
「硬刚Doris系列」Apache Doris 架构原理及核心特性解读

一、架构原理
1.1 Doris整体架构
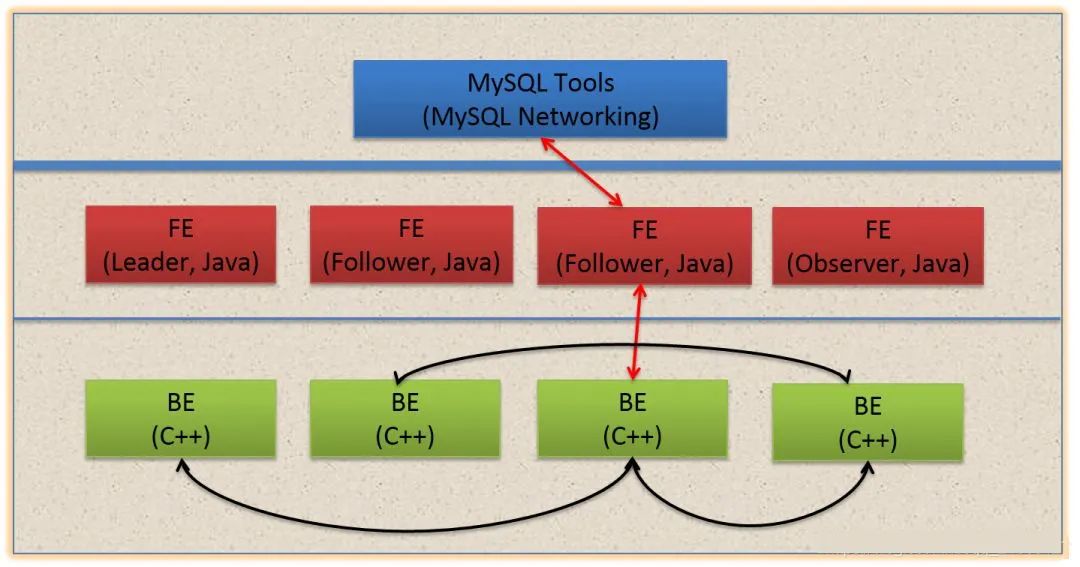
Doris主要分为FE和BE两个组件,FE主要负责查询的编译,分发和元数据管理(基于内存,类似HDFS NN);BE主要负责查询的执行和存储系统
这张图是Doris的整体架构。Doris的架构很简洁,只设FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于外部组件,方便部署和运维。
以数据存储的角度观之,FE存储、维护集群元数据;BE存储物理数据。
以查询处理的角度观之, FE节点接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果;BE节点依据FE生成的物理计划,分布式地执行查询。
