
ICCV 2021: 手绘图变动画
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
新智元报道
新智元报道
来源:arXiv 编辑:LRS
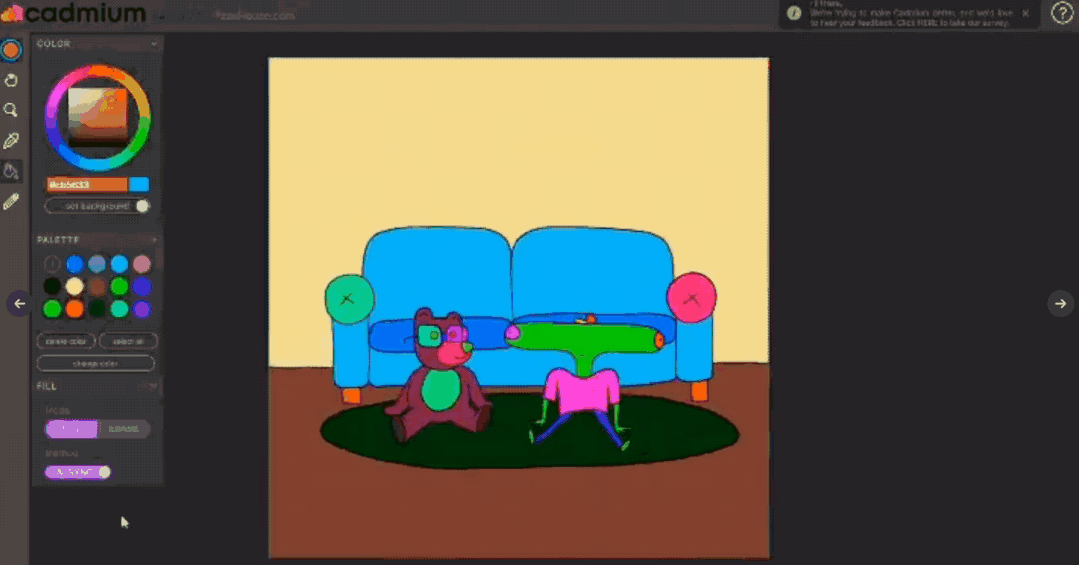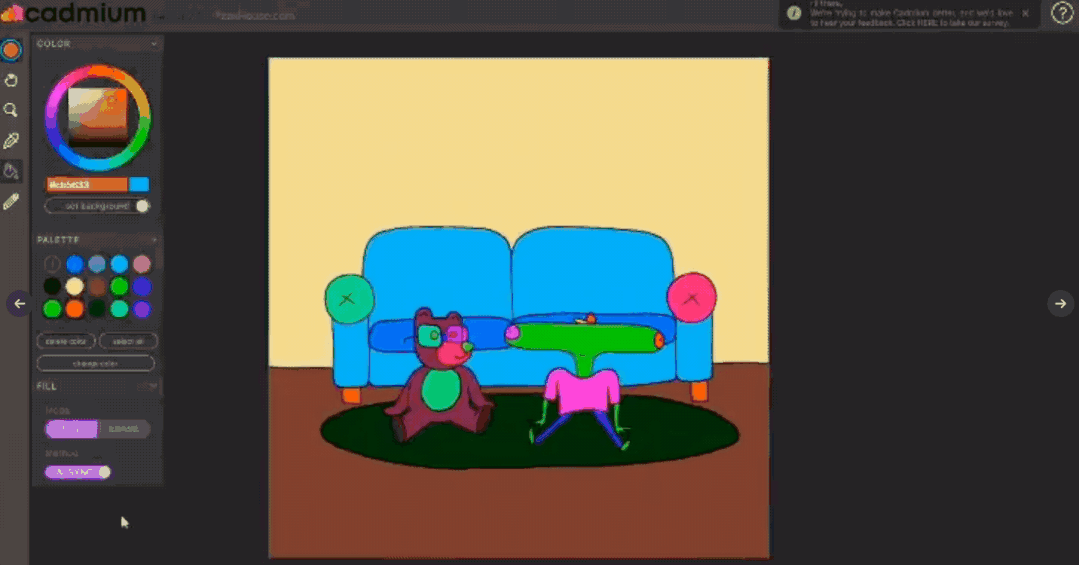