
多LLM协同作战!清华等开源多智能体框架AgentVerse:合作打造Minecraft物品,还能训练宝可梦

新智元报道
新智元报道
编辑:LRS
【新智元导读】一个语言模型搞不定的问题,使用AgentVerse自动分解成子任务,多个LLM一起上,争取超过诸葛亮!
人类之所以能够爬到地球的食物链顶端,甚至还能继续探索外太空,除了个人的头脑外,更离不开群体的协作力量。
对应到大型语言模型(LLM),虽然单个模型的能力已经非常强大,但想要完成更复杂的任务,或是提升任务的完成效率,还需要多个智能体之间的协作。
最近,受人类群体动力学(human group dynamics)的启发,来自清华大学、北邮和腾讯的研究人员提出了一个多智能体框架AgentVerse,可以让多个模型之间进行协作,并动态调整群体的组成,实现1+1>2的效果。

论文链接:https://arxiv.org/pdf/2308.10848.pdf
开源链接:https://github.com/OpenBMB/AgentVerse
AgentVerse的主要特点包括三点:
1. 高效的环境搭建:框架中提供了多个基本构建模块,只需要在配置文件中添加几行代码,即可轻松搭建多智能体环境,如LLM聊天室等,研究人员只需要关注实验过程和结果分析即可。
2. 可定制的组件:多智能体环境被分为五个功能模块,并定义各自的接口,用户可以基于自己的需求重新定义不同模块的功能。
3. 工具(插件)利用:支持BMTools中提供的工具。
实验结果表明,该框架可以有效地部署多智能体群组,其性能优于单智能体,并且涌现了协作等社会行为。
AgentVerse框架
AgentVerse框架
解决问题(Problem Solving)的过程是人类群体中一系列迭代阶段,最初,该小组评估当前状态和预期目标之间的差异,动态调整其组成以加强决策中的协作,随后执行明智的行动。
为了增强自主多智能体群体实现其目标的有效性,我们模拟了一个人类群体的问题解决过程,提出了AGENTVERSE框架,该框架由四个关键阶段组成:专家招募、协作决策、行动执行和评估。
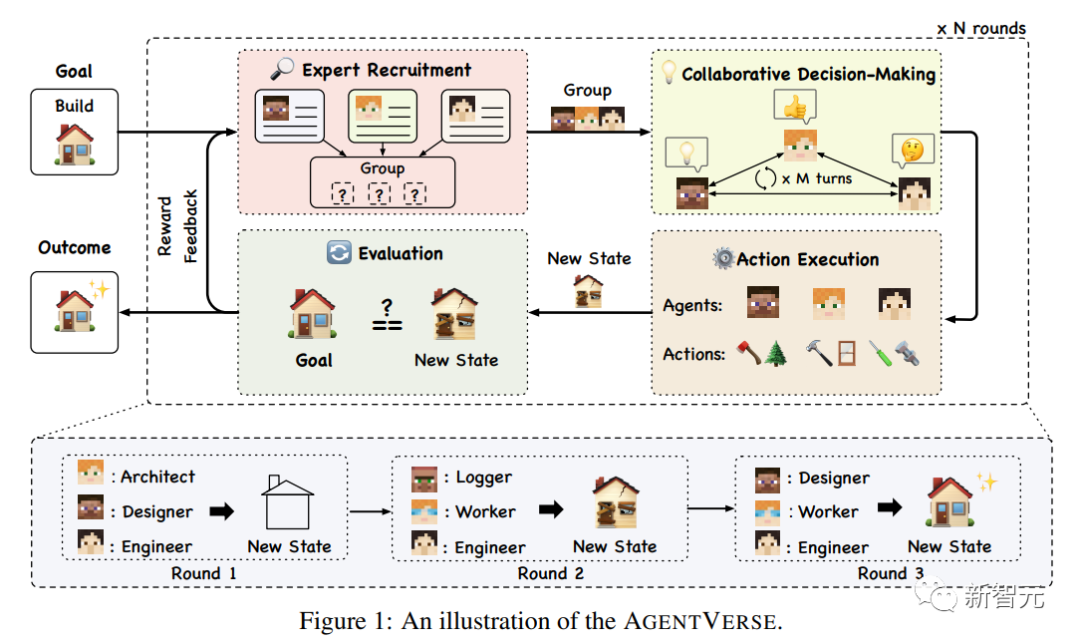
整个过程可以建模为马尔可夫决策过程(MDP),表征为元组(S,a,T,R,G)。这包括自主代理和环境状态空间S、解决方案和行动空间A、转移函数T:S × A→S、奖励函数R和目标空间G。
