
深入探讨:残差网络解决了什么,为什么有效?

极市导读
本文从深度神经网络的两大难题入手,介绍了残差网络的形式化定义与实现,并深入探讨其作用的机制,并结合文献对残差网络有效性进行了一些可能的解释。>>加入极市CV技术交流群,走在计算机视觉的最前沿
0. 引言
残差网络是深度学习中的一个重要概念。这篇文章将简单介绍残差网络的思想,并结合文献讨论残差网络有效性的一些可能解释。
以下是本文的概览:
动机: 深度神经网络的“两朵乌云” 残差网络的形式化定义与实现 残差网络解决了什么,为什么有效? 自然语言处理中的残差结构 总结与扩展
1. 动机: 深度神经网络的“两朵乌云”
神经网络具有非常强的表达能力,并且免去了繁重的特征工程,在BP算法提出以及算力逐渐提升的背景下,逐渐受到了研究人员和开发者的青睐。
在展开文章前,首先以_前馈神经网络_为例,定义一下神经网络。一个前馈神经网络 ,由若干层神经元组成,为了方便讨论,我们以非线性单元(若干层神经元组成的函数单元)为单位讨论神经网络,即神经网络 由 个非线性单元堆叠而成(后面将每个单元称为一层),令 ,则神经网络第 层( )的净输入 与输出 的计算由下式给出:
其中, 是该层的内部运算,依照网络类型有所不同;是第 层的输出激活函数。
一般认为,经过训练的深度神经网络能够将数据特征逐层抽象,最终提取出完成任务所需要的特征/表示,最终使用一个简单的分类器(或其他学习器),就可以完成最终任务——因此深度学习也被叫做表示/特征学习。
在“层层抽象”的直觉下,很自然的想法就是,训练一个很深的前馈神经网路,来完成任务。直观上看,更深的神经网络,在非线性激活函数的加持下,拥有更大的假设空间,因此当然“更有可能”包含了一个最优解。但是在实际使用时,训练又成了一个难题。除了过拟合问题以外,更深的神经网络会遇到如下两个难题,我姑且按照物理史的比喻将其称为深度神经网络的“两朵乌云”:
1.1 梯度弥散/爆炸
现代神经网络一般是通过基于梯度的BP算法来优化,对前馈神经网络而言,一般需要前向传播输入信号,然后反向传播误差并使用梯度方法更新参数。第 层的某参数更新需要计算损失 对其的梯度,该梯度依赖于该层的误差项 ,根据链式法则,又依赖于后一层的误差项:
假设网络单元输入输出维度一致,定义 ,则有
当 时,第 层的误差项较后一层减小,如果很多层的情况都是如此,就会导致反向传播中,梯度逐渐消失,底层的参数不能有效更新,这也就是梯度弥散(或梯度消失);当 时,则会使得梯度以指数级速度增大,造成系统不稳定,也就是梯度爆炸问题。
在很深层的网络中,由于不能保证 的大小,也很容易出现梯度弥散/爆炸。这是两朵乌云中的第一朵。
1.2 网络退化问题
在前面的讨论中,梯度弥散/爆炸问题导致模型训练难以收敛,但是这个问题很大程度上已经被标准初始化和中间层正规化方法有效控制了,这些方法使得深度神经网络可以收敛。深度神经网络面临的另一朵乌云是网络退化问题:
在神经网络可以收敛的前提下,随着网络深度增加,网络的表现先是逐渐增加至饱和,然后迅速下降[1]。
需要注意,网络退化问题不是过拟合导致的,即便在模型训练过程中,同样的训练轮次下,退化的网络也比稍浅层的网络的训练错误更高,如下图[1]所示。

这一点并不符合常理:如果存在某个 层的网络 是当前最优的网络,那么可以构造一个更深的网络,其最后几层仅是该网络第层输出的恒等映射(Identity Mapping),就可以取得与一致的结果;也许还不是所谓“最佳层数”,那么更深的网络就可以取得更好的结果。总而言之,与浅层网络相比,更深的网络的表现不应该更差。因此,一个合理的猜测就是,对神经网络来说,恒等映射并不容易拟合。
也许我们可以对网络单元进行一定的改造,来改善退化问题?这也就引出了残差网络的基本思路...
