
LVS系列教程06-内容请求分发
目录
前言
前面我们讲述了在Linux虚拟服务器的框架下,先在Linux内核中实现了含有三种 IP 负载均衡技术的IP 虚拟服务器,可将一组服务器构成一个实现高可伸缩、高可用的网络服务的服务器集群。在IPVS中,使得服务器集群的结构对客户是透明的,客户访问集群提供的网络服务就像访问一台高性能、高可用的服务器一样。客户程序不受服务器集群的影响不需作任何修改。系统的伸缩性通过在服务机群中透明地加入和删除一个节点来达到,通过检测节点或服务进程故障和正确地重置系统达到高可用性。
IPVS基本上是一种高效的Layer-4交换机,它提供负载平衡的功能。当一个TCP连接的初始SYN报文到达时,IPVS就选择一台服务器,将报文转发给它。此后通过查发报文的IP和TCP报文头地址,保证此连接的后继报文被转发到相同的服务器。这样,IPVS无法检查到请求的内容再选择服务器,这就要求后端的服务器组是提供相同的服务,不管请求被送到哪一台服务器,返回结果都应该是一样的。但是在有一些应用中后端的服务器可能功能不一,有的是提供HTML文档的Web服务器,有的是提供图片的Web服务器,有的是提供CGI的Web服务器。这时,就需要基于内容请求分发,同时基于内容请求分发可以提高后端服务器上访问的局部性。
一、基于内容的请求分发
根据应用层(Layer-7)的信息调度TCP负载不是很容易实现,对于所有的TCP服务,应用层信息必须等到TCP连接建立(三次握手)后才能获得。这就说明连接不能用Layer-4交换机收到一个SYN报文时进行调度。来自客户的TCP连接必须在交换机上被接受,建立在客户与交换机之间TCP连接,来获得应用的请求信息。一旦获得请求信息,分析其内容来决定哪一个后端服务器来处理,再将请求调度到该服务器。
1.1 实现内容调度的方法
现有两种方法实现基于内容的调度。一种是TCP 网关(TCP Gateway),交换机建立一个到后端服务器的TCP连接,将客户请求通过这个连接发到服务器,服务器将响应结果通过该连接返回到交换机,交换机再将结果通过客户到交换机的连接返回给客户。另一种是TCP 迁移(TCP Migration),将客户到交换机TCP连接的交换机端迁移到服务器,这样客户与服务器就可以建立直接的 TCP 连接,但请求报文还需要经过交换机调度到服务器,响应报文直接返回给客户。
就我们所知,Resonate实现了TCP迁移方法,他们称之为TCP 连接跳动(TCP Connection Hop),他们的软件是专有的。TCP迁移需要修改交换机的TCP/IP协议栈,同时需要修改所有后端服务器的TCP/IP协议栈,才能实现将TCP连接的一端从一台机器及其迁移到另一台上。虽然在交换机获得客户请求后,TCP迁移方法比较高效,但是该方法实现工作量大,要修改交换机和后端服务器的操作系统,不具有一般性。
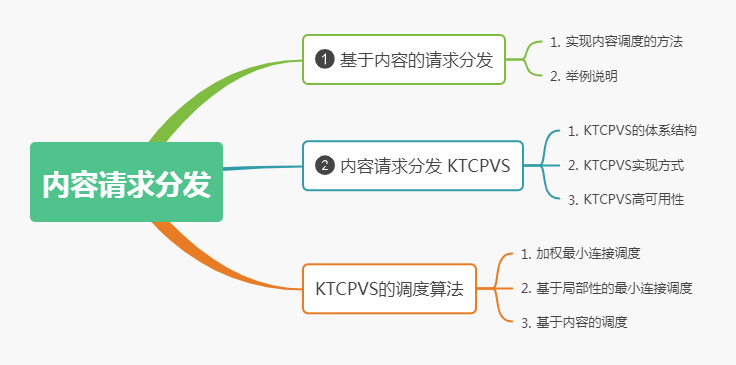
因此,TCP 网关方法被绝大部分Layer-7交换的商业产品和自由软件所使用,如ArrowPoint的CS-100和CS-800的Web交换机、Zeus负载调度器、爱立信实验室的EDDIE、自由软件Apache和Squid等。TCP网关方法不需要更改服务器的操作系统,服务器只要支持TCP/IP即可,它具有很好的通用性。但是,TCP网关一般都是在用户空间实现的,其处理开销比较大,如下图所示。
从图中我们可以看出,对于任一TCP请求,客户将请求发到交换机,计算机将请求报文从内核传给用户空间的Layer-7交换程序,Layer-7交换程序根据请求选出服务器,再建一个TCP连接将请求发给服务器,返回的响应报文必须先由内核传给用户空间的Layer-7交换程序,再由Layer-7交换程序通过内核将结果返回给客户。对于一个请求报文和对应的响应报文,都需要四次内核与用户空间的切换,切换和内存复制的开销是非常高的,所以用户空间TCP Gateway的伸缩能力很有限,一般来说一个用户空间TCP Gateway只能调度三、四台服务器,当连接的速率到达每秒1000个连接时,TCP Gateway本身会成为瓶颈。所以,在ArrowPoint的CS-800的Web交换机中集成了多个TCP Gateway。
1.2 举例说明
虽然Layer-7交换比Layer-4交换处理复杂,但Layer-7交换带来以下好处:
相同页面的请求被发送到同一台的服务器,所请求的页面很有可能会被服务器缓存,可以提高单台服务器的主存Cache使用效率。