1. 专家招募(Expert Recruitment)
专家招募阶段决定了多智能体群体的构成,是决定群体能力上限的重要模块,已经有经验证据表明,人类群体内部的多样性引入了不同的观点,从而提高了群体在不同任务中的表现。
也有研究结果表明,为自主智能体脂定一个特定角色,类似于招募专家组建团队,可以提高运行效率。
不过,目前为智能体分配角色描述的方法主要依赖于人类直觉和先验知识,需要基于任务理解进行手动分配,所以可扩展性仍然不明确,尤其是在面对多样化且复杂的问题环境时。

鉴于此,AgentVerse采用自动化的方式来招募专家,目的是增强配置智能体的可扩展性。
对于给定的目标g∈G,特定的自主智能体Mr被指定为招聘者(recruiter),类似于人力资源经理;Mr 不依赖预定义的专家描述,而是根据当前目标g动态地生成一组专家描述。
然后根据不同的专家描述提示以及目标g,得到多个不同的智能体形成专家组M = Mr(g)
并且,多智能体群体的组成将根据评估阶段的反馈进行动态调整,也使得框架能够根据当前状态(收到的奖励)组建最有效的多智能体群体,以便在后续回合中做出更好的决策。
2. 协同决策
此阶段主要是聚集专家智能体进行协同决策,研究人员选择两种经典的沟通结构来提升决策效率:
横向沟通 ( Horizontal Communication)
每个智能体(表示为mi∈M)积极共享并细化其决策,这种民主的沟通结构鼓励智能体之间的相互理解和协作。
然后将智能体的集体意见结合起来,使用一个集成函数f来形成当前回合的群体决策。
在需要创造性想法或需要大量协调的场景中,例如头脑风暴、咨询或合作游戏等,横向沟通可能是更好的选择。
纵向沟通 (Vertical Communication)
纵向沟通的特点是职责分工,由一个智能体提出初始决策,其余的智能体充当评审人,对解决方案提供反馈;根据反馈,不断完善决策,直到所有的评审智能体就解决方案达成共识,或者达到最大迭代次数。
在需要针对特定目标迭代完善决策的场景中,例如软件开发,垂直沟通是更好的选择。
3. 行动执行(Action Execution)
在决策制定完毕后,智能体需要执行指定的动作,具体取决于实现方式,某些智能体可能会不执行任何操作,然后对环境状态进行更新。
4. 评估(Evaluation)