FE主要有有三个角色,一个是leader,一个是follower,还有一个observer。leader跟follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
右边observer只是用来扩展查询节点,就是说如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加observer的节点。observer不参与任何的写入,只参与读取。
1.2 FE 元数据管理
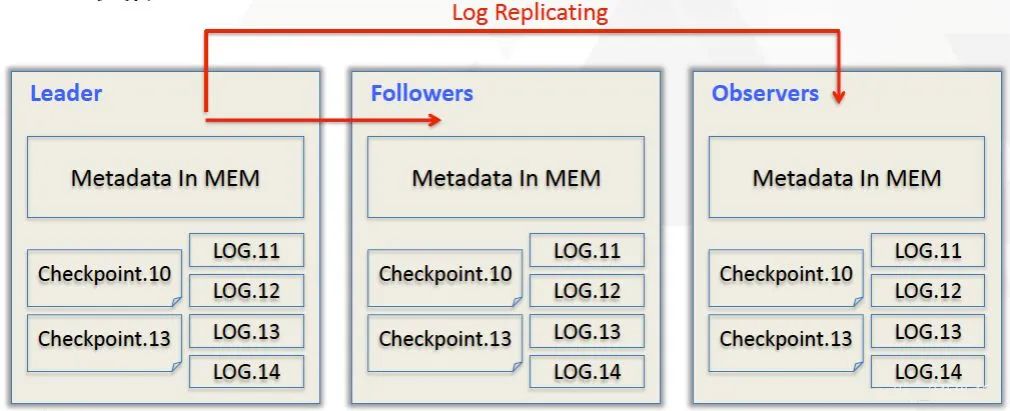
元数据层面,Doris采用Paxos协议以及Memory + Checkpoint + Journal的机制来确保元数据的高性能及高可靠。
元数据的每次更新,都首先写入到磁盘的日志文件中(WAL溢血日志),然后再写到内存中,最后定期checkpoint到本地磁盘上。相当于是一个纯内存的一个结构,也就是说所有的元数据都会缓存在内存之中,从而保证FE在宕机后能够快速恢复元数据,而且不丢失元数据。