
图数据库系统重构之路:从OrientDB迁移到NebulaGraph 真实案例分享
一、写在前面
读过我公众号文章的同学都知道,我做过很多次重构,可以说是“重构钉子户”,但是这次,重构图数据库OrientDB为Nebula Graph(https://www.nebula-graph.io/),可以说是我做过最艰难的一次重构,那这篇文章就来聊聊,图数据库重构之路。
二、难点在哪里
1、历史包袱重,原来使用OrientDB系统是2016年开始开发的,逻辑很复杂,历史背景完全不清楚。
2、业务不了解,我们是临时接的大数据需求,之前没有参与过这块业务,完全不了解。
3、技术栈不了解,图数据库是第一次接触(团队中也没有人了解),OrientDB和Nebula之前都没有接触过,原来老系统大部分代码是Scala语言写的,系统中使用的Hbase,Spark,Kafka对于我们也比较陌生。
4、时间紧迫
总结来说: 业务不了解,技术栈不熟悉!
tips: 大家思考一个问题,在业务和技术栈都不熟的情况下,如何做重构呢?
三、技术方案
下面介绍一下本次重构技术方案
1、背景
猎户座的图数据库OrientDB存在性能瓶颈和单点问题,需升级为Nebula。
老系统使用技术栈无法支持弹性伸缩,监控报警设施也不够完善。
2、调研事项
注: 既然业务都不熟悉,那我们都调研了哪些东西呢?
1)、对外接口梳理: 梳理系统所有对外接口,包括接口名,接口用途,请求量(QPS),平均耗时,调用方(服务和IP)
2)、老系统核心流程梳理: 输出老系统整理架构图,重要的接口(大概10个)输出流程图
3)、环境梳理: 涉及到的需要改造的项目有哪些 , 应用部署、Mysql,Redis,Hbase集群IP,及目前线上部署分支整理
4)、触发场景: 接口都是如何触发的,从业务使用场景出发,每个接口至少一个场景覆盖到,方便后期功能验证
5)、改造方案: 可行性分析,针对每一个接口,如何改造(OrientDB语句改为Nebula查询语句),入图(写流程)如何改造
6)、新系统设计方案: 输出整理架构图,核心流程图
3、项目目标