2. 残差网络的形式化定义与实现
既然神经网络不容易拟合一个恒等映射,那么一种思路就是构造天然的恒等映射。假设神经网络非线性单元的输入和输出维度一致,可以将神经网络单元内要拟合的函数 拆分成两个部分,即:
其中 是残差函数。在网络高层,学习一个恒等映射 即等价于令残差部分趋近于0,即 。
残差单元可以以跳层连接的形式实现,即将单元的输入直接与单元输出加在一起,然后再激活。因此残差网络可以轻松地用主流的自动微分深度学习框架实现,直接使用BP算法更新参数[1]。
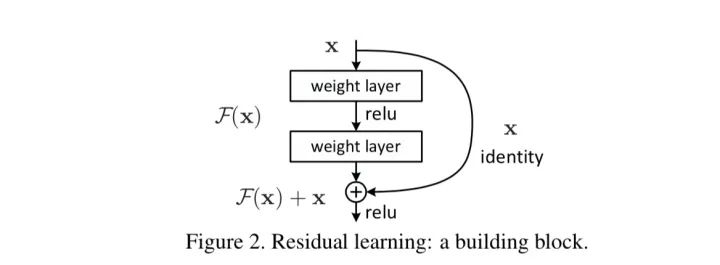
实验表明,残差网络很好地解决了深度神经网络的退化问题,并在ImageNet和CIFAR-10等图像任务上取得了非常好的结果,同等层数的前提下残差网络也收敛得更快[1]。这使得前馈神经网络可以采用更深的设计。除此之外,去除个别神经网络层,残差网络的表现不会受到显著影响[2],这与传统的前馈神经网络大相径庭。
3. 残差网络解决了什么,为什么有效?
残差网络在图像领域已然成为了一种主流模型,虽然这种网络范式的提出是为了解决网络退化问题,但是关于其作用的机制,还是多有争议。目前存在几种可能的解释,下面分别列举2016年的两篇文献和2018年的一篇文献中的内容。
3.1 从前后向信息传播的角度来看
何恺明等人从前后向信息传播的角度给出了残差网路的一种解释[3]。
考虑式 这样的残差块组成的前馈神经网络,为了讨论简便,暂且假设残差块不使用任何激活函数,即
考虑任意两个层数 ,递归地展开 ,
可以得到
根据式 ,在前向传播时,输入信号可以从任意低层直接传播到高层。由于包含了一个天然的恒等映射,一定程度上可以解决网络退化问题。
这样,最终的损失 对某低层输出的梯度可以展开为
或展开写为
根据式 ,损失对某低层输出的梯度,被分解为了两项,前一项 表明,反向传播时,错误信号可以不经过任何中间权重矩阵变换直接传播到低层,一定程度上可以缓解梯度弥散问题(即便中间层矩阵权重很小,梯度也基本不会消失)。
综上,可以认为残差连接使得信息前后向传播更加顺畅。
* 加入了激活函数的情况的讨论(实验论证)请参见[3]。
3.2 集成学习的角度
Andreas Veit等人提出了一种不同的视角[2]。他们将残差网络展开,以一个三层的ResNet为例,将得到下面的树形结构:
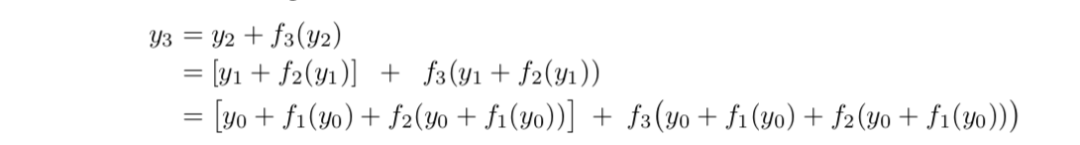
使用图来表示就是
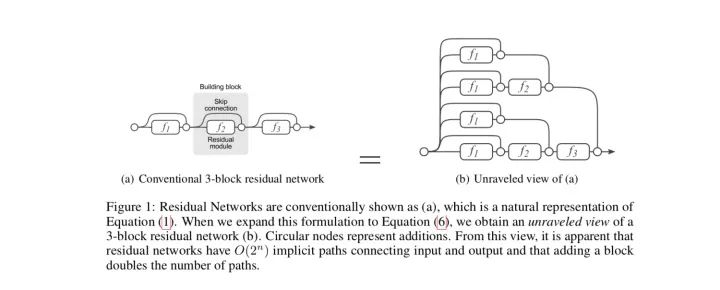
这样,残差网络就可以被看作是一系列路径集合组装而成的一个集成模型,其中不同的路径包含了不同的网络层子集。Andreas Veit等人展开了几组实验(Lesion study),在测试时,删去残差网络的部分网络层(即丢弃一部分路径)、或交换某些网络模块的顺序(改变网络的结构,丢弃一部分路径的同时引入新路径)。实验结果表明,网络的表现与正确网络路径数平滑相关(在路径变化时,网络表现没有剧烈变化),这表明残差网络展开后的路径具有一定的独立性和冗余性,使得残差网络表现得像一个集成模型(ensemble)。