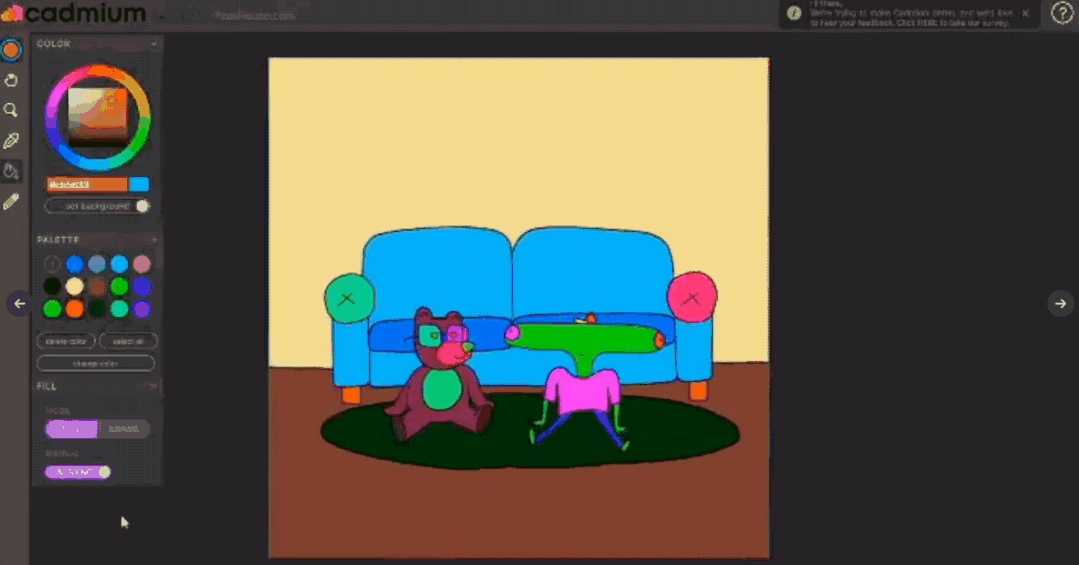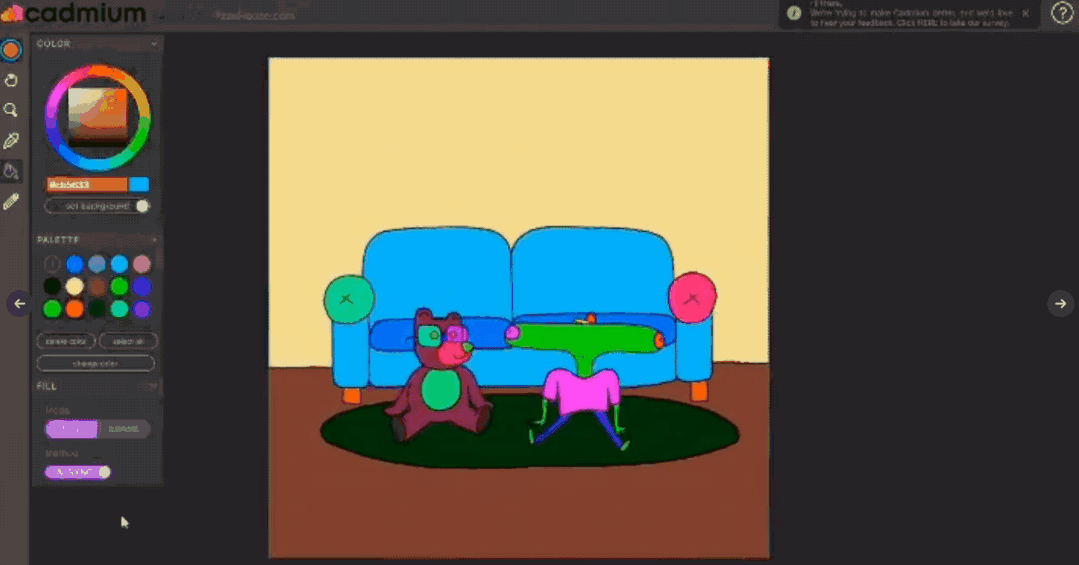
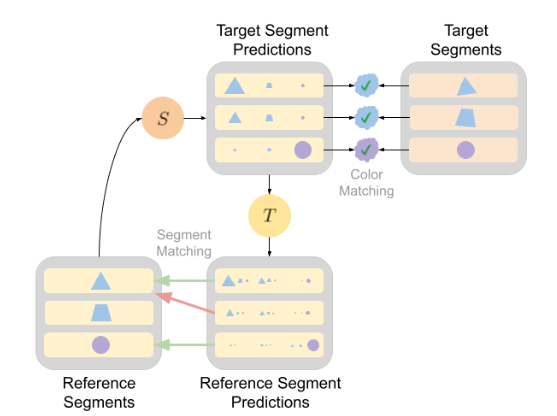
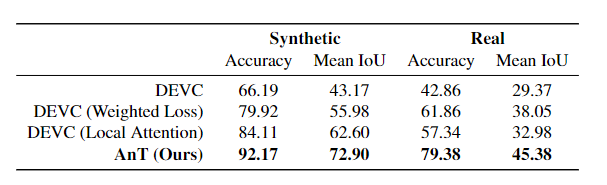
