于这个ID的事务均可见 */trx_id_t m_up_limit_id;/** 创建该 Read View 的事务ID*/trx_id_t m_creator_trx_id;/** 创建视图时的活跃事务id列表*/ids_t m_ids;/** 配合purge,标识该视图不需要小于m_low_limit_no的UNDO LOG,* 如果其他视图也不需要,则可以删除小于m_low_limit_no的UNDO LOG*/trx_id_t m_low_limit_no;/** 标记视图是否被关闭*/bool m_closed;// 省略...};
增加隐藏字段
为了实现 MVCC,InnoDB 会向数据库中的每行记录增加三个字段:
源码分析
在源码中,添加这3个字段的方法在:/storage/innobase/dict/dict0dict.cc 的 dict_table_add_system_columns 方法中,核心部分如下图。

增删改的底层操作
当我们更新一条数据,InnoDB 会进行如下操作:
加锁:对要更新的行记录加排他锁
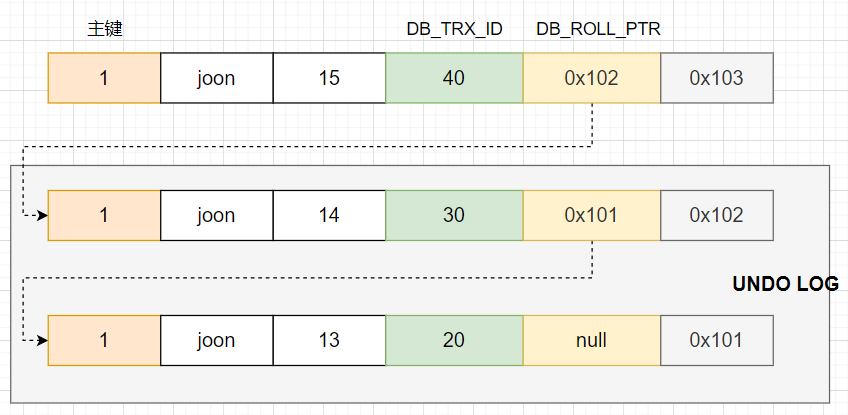
写 undo log:将更新前的记录写入 undo log,并构建指向该 undo log 的回滚指针 roll_ptr
更新行记录:更新行记录的 DB_TRX_ID 属性为当前的事务Id,更新 DB_ROLL_PTR 属性为步骤2生成的回滚指针,将此次要更新的属性列更新为目标值
写 redo log:DB_ROLL_PTR 使用步骤2生成的回滚指针,DB_TRX_ID 使用当前的事务Id,并填充更新后的属性值
处理结束,释放排他锁
删除操作:在底层实现中是使用更新来实现的,逻辑基本和更新操作一样,几个需要注意的点:1)写 undo log 中,会通过 type_cmpl 来标识是删除还是更新,并且不记录列的旧值;2)这边不会直接删除,只会给行记录的 info_bits 打上删除标识(REC_INFO_DELETED_FLAG),之后会由专门的 purge 线程来执行真正的删除操作。
插入操作:相比于更新操作比较简单,就是新增一条记录,DB_TRX_ID 使用当前的事务Id,同样会有 undo log 和 redo log。