一些研究表明WEB访问流中存在空间的局部性。Layer-7交换可以充分利用访问的局部性,将相同类型的请求发送到同一台服务器,使得每个后端服务器收到的请求相似性好,有利于进一步提高单台服务器的主存Cache使用效率,从而在有限的硬件配置下提高系统的整体性能。
后端的服务器可运行不同类型的服务,如文档服务,图片服务,CGI服务和数据库服务等。
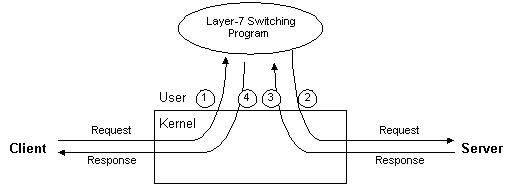
上图举例说明了基于内容请求分发可以提高后端服务器的Cache命中率。在例子中,一个有两台后端服务器的集群来处理进来的请求序列AACBAACABC。在基于内容的请求分发中,调度器将所有请求A发到后端服务器1,将请求B和C序列发到后端服务器2。这样,有很大的可能性请求所要的对象会在后端服务器的Cache中找到。相反在轮叫请求分发中,后端服务器都收到请求A、B和C,这增加了Cache不命中的可能性。因为分散的请求序列会增大工作集,当工作集的大小大于后端服务器的主存Cache时,导致Cache不命中。
在基于内容的请求分发中,不同的请求被发送到不同的服务器,当然这有可能导致后端服务器的负载不平衡,也有可能导致更差的性能。所以,在设计基于内容请求分发的服务器集群中,我们不仅要考虑如何高效地进行基于内容的请求分发,而且要设计有效的算法来保证后端服务器间的负载平衡和提高单个服务器的Cache命中率。
二、内容请求分发 KTCPVS
内核中的基于内容请求分发
KTCPVS集群
由于用户空间TCP Gateway的开销太大,导致其伸缩能力有限。为此,我们提出在操作系统的内核中实现Layer-7交换方法,来避免用户空间与核心空间的切换开销和内存复制的开销。在Linux操作系统的内核中,我们实现了Layer-7交换,称之为KTCPVS(Kernel TCP Virtual Server)。
2.1 KTCPVS 的体系结构
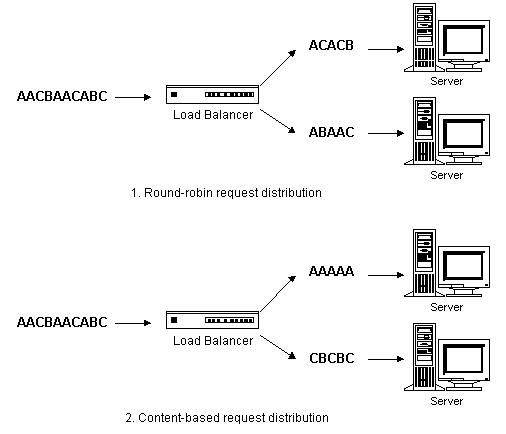
KTCPVS 集群的体系结构如下图所示:它主要由两个组成部分,一是KTCPVS 交换机,根据内容不同将请求发送到不同的服务器上;二是后端服务器,可运行不同的网络服务。KTCPVS交换机和后端服务器通过LAN/WAN互联。
KTCPVS交换机能进行根据内容的调度,将不同类型的请求发送到不同的后端服务器,再将结果返回给客户,后端服务器对客户是不可见的。所以,KTCPVS集群的结构对客户是透明的,客户访问集群提供的网络服务就像访问一台高性能、高可用的服务器一样,故我们也称之为虚拟服务器。客户程序不受服务器集群的影响不需作任何修改。
2.2 KTCPVS 实现方式
在Linux内核2.4中,我们用内核线程(Kernel thread)实现Layer-7交换服务程序,并把所有的程序封装在可装卸的KTCPVS模块。KTCPVS的主要功能模块如下图所示:当KTCPVS模块被加载到内核中时,KTCPVS主内核线程被激活,并在/proc文件系统和setsockopt上挂接KTCPVS的内核控制程序,用户空间的管理程序tcpvsadm通过setsockopt函数来设置KTCPVS服务器的规则,通过/proc文件系统把KTCPVS服务器的规则读出。基于内容调度的模块被做成可装卸的模块(Loadable Module),不同的网络服务可以使用不同的基于内容调度模块,如HTTP和RTSP等。另外,系统的结构灵活,用户也可以为自己不同类型的网络服务编写相应的模块。
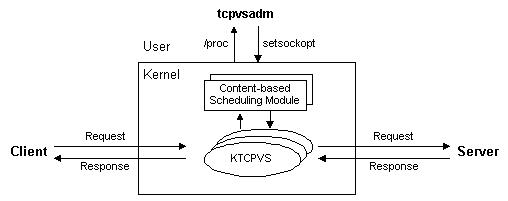
可以通过tcpvsadm命令使得KTCPVS主线程生成多个子线程监听在某个端口。这组子线程可以接受来自客户的请求,通过与其绑定的基于内容的调度模块获得能处理当前请求的服务器,并建立一个TCP连接到该服务器,将请求发到服务器;子线程获得来自服务器的响应结果后,再将结果返回给客户。所有的请求和响应数据处理都是在操作系统的内核中进行的,所以没有用户空间与核心空间的切换开销和内存复制的开销,其处理开销比用户空间的TCP Gateway小很多。
2.3 KTCPVS 高可用性
KTCPVS集群系统的高可用性可分为二部分达到,一是服务器故障处理,二是KTCPVS 调度器故障处理。
