
编程中的惰性思想


惰性思想
我想大家在学习工作中,一定或多或少有Deadline的经历吧,假期作业留到最后快开学了才写,衣服拖到最后没衣服换了才洗,这样做好不好呢?其实还行,一般Deadline期间写作业洗衣服效率挺高的,而换一个思路来说,在写作业洗衣服之前,你都是空闲的,可以尽情做别的事情的,程序设计里面,我理解的惰性思想其实跟Deadline很像,资源分配推迟到不能再推迟为止
Linux内存动态分配里的惰性思想
请求调页
术语"请求调页"指的是把页框(虚拟内存调度单位)的分配推迟到不能再推迟为止,也就是说,一直推迟到进程要访问的页不在RAM中时为止,因此引起一个缺页异常。
请求调页技术背后的动机是:进程开始运行时并不访问其地址空间中的全部地址;事实上,有一部分地址也许永远不会被进程使用。此外,程序的局部性原理保证了在程序执行的每个阶段,真正引用的进程页只有一小部分,因此临时用不着的页所在的页框可以由其他进程来使用。这样增加了系统中的空闲页框的平均数,从而更好的利用空闲内存。从另一个观点来看,在RAM总数保持不变的情况下,请求调页从总体上使系统有更大的吞吐量。
写时复制(也就是大名鼎鼎的copy on write)
第一代 Unix 系统实现了一种傻瓜式的进程创建:当 fork() 子进程时候,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。而子进程有很多东西和父进程一样且不发生修改的,没必要完全复制,这种做法既浪费很多内存空间,又消耗许多 CPU 周期。
现在的 Unix内核(包括Linux)采用一种更为有效的方法,称为写时复制,也就是大名鼎鼎的 Copy On Write。这种思想相当简单:父进程和子进程共享页框,只是不能修改,当修改的时候,就产生异常,这时内核再把这个页复制到一个新的页框中并标记为可写,原来的页框仍然是写保护的。当其他进程试图写入时,内核检查写进程是否是这个页框的唯一属主,如果是,就把这个页框标记为对这个进程可写。
其中,页描述符的 _count 字段用于跟踪共享当前页框的进程数目,为1时说明跟其他1个进程共享,为0时说明只有一个进程可写,为-1时说明需要被释放。
举例子
JS语言反面教材
必然很了解JS的深浅拷贝问题,问烂了的面试题了
let a = {a:1};let b = a;let c = Object.assign({}, a)console.log(a,b,c,a===b,a===c);//{a:1} {a:1} {a:1} true falsea.a = 2;console.log(a,b,c,a===b,a===c);//{a:2} {a:2} {a:1} true false
上面的代码很好理解,b是浅拷贝,故而值跟着变了,c是深拷贝,故而值没变 而对应的变量内存地址的话,因为JS并不能像其他语言一样,显式的查看变量内存地址,但可以借助Chrome的Memory工具快照,来查看其相应的V8虚拟地址。
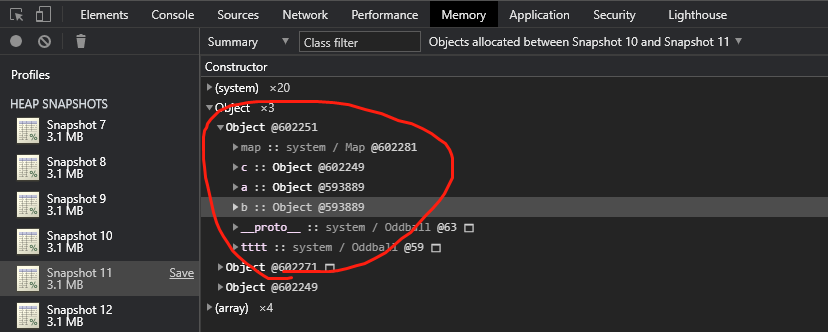
明显的,a和b有着相同的内存地址,而c因为是深拷贝,拥有新的内存地址;当我们给a.a = 2重新写入后,观察Snapshot 12,a和b的内存地址依然相同,这是因为JS这门语言并没有实现写时复制。
python写时复制
讲完JS反面教材,我们再来观察一个实现了写时复制的语言。
terence@k8s-master:/mydata$ python3Python 3.6.9 (default, Oct 8 2020, 12:12:24)[GCC 8.4.0] on linuxType "help", "copyright", "credits" or "license" for more information.a = "qwer"print(a)qwerid(a)140662197387536b = a;print(b)qwerid(b)140662197387536//跟a的内存地址一致b = "qwert"id(b)140662197387592//写时复制,内存地址发生了变化>>>