源码分析
更新行记录的核心源码在:/storage/innobase/btr/btr0cur.cc/btr_cur_update_in_place 方法,核心部分如下图。

构建一致性读取视图(ReadView)
m_ids:创建 ReadView 时当前系统中活跃的事务 Id 列表,可以理解为生成 ReadView 那一刻还未执行提交的事务,并且该列表是个升序列表。 m_up_limit_id:低水位,取 m_ids 列表的第一个节点,因为 m_ids 是升序列表,因此也就是 m_ids 中事务 Id 最小的那个。 m_low_limit_id:高水位,生成 ReadView 时系统将要分配给下一个事务的 Id 值。 m_creator_trx_id:创建该 ReadView 的事务的事务 Id。
row_search_mvcc -> trx_assign_read_view -> MVCC::view_open ->
ReadView::prepare,源码如下:
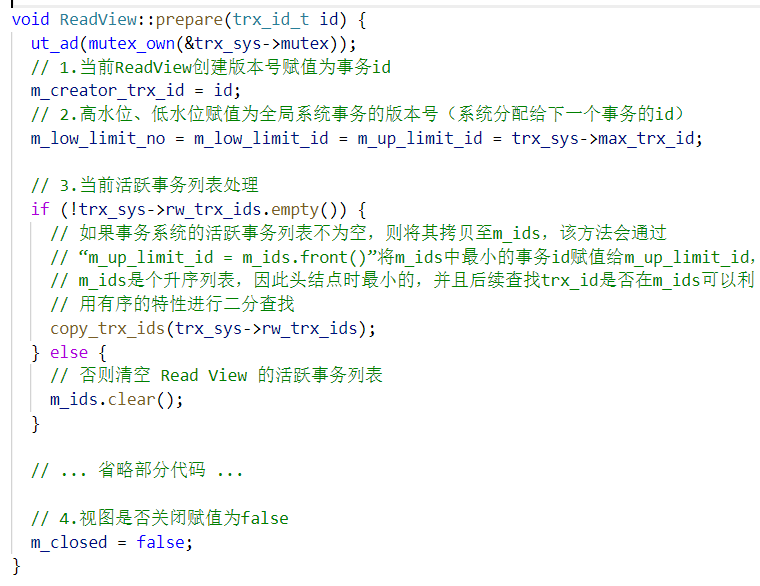
最后,会将这个创建的 ReadView 添加到 MVCC 的 m_views 中。
视图可见性判断:SQL 查询走聚簇索引
如果被访问版本的 trx_id 与 ReadView 中的 m_creator_trx_id 值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
如果被访问版本的 trx_id 小于 ReadView 中的 m_up_limit_id(低水位),表明被访问版本的事务在当前事务生成 ReadView 前已经提交,所以该版本可以被当前事务访问。
如果被访问版本的 trx_id 大于等于 ReadView 中的 m_low_limit_id(高水位),表明被访问版本的事务在当前事务生成 ReadView 后才开启,所以该版本不可以被当前事务访问。
如果被访问版本的 trx_id 属性值在 ReadView 的 m_up_limit_id 和 m_low_limit_id 之间,那就需要判断 trx_id 属性值是不是在 m_ids 列表中,这边会通过二分法查找。如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