Leader、follower和 observer它们三个构成一个可靠的服务,这样如果发生节点宕机的情况,在百度内部的话,一般是部署一个leader两个follower,外部公司目前来说基本上也是这么部署的。就是说三个节点去达到一个高可用服务。以经验来说,单机的节点故障的时候其实基本上三个就够了,因为FE节点毕竟它只存了一份元数据,它的压力不大,所以如果FE太多的时候它会去消耗机器资源,所以多数情况下三个就足够了,可以达到一个很高可用的元数据服务。
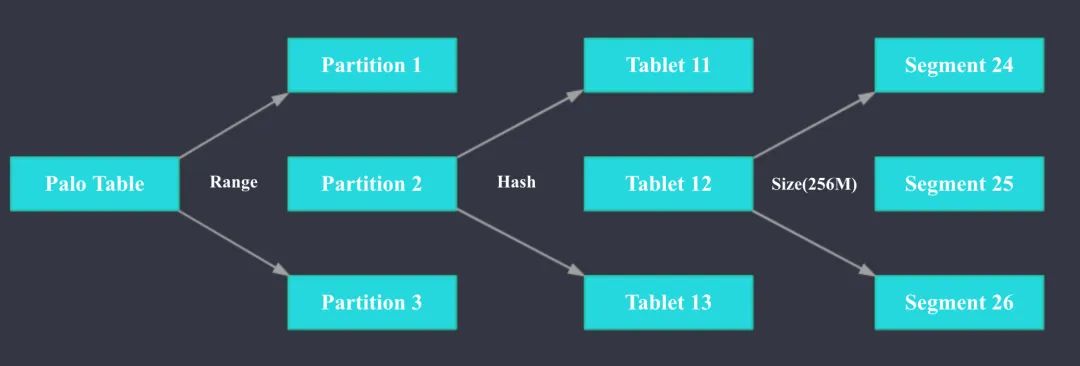
1.3 Doris数据组织
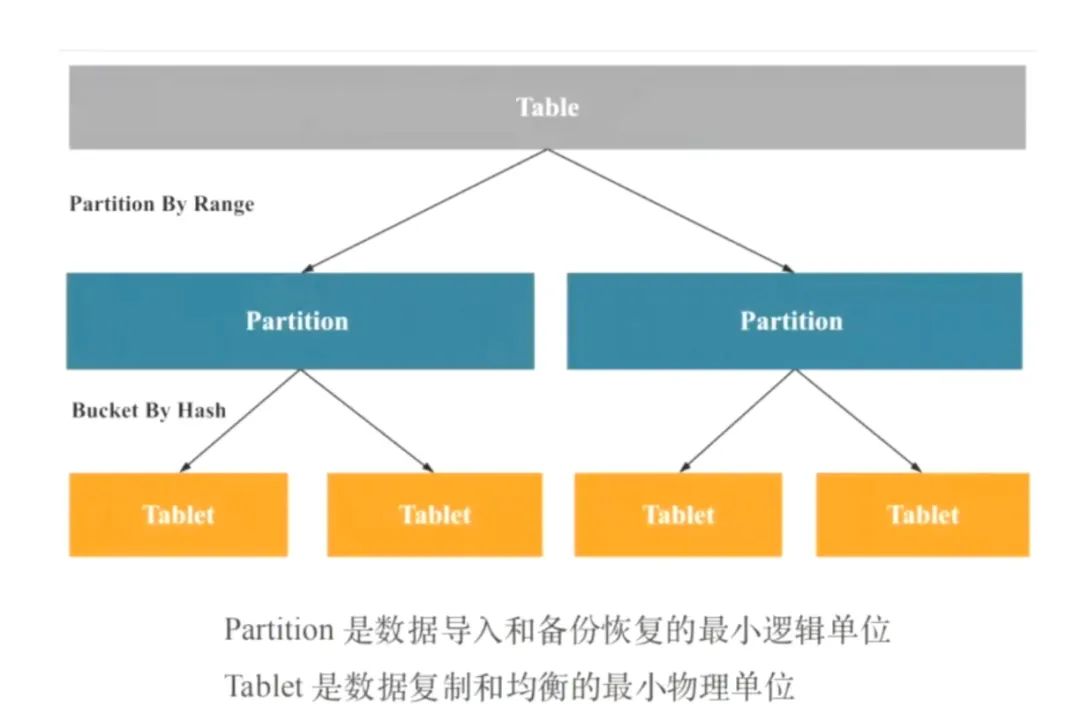
数据主要都是存储在BE里面,BE节点上物理数据的可靠性通过多副本来实现,默认是3副本,副本数可配置且可随时动态调整,满足不同可用性级别的业务需求。FE调度BE上副本的分布与补齐。
1.4 执行计划
