省去90%服务器还能提升反欺诈效率?看PayPal打破“AI内存墙”实战

作者 | 张倩
内存不够只能割肉买 DRAM?英特尔:很多时候大可不必。
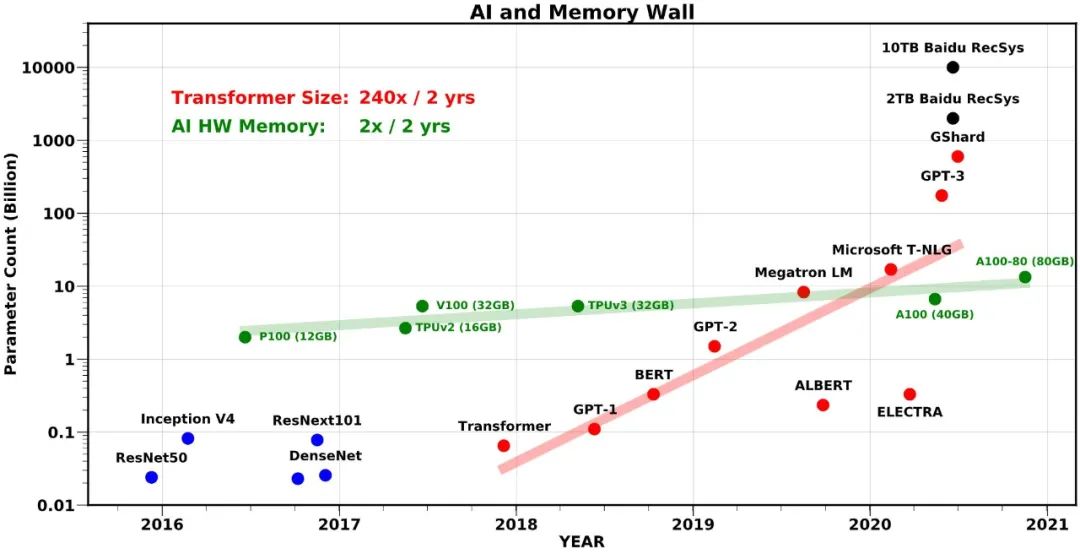
工业界的推理拦路虎:内存墙
打破推理内存墙,不用 DRAM 用什么?
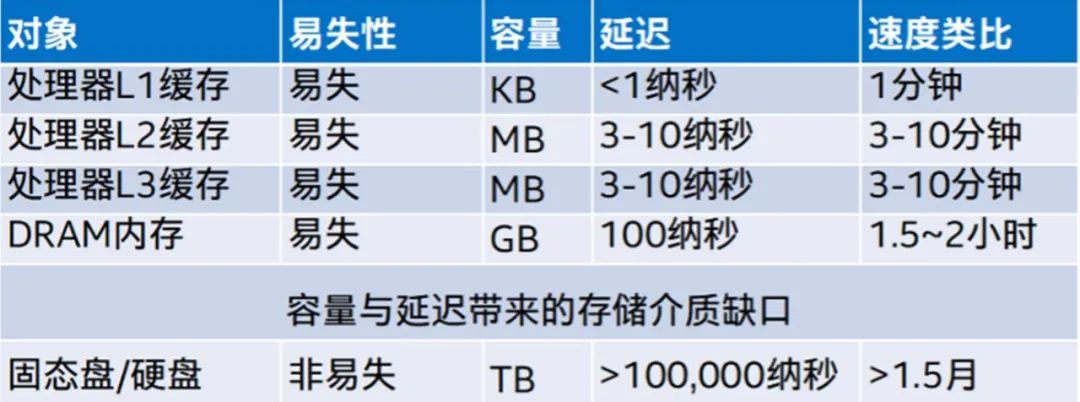
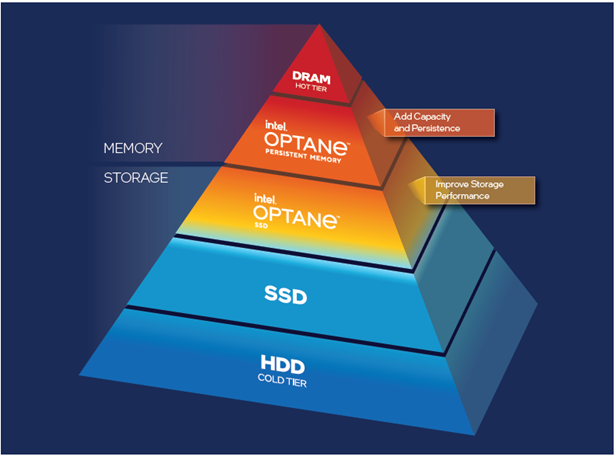
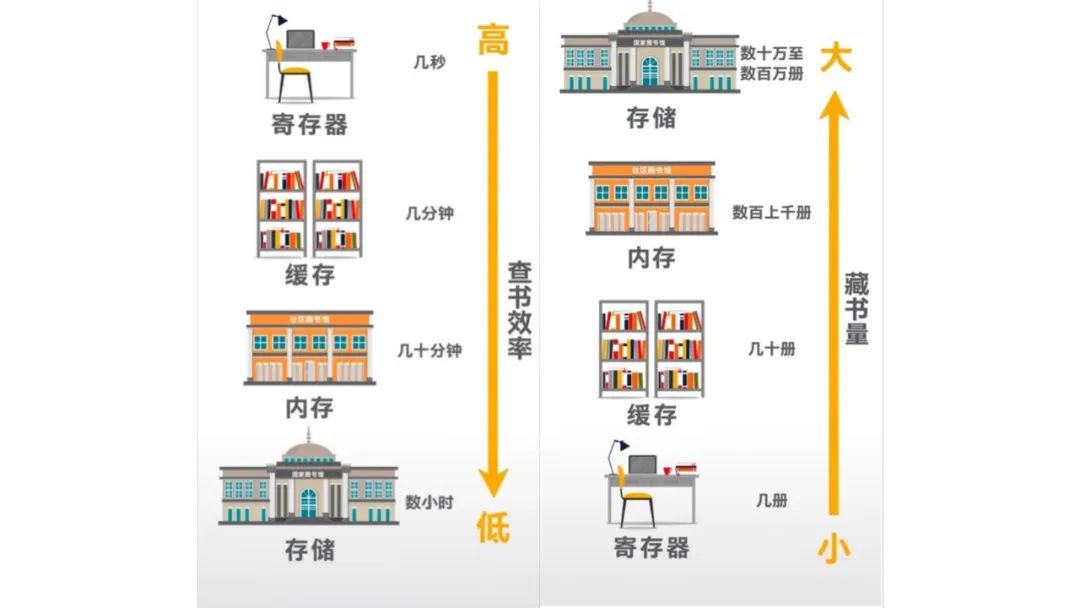