源码分析
走聚簇索引的核心流程在 row_search_mvcc 方法,如下:
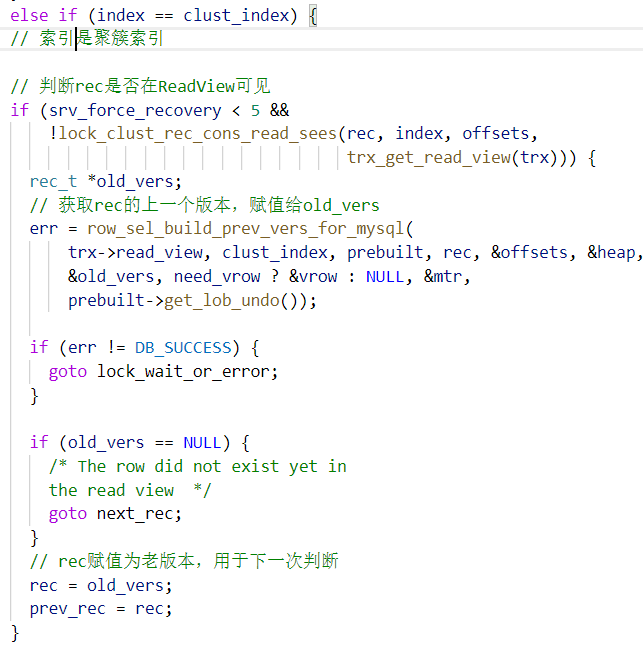
视图可见性判断在方法:changes_visible,调用链如下:
row_search_mvcc -> lock_clust_rec_cons_read_sees ->
changes_visible,源码如下:

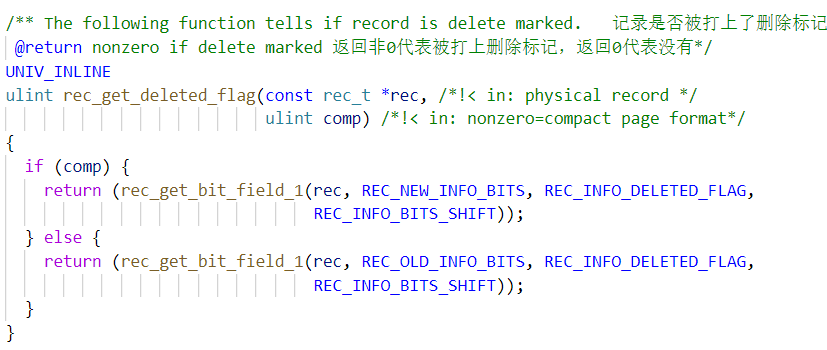
判断记录是否被打上 delete_flag 标的方法在:/storage/innobase/include/rem0rec.ic 的 rec_get_deleted_flag 方法中,如下图。
获取记录的上一个版本
获取记录的上一个版本,主要是通过 DB_ROLL_PTR 来实现,核心流程如下:
获取记录的回滚指针 DB_ROLL_PTR、获取记录的事务Id
通过回滚指针拿到对应的 undo log
解析 undo log,并使用 undo log 构建用于更新向量 UPDATE
构建记录的上一个版本:先用记录的当前版本填充,然后使用 UPDATE(undo log)进行覆盖。
源码解析
构建记录的上一个版本:trx_undo_prev_version_build,调用链如下:
row_search_mvcc -> row_sel_build_prev_vers_for_mysql -> row_vers_build_for_consistent_read -> trx_undo_prev_version_build,源码如下:

视图可见性判断:SQL 查询走普通(二级)索引
BATJTMD 面试必问的 MySQL,你懂了吗? 只分析了走聚簇索引的情况,本文简单的介绍下走普通(二级)索引的情况。
当走普通索引时,判断逻辑如下:
判断被访问索引记录所在页的最大事务 Id 是否小于 ReadView 中的 m_up_limit_id(低水位),如果是则代表该页的最后一次修改事务 Id 在 ReadView 创建前以前已经提交,则必然可以访问;如果不是,并不代表一定不可以访问,道理跟走聚簇索引一样,事务 Id 大的也可能提交比较早,所以需要做进一步判断,见步骤2。