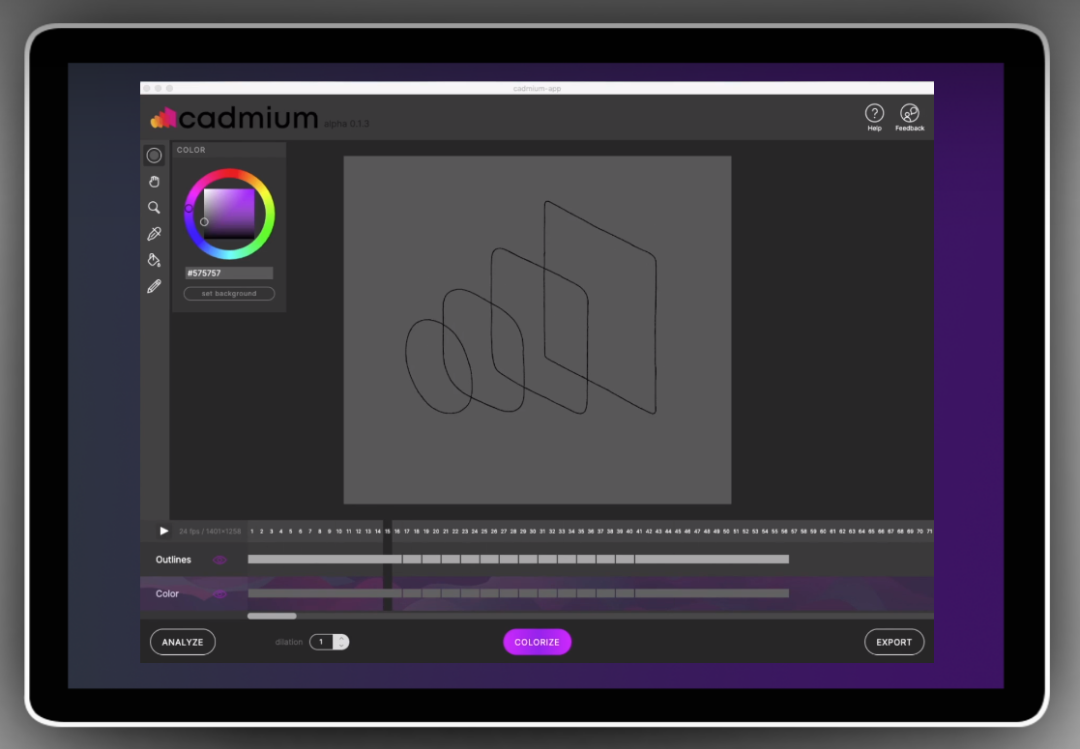
【新智元导读】有了AI技术的加持以后,普通人借助各种辅助工具可以很容易地进行艺术创作!这次有一个AI公司带来了一个让手绘图动起来的app,现在已经开放测试体验,还发表了一篇论文来介绍具体使用的技术,相比以往的研究,准确率提升超10个点!