评估对于下一轮专家组的构成调整和提升起到至关重要的作用,使用奖励反馈机制评估当前状态与期望目标之间的差距,并给出口头反馈,解释为什么当前状态仍然不令人满意并提供建设性建议,讨论下一轮如何改进。
其中奖励反馈机制可以由人工定义(人机协作循环),也可以由自动反馈模型定义,具体取决于实现方式。
如果确定尚未达到预期目标,则奖励反馈循环回到初始阶段,即专家招募;在下一轮专家招募阶段会利用该反馈信号结合初始目标来调整专家组的构成,从而演化出更有效的多智能体群组,以供后续决策和行动执行。
实验部分
实验部分
为了证明AgentVerse能够指导智能体群组高效地完成任务,研究人员对基准任务进行了定量实验,并对更复杂和实际的应用进行了案例研究。
实验设置
研究人员选择了两个语言模型作为底层支持:GPT-3.5-Turbo-0613和GPT-4-0613
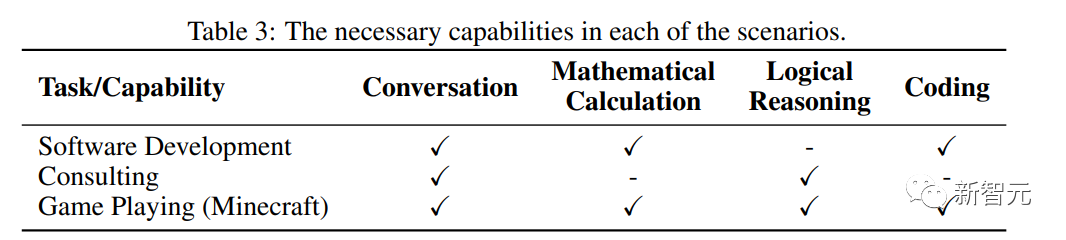
在数据集和评估指标的选择上,主要考察多智能体群组在四个方面的能力:
1. 对话(Conversation)能力
第一个数据集为对话(Dialogue)回复数据集FED,给定多轮聊天历史记录,智能体需要生成回复内容,使用GPT-4作为评估器,对模型生成的回复和人类编写的回复进行评分,并报告模型的胜率。
第二个数据集为约束生成Commongen-Challenge,给定20个概念,智能体需要生成一个语义连贯且语法正确的段落,并且应当包含尽可能多的概念。
2、数学计算(Mathematical Calculation)能力
利用MGSM 的英语子集,包含小学级别数学问题,指标为正确答案的百分比。
3. 逻辑推理(Logical Reasoning)能力
利用BigBench的逻辑网格谜题(logic grid puzzle)任务,其中包含需要多步骤逻辑推理的逻辑问题,使用准确率指标。
4. 编码(Coding)
利用代码补全数据集Humaneval,使用Pass@1指标进行评估。
实验结果
性能分析
单个智能体(Single)使用给定的提示直接生成答案,而用AgentVerse构建的多智能体群组(Multiple)以协作的方式解决问题。
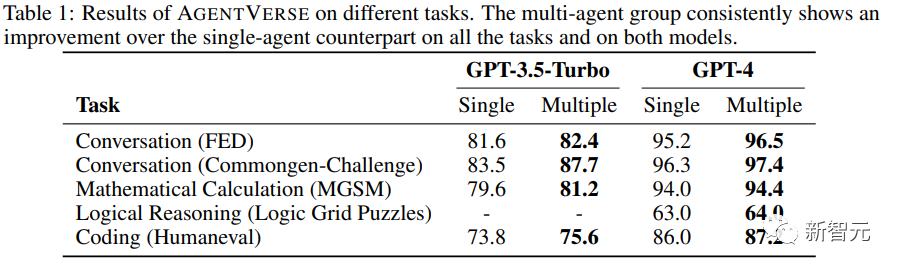
从结果中可以看出,无论使用GPT-3.5-Turbo还是GPT-4,多智能体始终优于单智能体。