在服务器故障处理上,我们可以一种或者组合多种方法来检测服务器或者网络服务是否可用。例如,一是资源监测器每隔 t 个毫秒对每个服务器发ARP(Address Resolve Protocol)请求,若有服务器过了r毫秒没有响应,则说明该服务器已发生故障,资源监测器通知调度器将该服务器的所有服务进程调度从调度列表中删除。二是资源监测器定时地向每个服务进程发请求,若不能返回结果则说明该服务进程发生故障,资源监测器通知调度器将该服务进程调度从KTCPVS调度列表中删除。资源监测器能通过电子邮件或传呼机向管理员报告故障,一旦监测到服务进程恢复工作,通知调度器将其加入调度列表进行调度。通过检测节点或服务进程故障和正确地重置系统,可以将部分节点或软件故障对用户屏蔽掉,从而实现系统的高可用性。
在KTCPVS调度器故障处理上,跟IPVS调度器故障处理类似,通过心跳或者VRRP来实现KTCPVS调度器的高可用性。
三、KTCPVS 的调度算法
KTCPVS的负载均衡调度是以TCP连接为粒度的。同一用户的不同连接可能会被调度到不同的服务器上,所以这种细粒度的调度可避免不同用户的访问差异引起服务器间的负载不平衡。
在调度算法上,我们先实现了加权最小连接调度,因为该算法都较容易实现,便于调试和测试。另外,KTCPVS交换机网络配置比Layer-4交换机的简单,KTCPVS交换机和服务器只要有网络相连,能进行TCP/IP通讯即可,安装使用比较方便,所以在整个系统规模不大(例如不超过 10 个结点)且结点提供的服务相同时,可以利用以上算法来调度这些服务器,KTCPVS交换机仍是不错的选择。同时,在实际的性能测试中,这些调度算法可以用作比较。
我们给出基于局部性的最小连接调度和基于内容的调度算法。基于局部性的最小连接调度是假设后端服务器都是相同的,在后端服务器的负载基本平衡情况下,尽可能将相同的请求分到同一台服务器,以提高后端服务器的访问局部性,从而提高后端服务器的Cache命中率。基于内容的调度是考虑后端服务器不相同时,若同一类型的请求有多个服务器可以选择时,将请求负载均衡地调度到这些服务器上。
3.1 加权最小连接调度
最小连接调度(Least-Connection Scheduling)是把新的连接请求分配到当前连接数最小的服务器。最小连接调度是一种动态调度算法,它通过服务器当前所活跃的连接数来估计服务器的负载情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加 1;当连接中止或超时,其连接数减一。
加权最小连接调度(Weighted Least-Connection Scheduling)是最小连接调度的超集,各个服务器用相应的权值表示其处理性能。服务器的缺省权值为1,系统管理员可以动态地设置服务器的权值。加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。
3.2 基于局部性的最小连接调度
在基于局部性的最小连接负载调度中,我们假设任何后端服务器都可以处理任一请求。算法的目标是在后端服务器的负载平衡情况下,提高后端服务器的访问局部性,从而提高后端服务器的主存Cache命中率。
在WEB应用中,来自不同用户的请求很有可能重叠,WEB访问流中存在空间的局部性,容易获得WEB请求的URL,所以,LBLC算法主要针对WEB应用。静态WEB页面的请求格式如下:
<scheme>://<host>:<port>/<path>
其中,区分页面不同的变量是文件的路径
<scheme>://<host>:<port>/<path>?<query>
我们将其中的CGI文件路径
while (true) {
get next request r;
r.target = { extract path from static/dynamic request r };
if (server[r.target] == NULL) then {
n = { least connection node };
server[r.target] = n;
} else {
n = server[r.target];
if (n.conns > n.high && a node with node.conns < node.low) ||
n.conns >= 2*n.high then {
n = { least connection node };
server[r.target] = n;
}
}
if (r is dynamic request) then
n.conns = n.conns + 2;
else
n.conns = n.conns + 1;