完成图数据库数据源 OrientDB改造为Nebula,重构老系统统一技术栈为Java,支持服务水平扩展。
4、整体方案
我们采用了比较激进的方案:
1、从调用接口入口出发,直接重写底层老系统,影响面可控
2、一劳永逸,方便后期维护
3、统一Java技术栈、接入公司统一服务框架,更利于监控及维护
4、基础图数据库应用边界清晰,后续上层应用接入图数据库更简单
注:这里就贴调研阶段画的图,图涉及业务,我这里就不列举了。
5、灰度方案
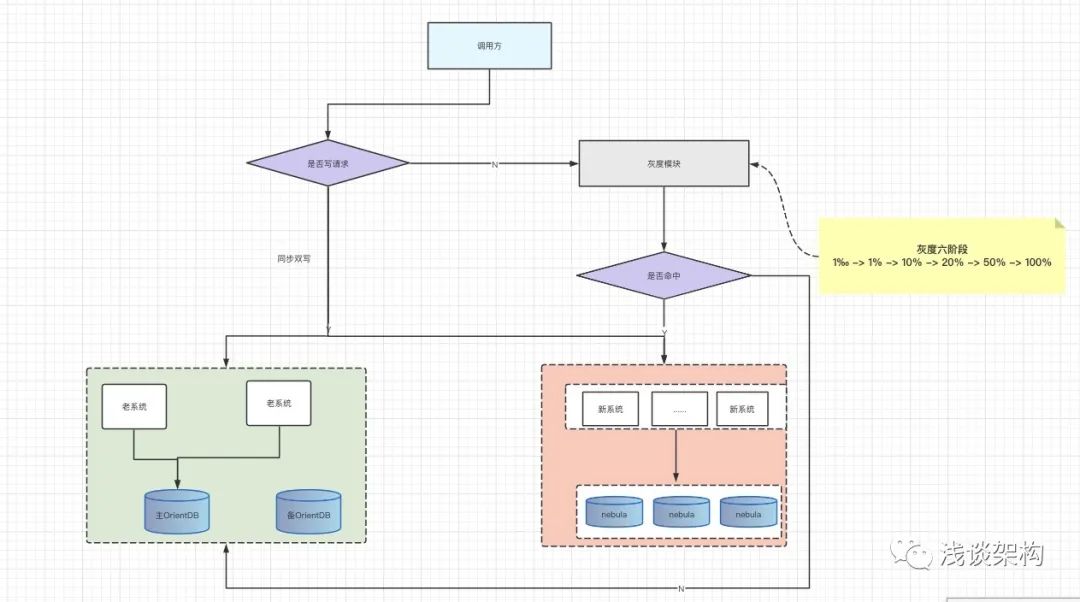
** 1) 灰度方案**
写请求:采用同步双写
读请求:按流量从小到大陆续迁移、平滑过渡
** 2) 灰度计划**
| 阶段一 | 阶段二 | 阶段三 | 阶段四 | 阶段五 | 阶段六 | 阶段七 |
| 0% | 1‰ | 1% | 10% | 20% | 50% | 100% |
| 同步双写, 流量回放采样对比,100%通过、预计灰度2天 | 灰度2天 | 灰度2天 | 灰度5天、此阶段要压测 | 灰度2天 | 灰度2天 | - |
注:
-
1. 配置中心开关控制,有问题随时切换,秒级恢复。
-
2. 读接口遗漏无影响, 只有改到的才会影响。
-
3. 使用参数 hash值作为key,确保同一参数多次请求结果一致、满足 abs(key) % 1000 < X ( 0< X < 1000, X为动态配置 ) 即为命中灰度。
题外话: 其实重构,最重要的就是灰度方案,这个我在之前文章也提到过,本次灰度方案设计比较完善,大家重点看阶段一、在灰度放量之前,我们用线上真实的流量去异步做数据对比,对比完全通过之后,再放量,本次数据对比阶段比预期长了一些(实际上用了2周时间,发现了很多隐藏问题)。
6、数据对比方案
1) 未命中灰度流程如下:
先调用老系统,再根据是否命中采样(采样比例配置 0% ~ 100% ),命中采样会发送MQ,再在新系统消费MQ,请求新系统接口,于老系统接口返回数据进行json对比,对比不一致发送企业微信通知,实时感知数据不一致,发现并解决问题。
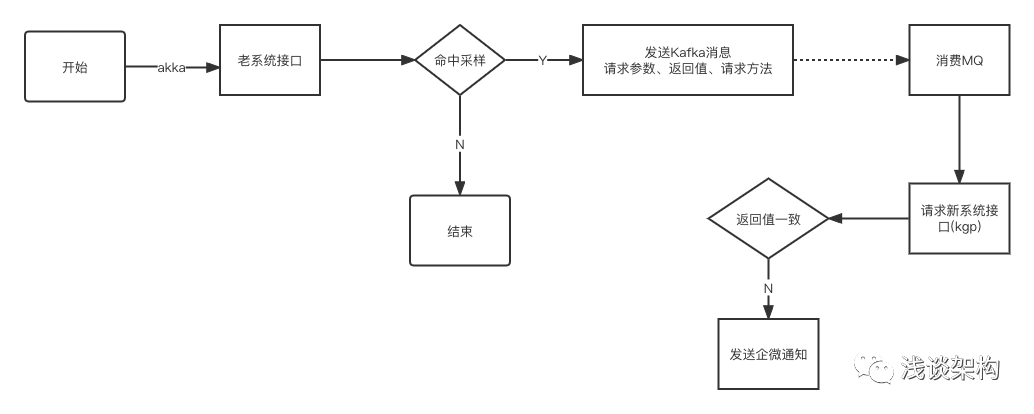 img
img反之亦然!!
