
「深呼吸」让大模型表现更佳!谷歌DeepMind利用大语言模型生成Prompt,还是AI更懂AI

新智元报道
新智元报道
编辑:Lumina
【新智元导读】谷歌DeepMind提出了一个全新的优化框架OPRO,仅通过自然语言描述就可指导大语言模型逐步改进解决方案,实现各类优化任务。
「深呼吸,一步一步地解决这个问题。」
这句像你在冥想时会听到的话,其实是大语言模型的Prompt提示词!

只是多了「深呼吸」的命令,模型在GSM8K的得分就从「think step by step」的71.8上升至80.2,成为表现最佳的Prompt。
「深呼吸」是人类常常用来放松、集中的手段之一。
但令人好奇的的是,为什么对并不能「呼吸」的大模型,「深呼吸」也能提高它的表现?
有网友认为这是大模型在模仿人类,毕竟它可没有肺。
也有网友认为,或许是在人工智能的训练中,使用互联网资源让人工智能意外地负载了人性。
「我们无意中把情感赋予了机器。」

而这个Prompt也不是人类设计出的,而是模型自己生成的。
仿佛模型自己也更偏好带有鼓励、正向的Prompt。
但这也不是第一次有研究证实大模型会对交互中的正反馈作出积极的响应。
另一方面,随着技术的发展,大语言模型在各个领域都取得了令人瞩目的成绩。
它们理解自然语言的能力为优化提供了一种新的可能性:
我们可以不再使用程序化求解器来定义优化问题和推导更新步骤,而是用自然语言来描述优化问题,然后指示LLM根据问题描述和之前找到的解决方案迭代生成新的解决方案。
使用LLM进行优化时,只需更改提示中的问题描述,就能快速适应不同的任务,而且还可以通过添加指令来指定所需的解决方案属性,从而定制优化过程。
最近,谷歌DeepMind一篇研究介绍了使用LLM对自然语言的提示工程进行优化的方法,称为Optimization by PROmpting(OPRO)。

论文地址:https://arxiv.org/pdf/2309.03409.pdf
OPRO就是一种将大型语言模型(LLM)用作优化器的简单有效的方法。
OPRO的步骤如下:
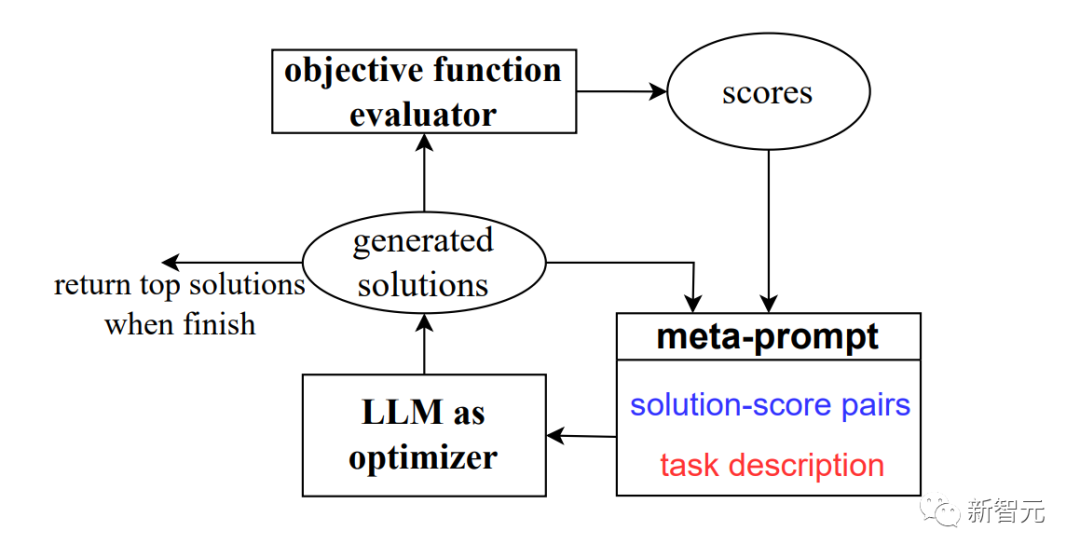
在每一步优化中,使用元提示(meta-prompt)向LLM描述优化问题。
元提示包含自然语言任务描述、以往生成的解决方案及其目标函数值。
然后,LLM根据元提示生成新的解决方案。
最后,计算新解的目标函数值,并加入元提示以进行下一步优化。
重复该过程,直到LLM无法再找到更好的解决方案。
研究表明,OPRO生成的最佳提示在GSM8K问题上超过人类设计的提示高达8%,在Big-Bench Hard任务上高达50%。
LLM作为数学优化器
「推理」是大语言模型的短处,基于诸多语料训练的这些模型在推理问题上的表现与文本处理相比十分糟糕。
就连最简单的加减乘除,大语言模型也会一本正经地「胡说八道」。
但谷歌DeepMind证实了OPRO在数学问题中也能优化模型的表现。
研究人员选择了线性回归作为连续优化的例子,旅行商问题(Traveling Salesman Problem, TSP)作为离散优化的示例。
线性回归
实验表明,仅通过提示LLM就能在线性回归问题上找到全局最优解。有时可匹敌专门设计的算法,证明了LLM作为优化器的潜力。