作者还通过实验表明,残差网络中主要在训练中贡献了梯度的是那些相对较短的路径,从这个意味上来说,残差网络并不是通过保留整个网络深度上的梯度流动来抑制梯度弥散问题,一定程度上反驳了何恺明等[3]中的观点。但是,我觉得这个实验结果与何凯明等的结论并不矛盾,因为这些较短的梯度路径正是由残差结构引入的。
* 可以类比集成学习的网络架构方法不仅有残差网络,Dropout机制也可以被认为是隐式地训练了一个组合的模型。
3.3 梯度破碎问题
2018年的一篇论文,The Shattered Gradients Problem: If resnets are the answer, then what is the question?[4],指出了一个新的观点,尽管残差网络提出是为了解决梯度弥散和网络退化的问题,它解决的实际上是梯度破碎问题(the shattering gradient problem):
在标准前馈神经网络中,随着深度增加,梯度逐渐呈现为白噪声(white noise)。
作者通过可视化的小型实验(构建和训练一个神经网络 )发现,在浅层神经网络中,梯度呈现为棕色噪声(brown noise),深层神经网络的梯度呈现为白噪声。在标准前馈神经网络中,随着深度增加,神经元梯度的相关性(corelation)按指数级减少 ( );同时,梯度的空间结构也随着深度增加被逐渐消除。这也就是梯度破碎现象。
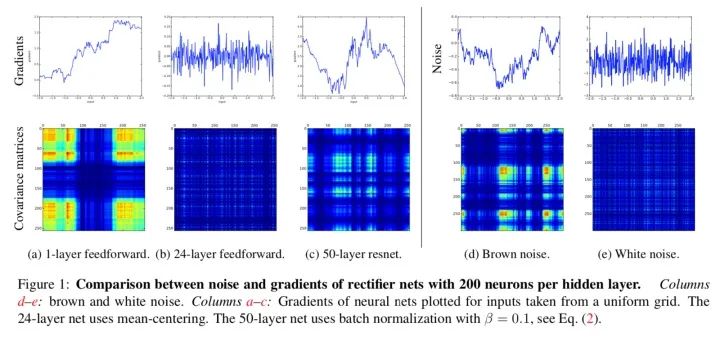
梯度破碎为什么是一个问题呢?这是因为许多优化方法假设梯度在相邻点上是相似的,破碎的梯度会大大减小这类优化方法的有效性。另外,如果梯度表现得像白噪声,那么某个神经元对网络输出的影响将会很不稳定。
相较标准前馈网络,残差网络中梯度相关性减少的速度从指数级下降到亚线性级(sublinearly, ),深度残差网络中,神经元梯度介于棕色噪声与白噪声之间(参见上图中的c,d,e);残差连接可以极大地保留梯度的空间结构。残差结构缓解了梯度破碎问题。
* 更细致的实验与讨论请参见[4]。
4. 自然语言处理中的残差结构
与图像领域不同的是,自然语言处理中的网络往往“宽而浅”,在这些网络中残差结构很难有用武之地。但是在谷歌提出了基于自注意力的Transformer架构[5],特别是BERT[6]出现以后,自然语言处理也拥有了“窄而深”的网络结构,因此当然也可以充分利用残差连接,来达到优化网络的目的。事实上,Transformer本身就包含了残差连接,其中编码器和解码器中的每一个子模块都包含了残差连接,并使用了Layer Normalization。
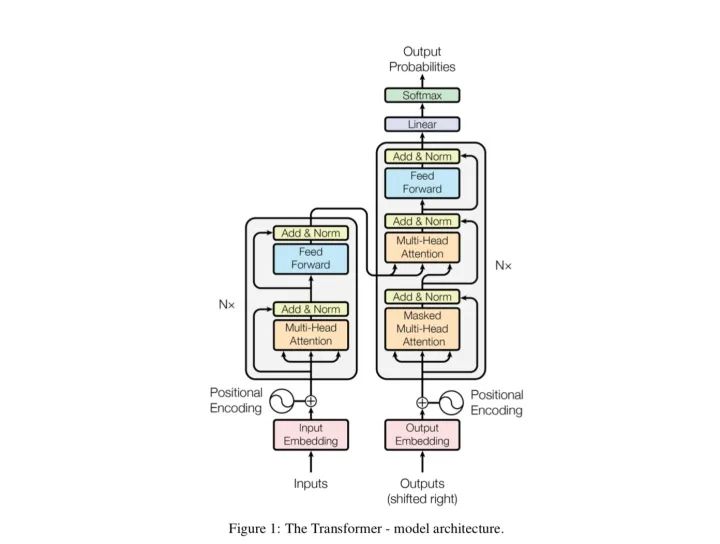
可以预见的是,基于深度学习的自然语言处理的网络结构很可能朝着更“深”的方向发展,那么残差结构就是一个几乎不可缺少的选项了。