send r to n and return results to the client;
if (r is dynamic request) then
n.conns = n.conns - 2;
else
n.conns = n.conns - 1;
}
在算法中,我们用后端服务器的活跃连接数(n.conns)来表示它的负载,server是个关联变量,它将访问的目标和服务器对应起来。在这里,假设动态页面的处理是静态页面的2倍。开销算法的意图是将请求序列进行分割,相同的请求去同一服务器,可以提高访问的局部性;除非出现严重的负载不平衡了,我们进行调整,重新分配该请求的服务器。我们不想因为微小或者临时的负载不平衡,进行重新分配服务器,会导致Cache不命中和磁盘访问。所以,“严重的负载不平衡”是为了避免有些服务器空闲着而有服务器超载了。
我们定义每个结点有连接数目的高低阀值,当结点的连接数(node.conns)小于其连接数低阀值(node.low)时,表明该结点有空闲资源;当结点的连接数(node.conns)大于其连接数高阀值(node.high)时,表明该结点在处理请求时可能会有一定的延时。在调度中,当一个结点的连接数大于其高阀值并且有结点的连接数小于其低阀值时,重新分配,将请求发到负载较轻的结点上。还有,为了限制结点过长的响应延时,当结点的连接数大于 2 倍的高阀值时,将请求重新分配到负载较轻的结点,不管是否有结点的连接数小于它的低阀值。
我们在调度器上进行限制后端服务器的正在处理连接数必须小于∑node.high,这样可以避免所有结点的连接数大于它们的 2 倍的高阀值。这样,可以保证当有结点的连接数大于2倍的高阀值时,必有结点的连接数小于其高阀值。
正确选择结点的高低阀值是根结点的处理性能相关的。在实践中,结点的低阀值应尽可能高来避免空闲资源,否则会造成结点的低吞吐率;结点的高阀值应该一个较高的值并且结点的响应延时不大。选择结点的高低阀值是一个折衷平衡的过程,结点的高低阀值之差有一定空间,这样可以限制负载不平衡和短期负载不平衡,而不破坏访问的局部性。对于一般结点,我们选择高低阀值分别为30和60;对于性能很高的结点,可以将其阀值相应调高。
在基本的LBLC算法中,在任何时刻,任一请求目标只能由一个结点来服务。然而,有可能一个请求目标会导致一个后端服务器进入超载状态,这样比较理想的方法就是由多个服务器来服务这个文档,将请求负载均衡地分发到这些服务器上。这样,我们设计了带复制的LBLC算法,其流程如下:
while (true) {
get next request r;
r.target = { extract path from static/dynamic request r };
if (serverSet[r.target] == ∮) then {
n = { least connection node };
add n to serverSet[r.target];
} else {
n = {least connection node in serverSet[r.target]};
if (n.conns > n.high && a node with node.conns < node.low) ||
n.conns >= 2*n.high then {
n = { least connection node };
add n to serverSet[r.target];
}
if |serverSet[r.target]| > 1
&& time()-serverSet[r.target].lastMod > K then {
m = {most connection node in serverSet[r.target]};
remove m from serverSet[r.target];
}
}
if (r is dynamic request) then
n.conns = n.conns + 2;
else
n.conns = n.conns + 1;
send r to n and return results to the client;
if (r is dynamic request) then
n.conns = n.conns - 2;
else
n.conns = n.conns - 1;
if (serverSet[r.target] changed) then
serverSet[r.target].lastMod = time();
}
