
【干货】NLP中对"困惑度"感到困惑?
困惑度(Perplexity)在NLP中是个最流行的评估指标,它用于评估语言模型学的到底有多好.但是很多炼丹师可能至今对"困惑度"依然感到困惑,这篇就把这个讲清楚.假设我们要做个对话机器人,它功能很简单,就是你跟它说你冰箱有啥,它告诉你还需要买啥,能一起做出美味佳肴.例如"鸡肉,胡萝卜",它能够立马给出5~6种购物清单,这就类似用一个NLP模型,去预估和"鸡肉和胡萝卜"共现较多的食材.但是这样评估并不全面,真实情况是用这个NLP模型可能会产生很多新菜谱,然后按照新菜谱可能可以创造更好的美味佳肴?那还需要美食家去评价这个模型了.有没有一种指标,它独立于特定的任务,可以评估模型的质量呢?那就是困惑度了,它衡量了模型对自己预估结果的不确定性.低困惑度说明模型对自己很自信,但是不一定准确,但是又和最后任务的表现紧密相关.然后它又计算起来非常简单,用概率分布就可以计算.
困惑度如何算?
举个简单的例子,训练上述对话机器人的样本如下:
1. 鸡肉,黄油,梨
2.鸡肉,黄油,辣椒
3.柠檬,梨,虾
4.辣椒,虾,柠檬
这些句子,有6个word,我们学个模型就是给一个词,预估其他词和它一起共现的概率.最简单的模型就是unigram模型了,每个word都是独立分布的,因为每个词都出现了两次,所以所有词出现的概率都是一样的:

这明显是个非常差的模型,无论你告诉这个模型你有啥,它都会随机给你挑选剩余食材.回到困惑度,我们希望有个评估指标,模型预估概率为1,评估指标能接近0,预估概率为0,评估指标接近∞,这表示模型有多"自信",很明显!那就是log函数了:
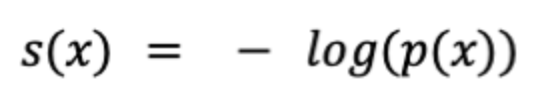
上述unigram模型用上式计算-log(0.16) = 2.64. 上式让我们联想到了信息熵, unigram的熵就是6 * (1/6 * 2.64) = 2.64:
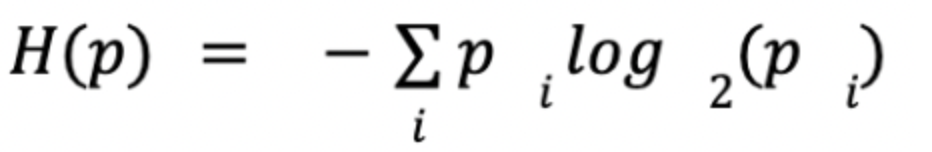
知道上式困惑度就很好算了,就是熵的指数:
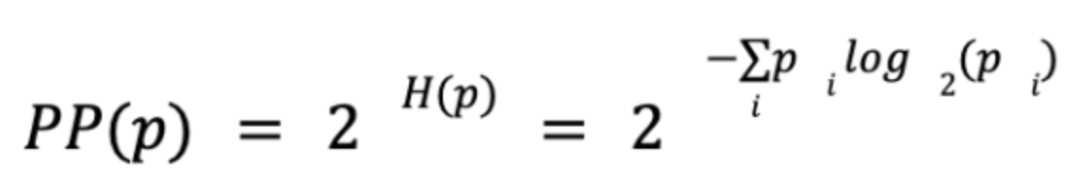
最终我们算出困惑度约等于6.这不就是我们vocabulary的大小吗?这就是你在句子中每个位置可以选择的可能单词的数量
perplexity不得不知的事!
低困惑度不能保证模型更好.首先,正如我们在计算部分所看到的,模型最糟糕的困惑度是由语言的词汇量决定的。这意味着您可以大大降低模型的复杂度,例如,只需从单词级模型(可能很容易具有50000多个单词的词汇量)切换到字符级模型(词汇量约为26),而不管字符级模型是否真的更准确。其他变量,如训练数据集的大小或模型的上下文长度,也会对模型的复杂性产生不成比例的影响。第二,也是更重要的一点,困惑和所有内部评估一样,不提供任何形式的理智检查,同困惑度的模型也是有好有坏的。
困惑度应用
当使用“困惑”来评估在真实世界数据集(如one billion word benchmark)上训练的模型时,可以看到类似的问题。这个语料库是由2011年发表的数千篇在线新闻文章组成的,所有这些文章都被分解成了句子。它被设计成一个标准化的测试数据集,允许研究人员直接比较在不同数据上训练的不同模型,而困惑度就是一个最普遍的基准选择。
不幸的是工作表明,模型的困惑很容易受到与模型质量无关的因素的影响。在三个不同的新闻数据集上训练相同的模型时,困惑度波动很大.由于“困惑度”可以有效地衡量模型模仿其所测试的数据集风格的准确程度,因此基于与基准数据集相同时期的新闻训练的模型由于词汇相似性而具有不公平的优势。
总结
优点:
计算速度快,允许研究人员在昂贵/耗时的真实世界能快速淘汰不太可能表现良好的模型.
有助于估算模型的不确定性/信息密度
缺点:
不适合最终评估,因为它只是测量模型的可信度,而不是准确性
很难在不同上下文长度、词汇大小、基于单词与基于字符的模型等的数据集之间进行比较。

点个在看 paper不断!