doris最早是借鉴了Impala的查询引擎,把它改造了一下引入到Doris里面形成一个分布式的查询引擎。因为Impala是一个完全的P2P的结构,每个节点都缓存元数据,对于一个高性能的报表分析来说,它有可能会面临着元数据落后的问题。所以把Impala查询规划所有的部分,都放到了一个FE里面,都会由FE来完成。FE来根据用户的查询生成一个完整的逻辑规划,然后这个逻辑规划最后生成一个分布式的逻辑规划,会发给整个集群去执行
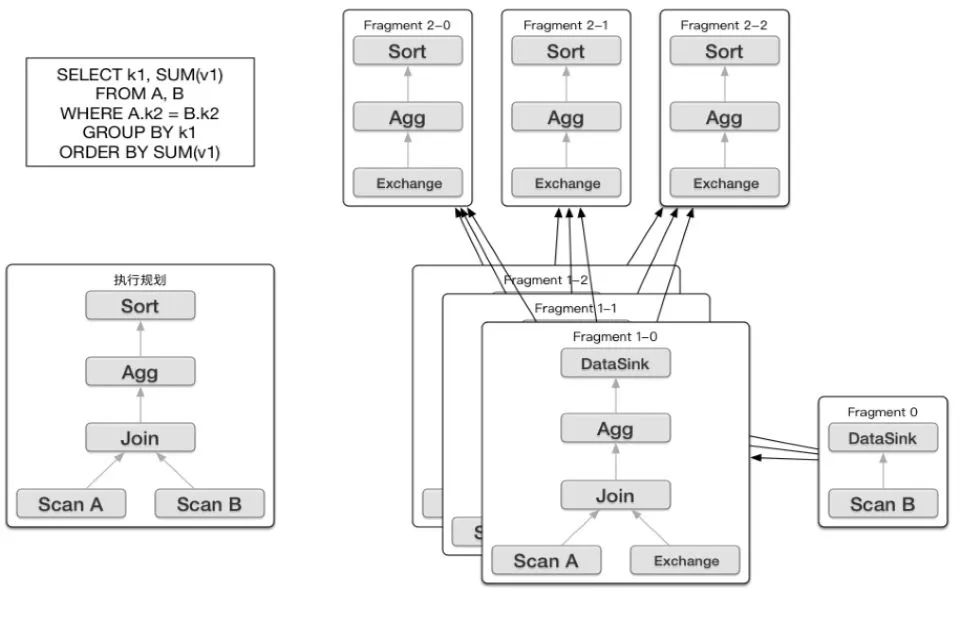
Doris的FE 主要负责SQL的解析,语法分析,查询计划的生成和优化。查询计划的生成主要分为两步:
生成单节点查询计划 (上图左下角)
将单节点的查询计划分布式化,生成PlanFragment(上图右半部分)
第一步主要包括Plan Tree的生成,谓词下推, Table Partitions pruning,Column projections,Cost-based优化等;