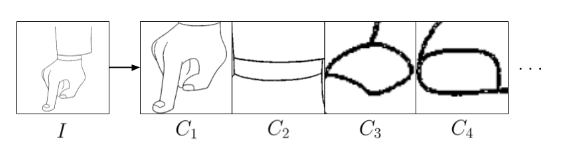
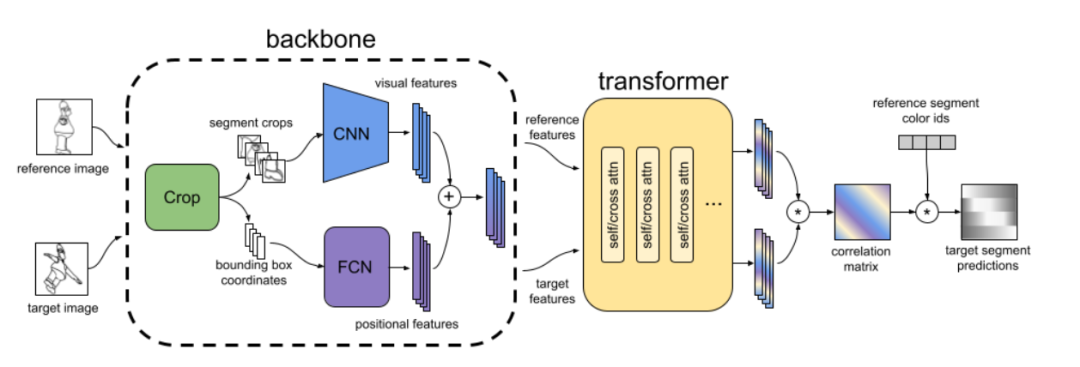
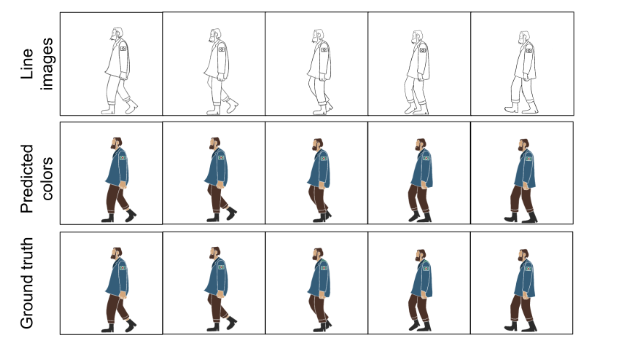

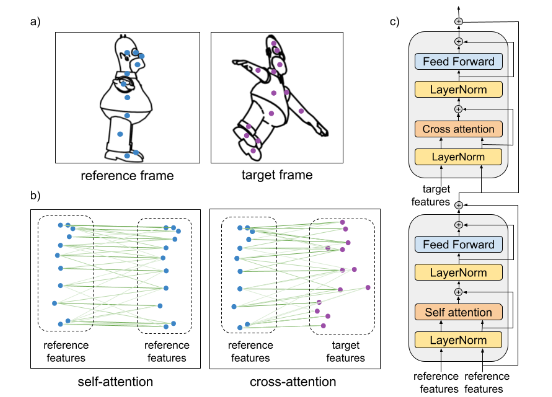
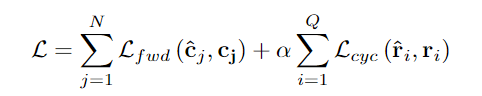
参考资料:
https://arxiv.org/abs/2109.0261
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论