由于GPT-3.5-Turbo很难在逻辑网格谜题数据集上给出正确的推理结果,所以表中省略了相应的实验结果。
协作决策分析
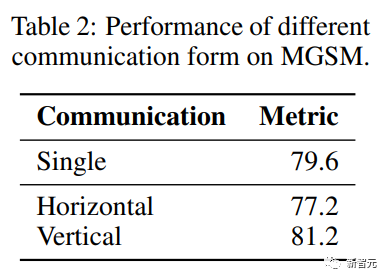
与纵向沟通相比,水平沟无法促进数学计算任务 (MGSM) 上的多智能体群组有效决策,进一步分析可以发现,沟通架构对于塑造决策结果来说至关重要。
在横向沟通中,智能体以顺序的方式进行沟通,某个智能体可能会提出有缺陷的解决方案或质疑其他智能体的正确主张,其他智能体往往不会纠正错误,而是遵循错误的决策,导致性能低于单智能体。
而在纵向沟通中,其他智能体只需要提供反馈,虽然建议可能会存在缺陷,但大多数智能体有建设性的批评通常会缓解错误,从而使核心智能体可以保留准确的解决方案。
不过这也不意味着横向沟通效率较低,只是说在需要精确答案的任务上,纵向沟通更合适;而在咨询等需要不同解决方案的任务中,横向沟通更合适。
案例研究:软件开发
案例研究:软件开发
研究人员在文中设计了三个案例任务,下面以软件开发为例
任务描述
视频游戏中往往会提供复杂的虚拟环境,可以有效测试智能体的能力边界,研究人员以沙盒游戏《我的世界》(Minecraft)为实验平台,游戏的机制和大量可制作的物品集合要求智能体不仅要执行任务,还要计划、协调和适应动态场景。
研究人员的目标是利用AgentVerse整合多个智能体来合作制作特定的物品,测试智能体在复杂的环境中共享知识、资源和协作的能力。
实验分析
实验中,要求三个智能体合作制作一个书架,其过程至少包含九个基本步骤,如收集木材和皮革等材料,制作书籍等中间物品,最后组装书架。
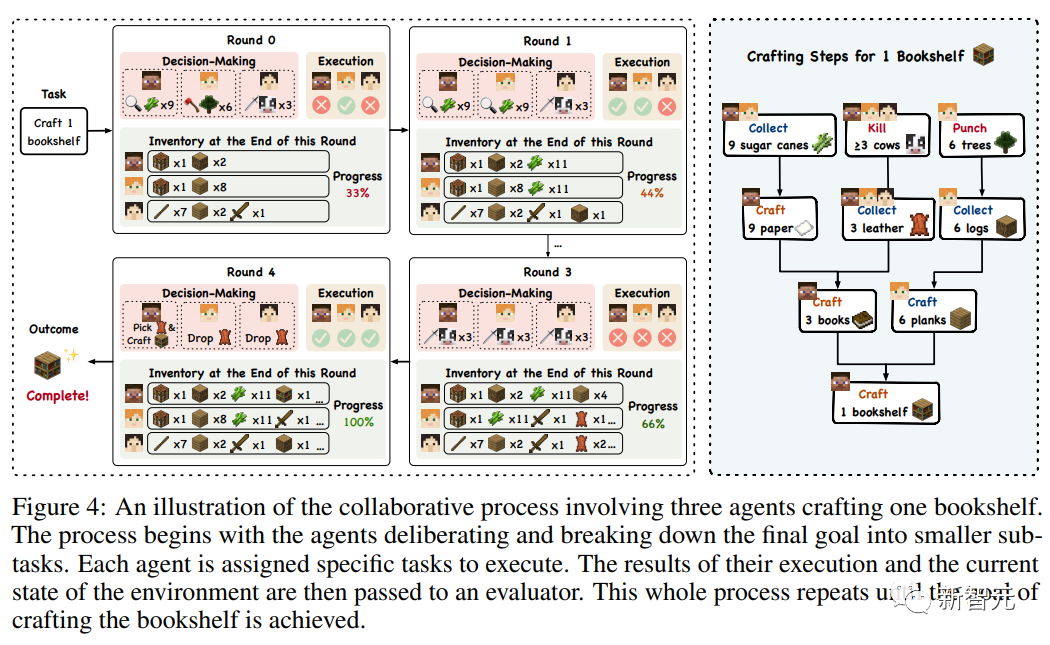
由于游戏中只有玩家一种身份,所以AgentVerse框架中的专家招募阶段可以省略,直接通过提示指定模型扮演《我的世界》中经验丰富的玩家即可。
智能体可以将制作书架的整体目标分解成正确的子任务,战略性地分配并分发执行。
一个值得注意的观察是智能体的适应性和合作本能,例如,在最初的几轮比赛中,当Alice努力淘汰皮革所需的三头奶牛时,Bob辅助完成了指定的任务,他注意到了Alice面临的困难,从而介入并提供帮助。
类似的涌现行为非常关键,凸显了智能体在面临意想不到的挑战时的健壮性和灵活性。
参考资料:
https://github.com/OpenBMB/AgentVerse