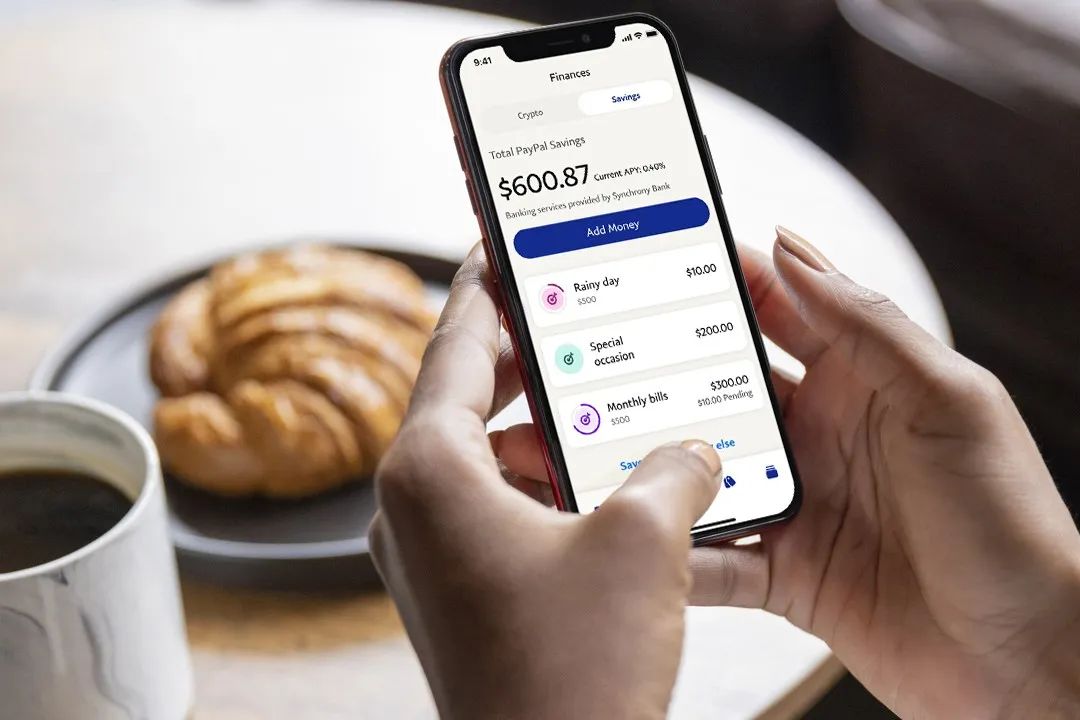
AlphaFold2 端到端高通量优化
除了傲腾™ 持久内存,还有哪些方案可以打破内存墙?

评论
 下载APP
下载APP
作者 | 张倩
内存不够只能割肉买 DRAM?英特尔:很多时候大可不必。
工业界的推理拦路虎:内存墙
打破推理内存墙,不用 DRAM 用什么?
AlphaFold2 端到端高通量优化
除了傲腾™ 持久内存,还有哪些方案可以打破内存墙?