使用 ICP(Index Condition Pushdown)根据索引信息来判断搜索条件是否满足,这边主要是在使用聚簇索引判断前先进行过滤,这边有三种情况:a)ICP 判断不满足条件但没有超出扫描范围,则获取下一条记录继续查找;b)如果不满足条件并且超出扫描返回,则返回 DB_RECORD_NOT_FOUND;c)如果 ICP 判断符合条件,则会获取对应的聚簇索引来进行可见性判断。
源码分析
普通(非聚簇)索引的视图可见性判断在方法:lock_sec_rec_cons_read_sees,调用链如下:
row_search_mvcc -> lock_sec_rec_cons_read_sees,源码如下:


扩展理解
ICP(Index Condition Pushdown)
ICP 是 MySQL 5.6 引入的一个优化,根据官方的说法:ICP 可以减少存储引擎访问基表的次数 和 MySQL 访问存储引擎的次数,这边涉及到 MySQL 底层的处理逻辑,不是本文重点,这边不进行细讲。
这边用官方的例子简单介绍下,我们有张 people 表,索引定义为:INDEX (zipcode, lastname, firstname),对于以下这个 SQL:
SELECT * FROM peopleWHERE zipcode='95054'AND lastname LIKE '%etrunia%'AND address LIKE '%Main Street%';
当没有使用 ICP 时:此查询会使用该索引,但是必须扫描 people 表所有符合 zipcode='95054' 条件的记录。
当使用 ICP 时:不仅会使用 zipcode 的条件来进行过滤,还会使用 (lastname LIKE '%etrunia%')来进行过滤,这样可以避免扫描符合 zipcode 条件而不符合 lastname 条件匹配的记录行 。
ICP 的官方文档:https://dev.mysql.com/doc/refman/8.0/en/index-condition-pushdown-optimization.html
当前读和快照读