5. 总结与扩展
残差网络真可谓是深度学习的一把利器,它的出现使得更深的网络训练成为可能。类似残差网络的结构还有Highway Network[7],与残差网络的差别在于加入了门控机制(注意它和ResNet是同时期的工作),文献[4]中也对Highway Network进行了讨论,值得一读;现在广泛使用的门控RNN,我认为与Highway Network有异曲同工之妙,可以认为是在时间维上引入了门控的残差连接;在残差网络中使用的跳层连接,在自然语言处理中也有相当多的应用,比如Bengio的神经语言模型[8]、文本匹配模型ESIM[9]等,区别在于这些工作中跳层连接仅仅将不同层次的特征拼接在一起(而不是相加),达到增加特征多样性、加快训练的目的。
P.S. 原本希望在这篇文章里面展开讲讲更多的细节,但是个人水平有限,加上知乎的文章篇幅限制,只能大概展开到这种程度。本文是笔者根据论文梳理的自己的理解,如果有谬误请指出。
参考
^abcdDeep Residual Learning for Image Recognition http://arxiv.org/abs/1512.03385 ^abResidual Networks Behave Like Ensembles of Relatively Shallow Networks http://arxiv.org/abs/1605.06431 ^abcIdentity Mappings in Deep Residual Networks https://arxiv.org/abs/1603.05027 ^abcThe Shattered Gradients Problem: If resnets are the answer, then what is the question? https://arxiv.org/abs/1702.08591 ^Attention Is All You Need https://arxiv.org/abs/1706.03762 ^BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/abs/1810.04805 ^Highway Networks https://arxiv.org/abs/1505.00387 ^A Neural Probabilistic Language Model http://www.researchgate.net/publication/2413241_A_Neural_Probabilistic_Language_Model ^Enhanced LSTM for Natural Language Inference http://arxiv.org/abs/1609.06038v3
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!