PHP写时复制
PHP对数组实现了写时复制,普通变量是没有写时复制的,通过下面的例子能够清楚的看到内存占用量的变化,只是修改了$b[0],然后整个都被复制了。(当然也可以安装xdebug拓展,进一步可以观察到数组refcount引用计数的变化)
$a = [];for ($i=0; $i < 10000; $i++) {$a[] = rand(0,10000);}var_dump(memory_get_usage());//9438664$b = $a;var_dump(memory_get_usage());//9438664$b[0] = 99999;var_dump(memory_get_usage());//9967104
Rust写时复制
fn main() {let s1 = String::from("hello");println!("s1 heap address: {:p}", s1.as_ptr());//0x5645e759d9e0println!("s1 stack address: {:p}", &s1);//0x7fff6a964bb8let mut s2 = s1;println!("s2 heap address: {:p}", s2.as_ptr());//0x5645e759d9e0println!("s2 stack address: {:p}", &s2);//0x7fff6a964c70b = String::from("world");println!("s2 heap address: {:p}", s2.as_ptr());//0x5645e759da70println!("s2 stack address: {:p}", &s2);//0x7fff6a964c70}
对于Rust这种系统级语言,我们能更直观的观察到进程栈中的局部变量是如何跟堆中的实际内存地址关联起来的。
以了解 String 的底层会发生什么。String 由三部分组成,如下图左侧所示:一个指向存放字符串内容内存的指针,一个长度,和一个容量。这一组数据存储在栈上。右侧则是堆上存放内容的内存部分。
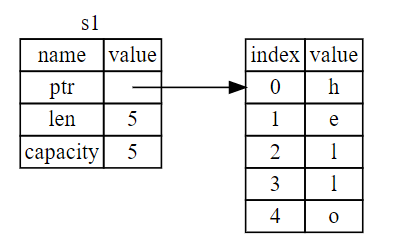
长度表示 String 的内容当前使用了多少字节的内存。容量是 String 从操作系统总共获取了多少字节的内存。长度与容量的区别是很重要的,不过在当前上下文中并不重要,所以现在可以忽略容量。
当我们将 s1 赋值给 s2,String 的数据被复制了,这意味着我们从栈上拷贝了它的指针、长度和容量。我们并没有复制指针指向的堆上数据。换句话说,内存中数据的表现如下图
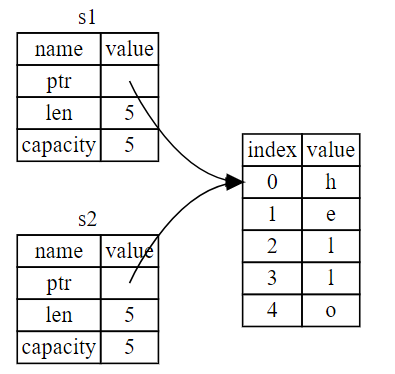
当我们修改s2时,写时复制,变成了如下所示
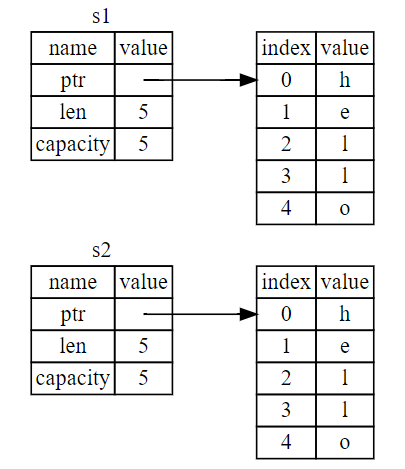
其他例子
前端开发场景里有懒加载,节流防抖,其实都是惰性思想的体现,不到万不得已,不去分配资源。
「❤️ 感谢大家」
如果你觉得这篇内容对你挺有有帮助的话:
- 点赞支持下吧,让更多的人也能看到这篇内容(收藏不点赞,都是耍流氓 -_-)
- 欢迎在留言区与我分享你的想法,也欢迎你在留言区记录你的思考过程。
- 觉得不错的话,也可以阅读近期梳理的文章(感谢鼓励与支持🌹🌹🌹):
- 教你用python实现抖音上的头像特效合成
- 小程序云开发资源的管理
- 教你用python进行数字化妆,可爱至极
- 加速Python列表和字典,让你代码更加高效
- 汇总超全的Matplotlib可视化最有价值的 50 个图表(附完整 Python 源代码)(三)
- 汇总超全的Matplotlib可视化最有价值的 50 个图表(附完整 Python 源代码)(二)
- 汇总超全的Matplotlib可视化最有价值的 50 个图表(附完整 Python 源代码)(一)
- 教你用Python制作实现自定义字符大小的简易小说阅读器
老铁,三连支持一下,好吗?↓↓↓



点分享

点点赞

点在