第二步 将单节点的查询计划分布式化,分布式化的目标是最小化数据移动和最大化本地Scan,分布式化的方法是增加ExchangeNode,执行计划树会以ExchangeNode为边界拆分为PlanFragment,1个PlanFragment封装了在一台机器上对同一数据集的部分PlanTree。
如上图所示:各个Fragment的数据流转和最终的结果发送依赖:DataSink。
当FE生成好查询计划树后,BE对应的各种Plan Node(Scan, Join, Union, Aggregation, Sort等)执行自己负责的操作即可。
二、特性
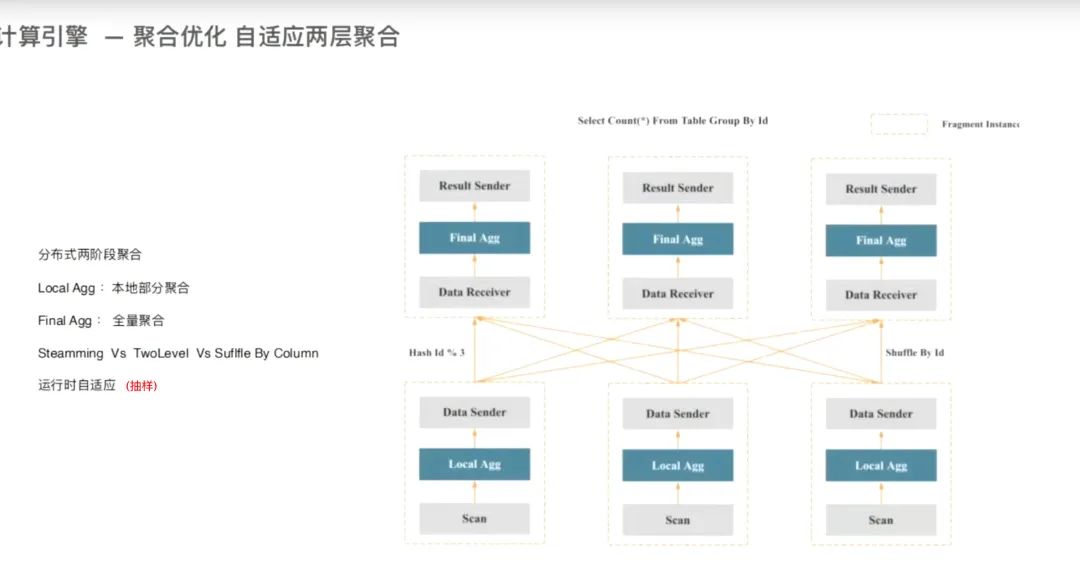
2.1 JOIN 两阶段聚合自适应
doris 不仅自适应Broadcast/Shuffle Join 方式,也可手动进行 Colocation Join ,也能在这些join 基础上自适应的进行两阶段聚合。
运行时会对数据进行采样,来判断是否进行两阶段聚合
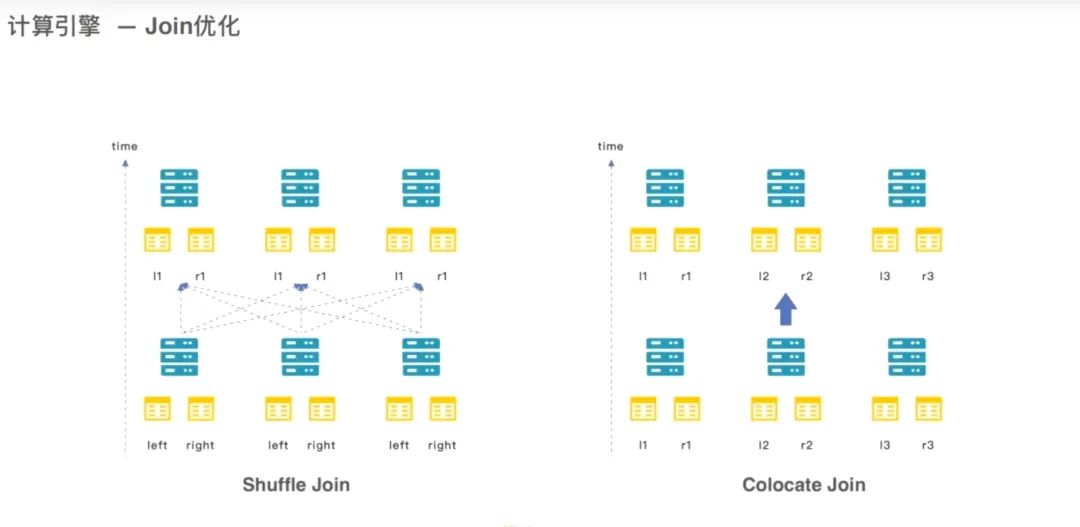