这个算法与原来算法的差别是调度器维护请求目标到一个能服务该目标的结点集合。请求会被分发到其目标的结点集中负载最轻的一个,调度器会检查是否发生结点集中存在负载不平衡,若是,则挑选所有结点中负载最轻的一个,将它加入该目标的结点集中,让它来服务该请求。另一方面,当请求目标的结点集有多个服务器,并且上次结点集的修改时间之差大于K秒时,将最忙的一个结点从该目标的结点集中删除。在实验中,K的缺省值为60秒。
3.3 基于内容的调度
在基于内容的调度(Content-based Scheduling)中,不同类型的请求会被送到不同的服务器,但是同一类型的请求有多个服务器可以选择,例如,CGI 应用往往是 CPU 密集型的,需要多台 CGI 服务器去完成,这时需要将请求负载均衡地调度到这些服务器上。其基本算法如下:
while (true) {
get next request r;
extract path from static/dynamic request and set r.target;
if (definedServerSet[r.target] ==∮) then
n = {least connection node in defaultServerSet};
else
n = {least connection node in definedServerSet[r.target]};
send r to n and return results to the client;
}
当请求目标有定义的结点集,即该类型的请求有一些服务器能处理,从该结点集中挑选负载最轻的一个,把当前的请求发到该服务器。当请求目标没有定义好的结点集,则从缺省的结点集中选负载最轻的结点,由它来处理该请求。
在上面的算法中,只考虑了结点间的负载平衡和结点上静态分割好的局部性,没有考虑动态访问时的局部性。我们对该算法改进如下:
while (true) {
get next request r;
r.target = { extract path from static/dynamic request r };
if (definedServerSet[r.target] ==∮) then
staticServerSet = defaultServerSet;
else
staticServerSet = definedServerSet[r.target];
if (serverSet[r.target] == ∮) then {
n = { least connection node in statisServerSet};
add n to serverSet[r.target];
} else {
n = {least connection node in serverSet[r.target]};
if (n.conns > n.high && a node in staticServerSet with
node.conns = 2*n.high then {
n = { least connection node in staticServerSet};
add n to serverSet[r.target];
}
if |serverSet[r.target]| >1
&& time()-serverSet[r.target].lastMod > K then {
m = {most connection node in serverSet[r.target]};
remove m from serverSet[r.target];
}
}
if (r is dynamic request) then
n.conns = n.conns + 2;
else
n.conns = n.conns + 1;
send r to n and return results to the client;
if (r is dynamic request) then
n.conns = n.conns - 2;
else
n.conns = n.conns - 1;
if serverSet[r.target] changed then
serverSet[r.target].lastMod = time();
}
文章作者: Escape
链接: https://escapelife.github.io/posts/6ae72895.html
往期推荐
关注「开源Linux」加星标,提升IT技能