7、数据迁移方案
1)、 全量(历史数据):脚本全量迁移,上线期间产生不一致从MQ消费近3天数据
2)、增量:同步双写(写的接口很少,写请求QPS不高)
8、改造案例 - 以子图查询为例
1)改造前
@Override
public MSubGraphReceive getSubGraph(MSubGraphSend subGraphSend) {
logger.info("-----start getSubGraph------(" + subGraphSend.toString() + ")");
MSubGraphReceive r = (MSubGraphReceive) akkaClient.sendMessage(subGraphSend, 30);
logger.info("-----end getSubGraph:");
return r;
}
2)改造后
定义灰度模块接口
public interface IGrayService {
/**
* 是否命中灰度 配置值 0 ~ 1000 true: 命中 false:未命中
*
* @param hashCode
* @return
*/
public boolean hit(Integer hashCode);
/**
* 是否取样 配置值 0 ~ 100
*
* @return
*/
public boolean hitSample();
/**
* 发送请求-响应数据
* @param requestDTO
*/
public void sendReqMsg(MessageRequestDTO requestDTO);
/**
* 根据
* @param methodKeyEnum
* @return
*/
public boolean hitSample(MethodKeyEnum methodKeyEnum);
}
接口改造如下, newCoreService请求到new-core新服务,接口业务逻辑和老系统接口保持一致、底层图数据库改为查询Nebula
@Override
public MSubGraphReceive getSubGraph(MSubGraphSend subGraphSend) {
logger.info("-----start getSubGraph------(" + subGraphSend.toString() + ")");
long start = System.currentTimeMillis();
//1. 请求灰度
boolean hit = grayService.hit(HashUtils.getHashCode(subGraphSend));
MSubGraphReceive r;
if (hit) {
//2、命中灰度 走新流程
r = newCoreService.getSubGraph(subGraphSend); // 使用Dubbo调用新服务
} else {
//这里是原来的流程 使用的akka通信
r = (MSubGraphReceive) akkaClient.sendMessage(subGraphSend, 30);
}
long requestTime = System.currentTimeMillis() - start;
//3.采样命中了发送数据对比MQ
if (grayService.hitSample(MethodKeyEnum.getSubGraph_subGraphSend)) {
MessageRequestDTO requestDTO = new MessageRequestDTO.Builder()
.req(JSON.toJSONString(subGraphSend))
.res(JSON.toJSONString(r))
.requestTime(requestTime)
.methodKey(MethodKeyEnum.getSubGraph_subGraphSend)
.isGray(hit).build();
grayService.sendReqMsg(requestDTO);
}
logger.info("-----end getSubGraph: {} ms", requestTime);
return r;
}
9、项目排期计划
投入人力: 开发4人,测试1人
主要事项及耗时如下:
| 方案设计阶段 | 开发阶段 | 测试阶段 | 灰度阶段 |
| 1、流程梳理 2、画流程图、整理架构图 3、方案设计 | 1、新服务项目搭建,Nebula操作类ORM框架封装 2、接口改造(10多个接口改造) 3、MQ消费改造 4、数据对比工具开发(含企微通知) 5、数据迁移脚本开发 6、接口联调 7、代码组内CR | 1、功能测试 2、数据对比 3、100%流量老系统回归测试 4、100%流量新系统回归测试 5、生产数据迁移 | 1、分7个阶段灰度,平滑过渡 2、生产数据实时对比 3、监控&报警设施完善(这个在压测之前完成,方案压测的时候观测指标) 4、压测(10%流量压测) 5、数据备份与恢复演练(采用nebula快照备份)、扩容演练 |
| 耗时1周 | 耗时3周 | 耗时2周 | |
10、所需资源
3台Nebula机器 ,配置: 8核64G,2T SSD硬盘
6台docker服务,配置: 2核4G
四、重构收益
经过团队2个月奋斗,目前已完成灰度阶段,收益如下
1、Nebula本身支持分布式扩展,新系统服务支持弹性伸缩,整体支持性能水平扩展
2、从压测结果看,接口性能提升很明显,可支撑请求远超预期
3、接入公司统一监控、告警,更利于后期维护
五、总结
本次重构顺利完成,感谢本次一起重构的小伙伴,以及大数据、风控同学支持,同时也感谢Nebula社区(https://discuss.nebula-graph.com.cn/) ,我们遇到一些问题提问,也很快帮忙解答。
欢迎关注微信公众号“浅谈架构”,不定期分享原创技术文章。
