
盘点一个Python自动化办公的实战案例
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python钻石交流群【Hxy任我肥】问了一个Python自动化办公的问题,提问截图如下:
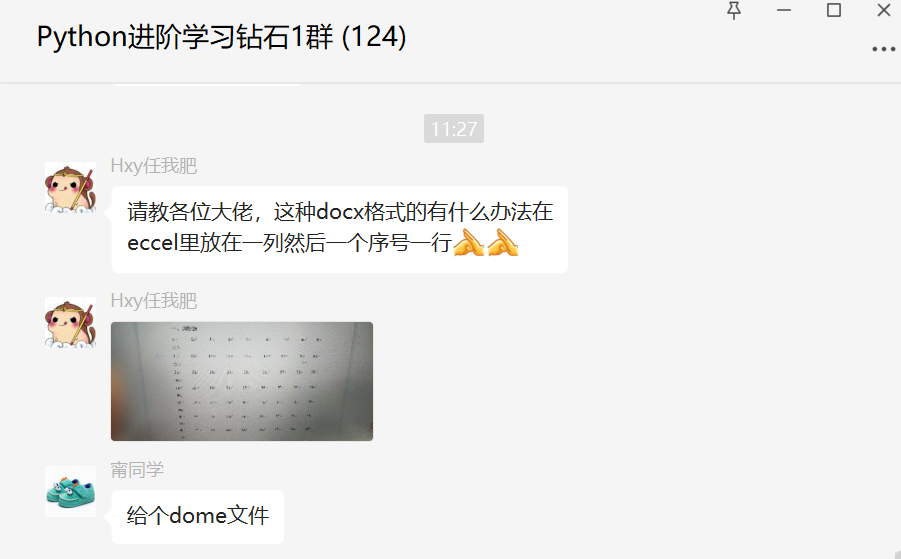
想要的效果是下图这样的:
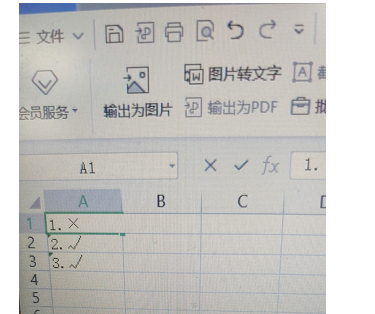
准确来说,这个都不算是问题了,而是一个实实在在的需求。
二、实现过程
这里【Jason】给了一个可行的思路,如下:
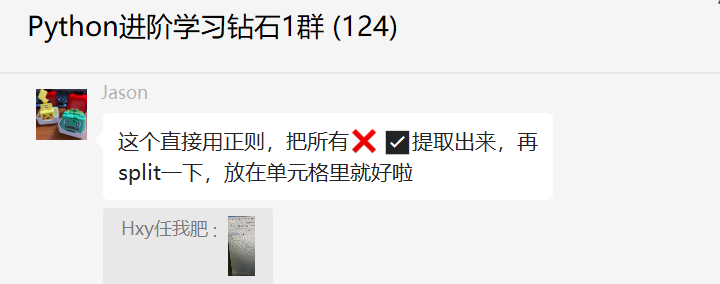
后来【瑜亮老师】给了一个具体的代码,如下所示:
import re
from docx import Document
import pandas as pd
document = Document("判断(括号处理)(1).docx")
all_paragraphs = document.paragraphs
data = [paragraph.text for paragraph in all_paragraphs if '√' in paragraph.text or '×' in paragraph.text]
data = ''.join(data)
res = re.findall('[√×]', data, re.S)
res = [f'{k + 1}.{v}' for k, v in enumerate(res)]
df = pd.DataFrame(res)
df.to_excel('test9-13.xlsx', index=False, header=None)
真的太强了!
代码运行之后可以得到预期的结果,如下图所示:

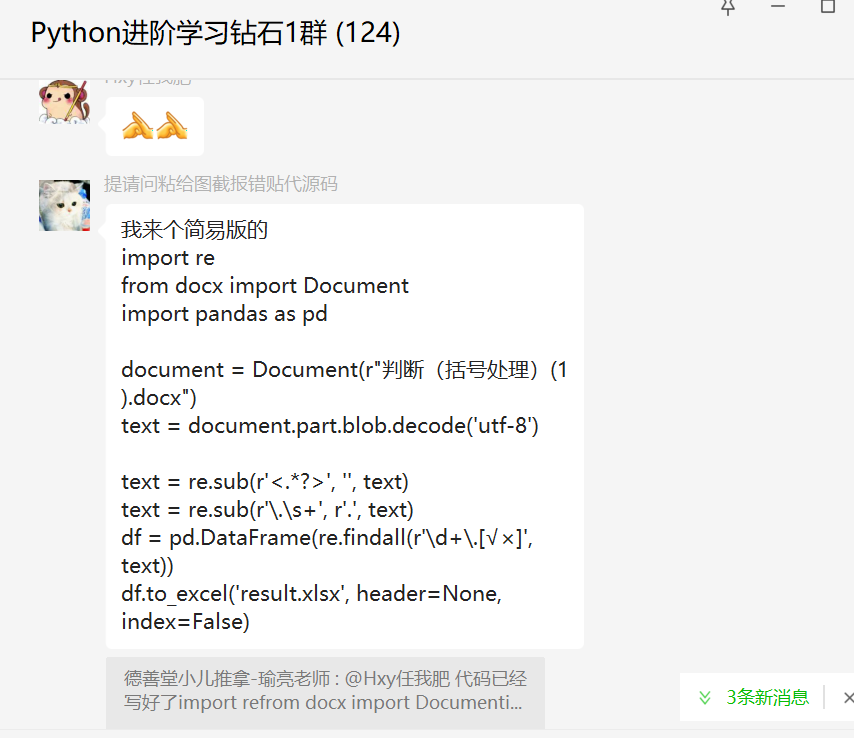
后来【狂吃山楂片】基于此代码,来了个简易版的,代码如下所示:
import re
from docx import Document
import pandas as pd
document = Document(r"判断(括号处理)(1).docx")
text = document.part.blob.decode('utf-8')
text = re.sub(r'<.*?>', '', text)
text = re.sub(r'\.\s+', r'.', text)
df = pd.DataFrame(re.findall(r'\d+\.[√×]', text))
df.to_excel('result.xlsx', header=None, index=False)
这技术真是到家了,出神入化的。
代码运行之后,也完全可以实现这个需求。
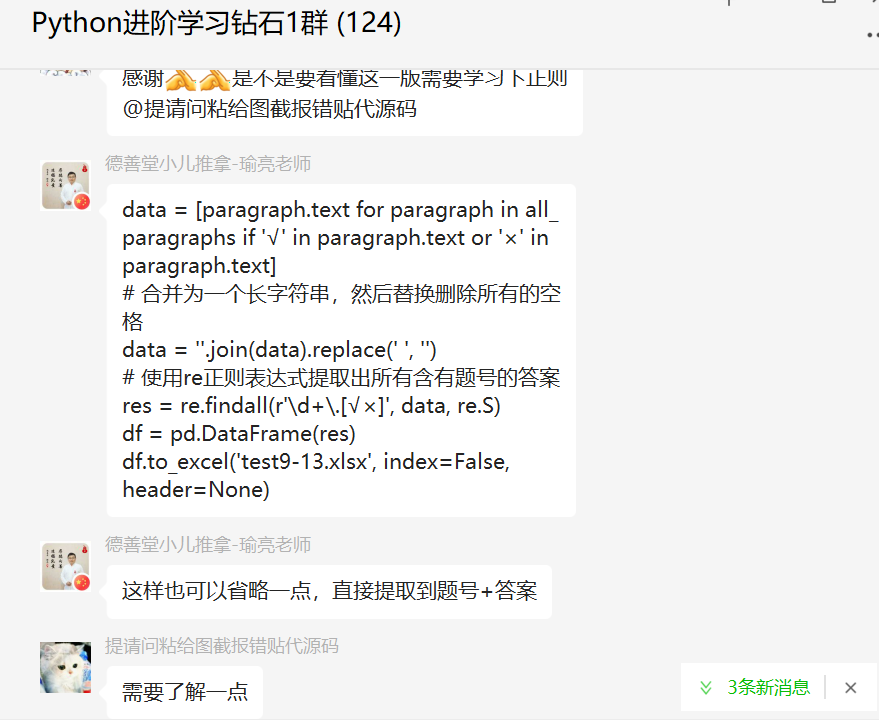
后来【瑜亮老师】还给了一个代码,也非常赞,如下所示:
data = [paragraph.text for paragraph in all_paragraphs if '√' in paragraph.text or '×' in paragraph.text]
# 合并为一个长字符串,然后替换删除所有的空格
data = ''.join(data).replace(' ', '')
# 使用re正则表达式提取出所有含有题号的答案
res = re.findall(r'\d+\.[√×]', data, re.S)
df = pd.DataFrame(res)
df.to_excel('test9-13.xlsx', index=False, header=None)
真让人叹为观止!把多余的空格都替换删除,可以防止答案中含有空格而导致不能被正则r'\d+\.[√×]'匹配到,这样就一步到位了。不用再用列表推导式构造答案。
你以为这就完事了?
后来【甯同学】使用openpyxl库也搞定了,代码如下图所示:
import re
import docx
import openpyxl
def str_work(string:str):
return [*filter(None,re.split('\.',re.sub('\d+','',string.replace(' ', '').replace('\n', ''))))]
wb = openpyxl.Workbook()
ws = wb.active
ws.append(['题目','答案'])
doc = docx.Document(r'C:\Users\Administrator\Desktop\判断(括号处理).docx')
doc_text = '\n'.join(( i.text for i in doc.paragraphs[3:]))
doc_list = doc_text.split('\n一、判断题')
title_row = [i.strip() for i in doc_list[0].split('\n') if i.strip().split('、')!=['']]
answer_row = [i for i in str_work(doc_list[1])]
for i in zip(title_row,answer_row):
ws.append(list(i))
wb.save('1.xlsx')
运行之后得到的结果如下图所示:

三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python自动化办公的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【Hxy任我肥】提问,感谢【Jason】、【瑜亮老师】、【狂吃山楂片】、【甯同学】给出的思路和代码解析,感谢【dcpeng】、【产后修复】、【此类生物】、【余克富】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群,欢迎大家加入我的Python学习交流群!

有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行