当前读:官方叫做 Locking Reads(锁定读取),读取数据的最新版本。常见的 update/insert/delete、还有 select ... for update、select ... lock in share mode 都是当前读。
官方文档:https://dev.mysql.com/doc/refman/8.0/en/innodb-locking-reads.html
快照读:官方叫做 Consistent Nonlocking Reads(一致性非锁定读取,也叫一致性读取),读取快照版本,也就是 MVCC 生成的 ReadView。用于普通的 select 的语句。
官方文档:https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html
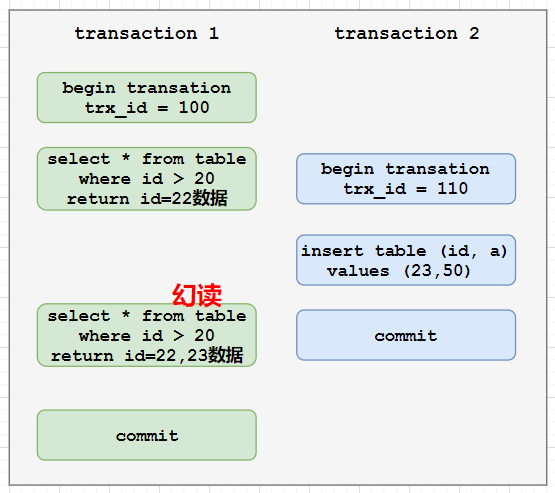
MVCC 解决了幻读了没有?
几个例子
例子1:RR(RC) 真正生成 ReadView 的时机
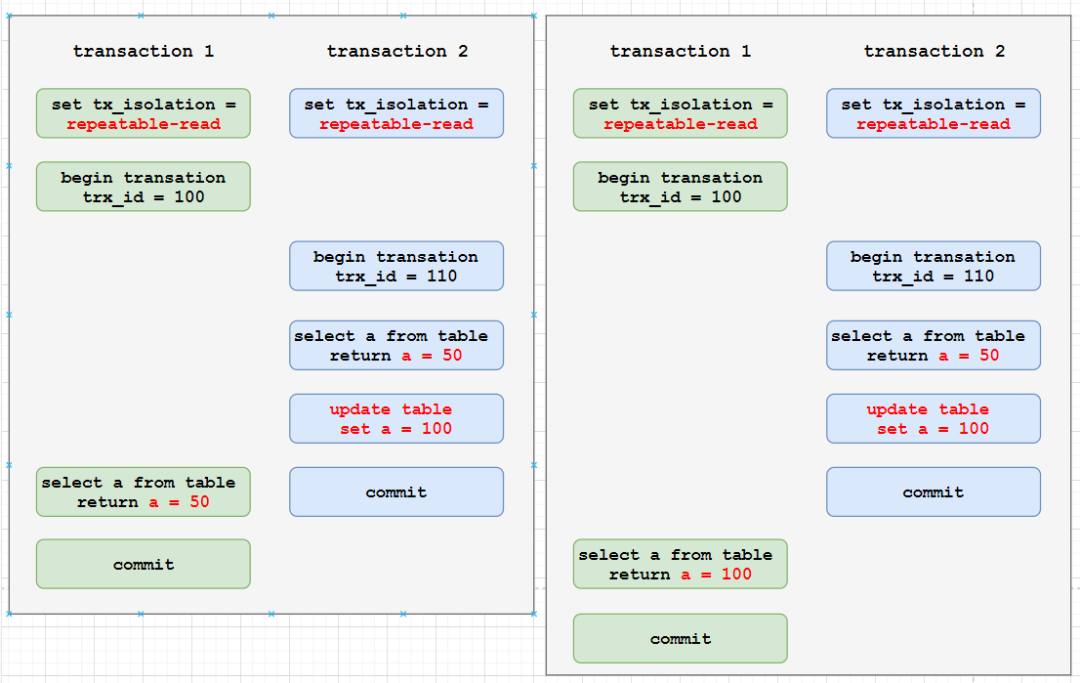
解析:RR 生成 ReadView 的时机是事务第一个 select 的时候,而不是事务开始的时候。右边的例子中,事务1在事务2提交了修改后才执行第一个 select,因此生成的 ReadView 中,a 的是 100 而不是事务1刚开始时的 50。
例子2:RR 和 RC 生成 ReadView 的区别
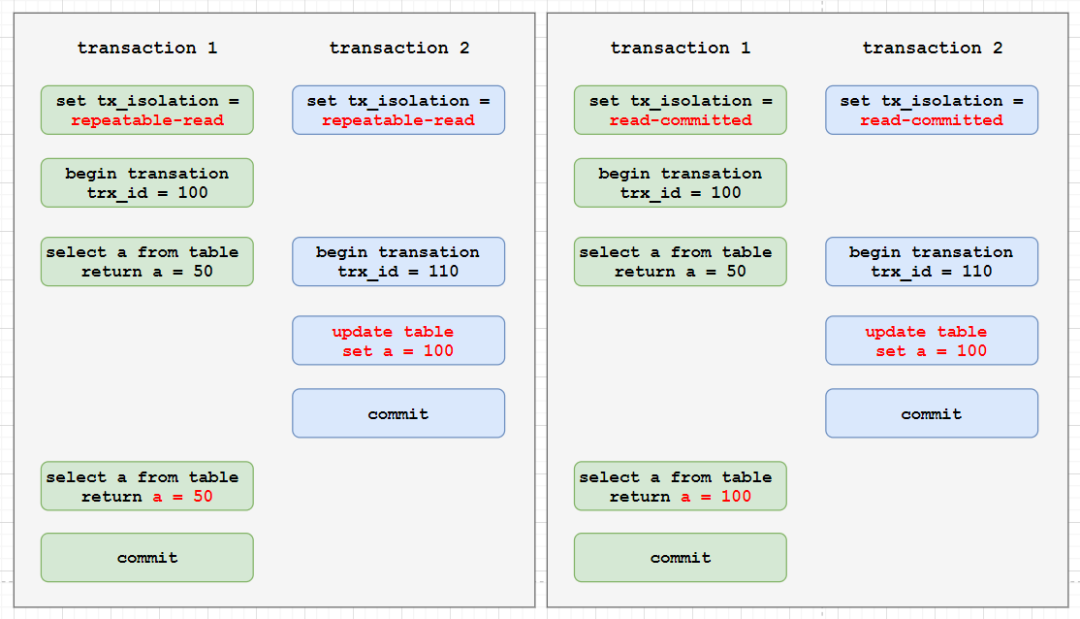
解析:RR 级别只在事务第一次 select 时生成一次,之后一直使用该 ReadView。而 RC 级别则在每次 select 时,都会生成一个 ReadView,所以 在第二次 select 时,读取到了事务2对于 a 的修改值。
最后
MySQL 的源码主要是 c++ 写的,因此自己看起来比较吃力,花了挺多时间学习整理的。如果你能掌握本文的内容,面试 Java 岗位,无论是哪个公司,相信都能让面试官眼前一亮。
现在互联网的竞争越来越激烈,如果很多东西都只停留在表面,很难取得面试官的“芳心”,只有在适当的时候亮出自己的“长剑”,才能在众多候选人中凸显出自己的与众不同。你需要向面试官证明,为什么是你而不是其他人。