2.2 JOIN 优化 Colocation Join
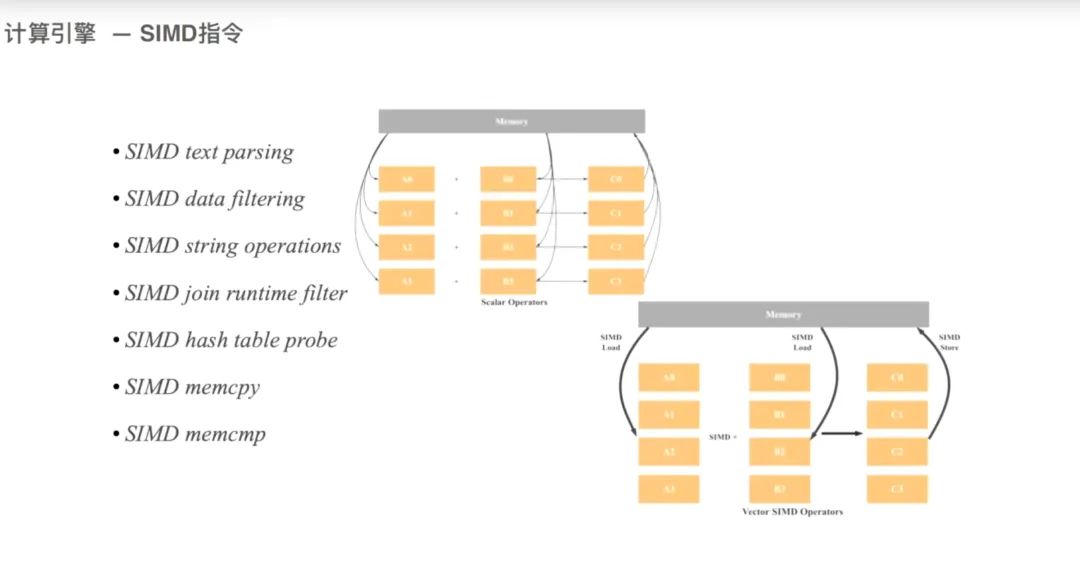
2.3 向量化执行

2.4 动态添加 rollUp
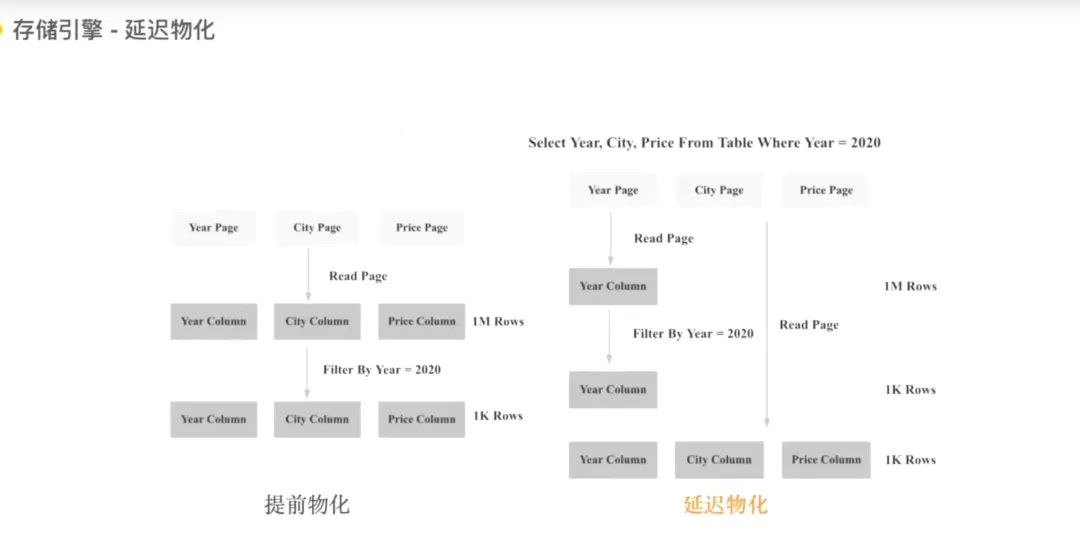
2.5 物化视图-延迟物化
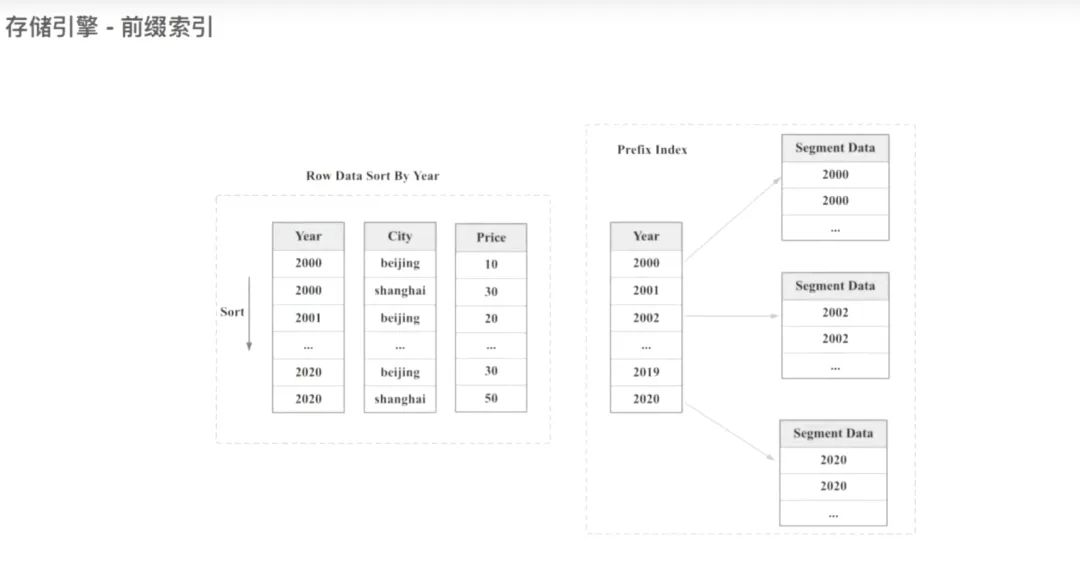
2.6 前缀索引
2.7 支持Roaring BitMap 索引

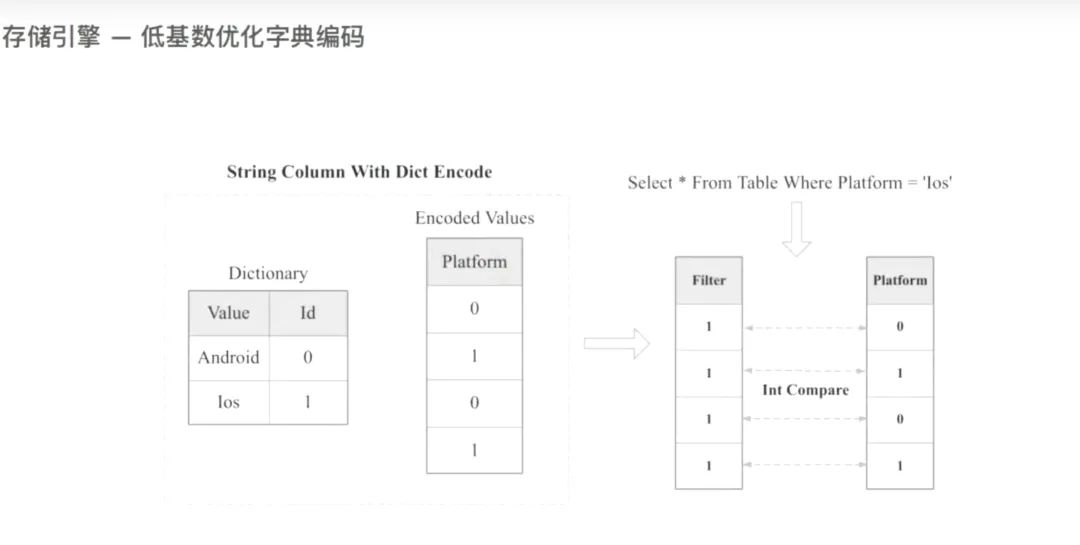
2.8 低基数的字典编码
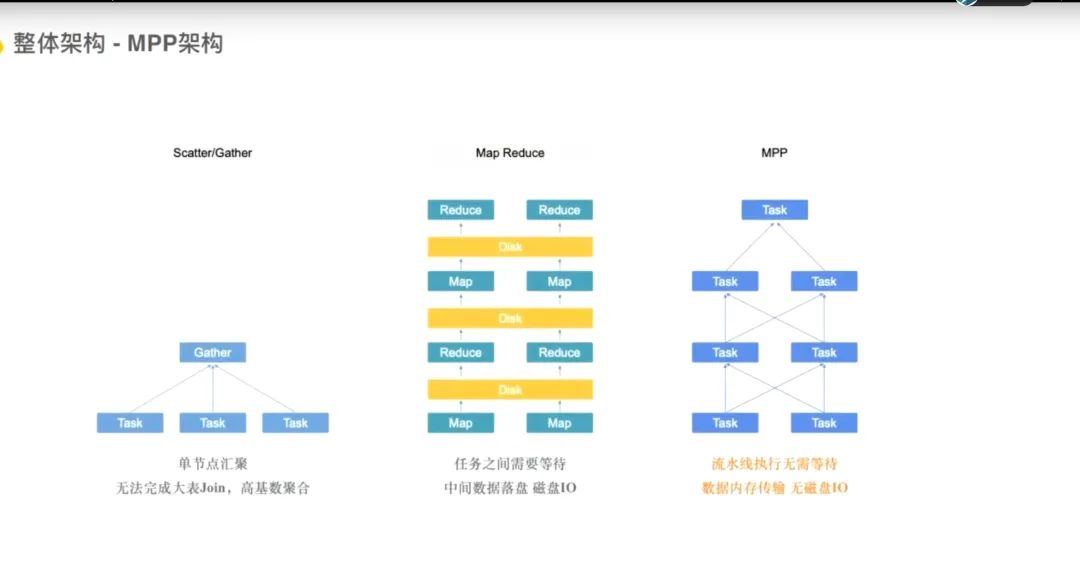
2.9 MPP架构
2.10 Doris On ES
CREATE EXTERNAL TABLE `es_table` (
`id` bigint(20) COMMENT "",
`k1` bigint(20) COMMENT "",
`k2` datetime COMMENT "",
`k3` varchar(20) COMMENT "",
`k4` varchar(100) COMMENT "",
`k5` float COMMENT ""
) ENGINE=ELASTICSEARCH
PARTITION BY RANGE(`id`)
()
PROPERTIES (
"hosts" = "http://192.168.0.1:8200,http://192.168.0.2:8200",
"user" = "root",
"password" = "root",
"index" = "tindex”,
"type" = "doc"
);
select * from es_table where esquery(k4, '{ "match": { "k4": "doris on elasticsearch" } }');
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)