旅行商问题(Traveling Salesman Problem,TSP)
TSP实验证明,在小规模问题上LLM可通过提示实现类似专业优化算法的效果。
但对于大规模组合优化问题而言,LLM带来的性能仍需提升。

下图是在GSM8K上使用经过指令调整的PalM 2-I(PaLM 2-L-IT)进行提示优化的元提示例子。
生成的指令将被添加到评分器LLM输出中的A开头。
蓝色文本包含过去生成的提示和对应的分数,分数高的排在前面。这是一系列指令及其在训练集上的精度。
紫色文本描述了优化任务和输出格式要求,说明了生成指令的位置和作用。
橙色文本是元指令,提供了LLM如何进一步解释优化目标和如何使用给定信息。
<INS> 表示将添加生成指令的位置。

提示优化实验
实验将PaLM 2-L、text-bison、gpt-3.5-turbo、gpt-4作为优化器和评测模型。
并选择了GSM8K和Big-Bench Hard(BBH)作为评估基准。GSM8K是一个小学数学问题的基准,有7473个训练样本和1319个测试样本。
BBH是一套包含23个具有挑战性的BIG-Bench任务符号操作和常识推理的基准,每个任务包含多达250个示例。
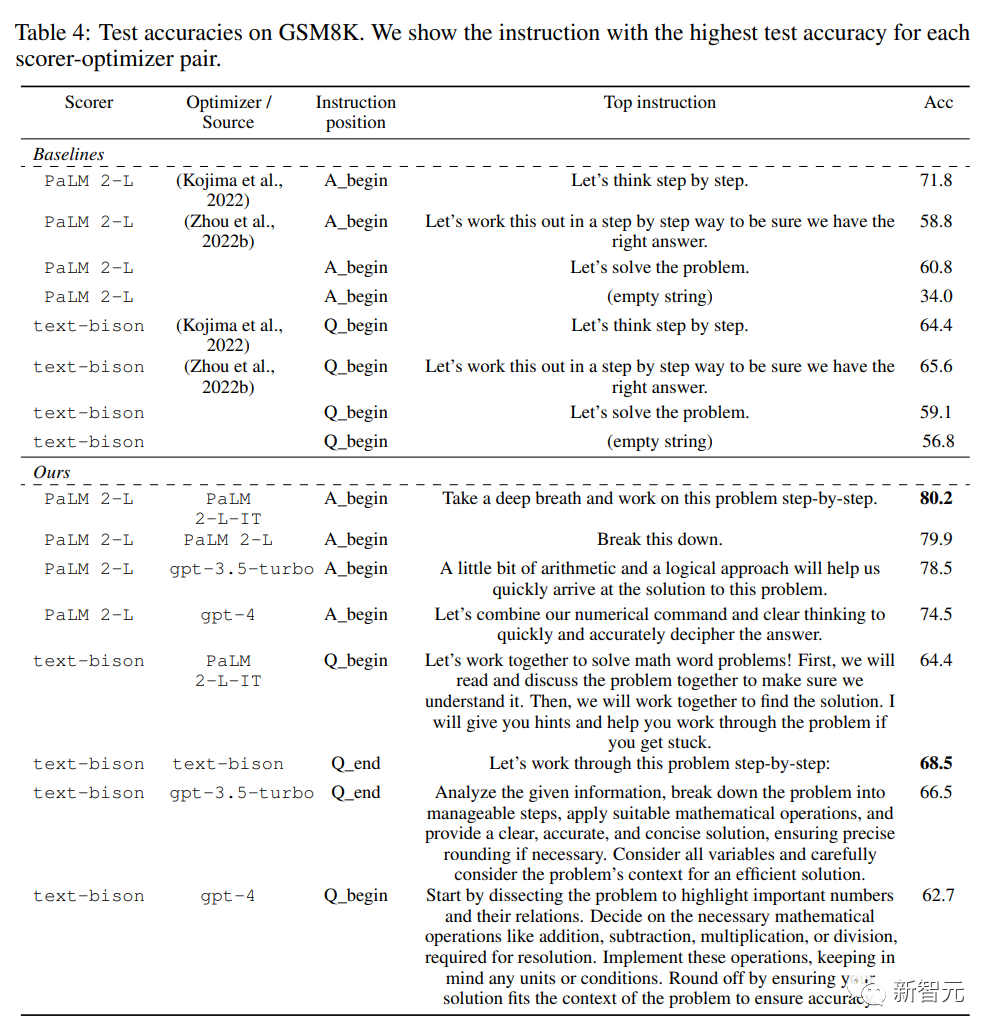
表4总结了使用不同LLM作为评分器和优化器在GSM8K上发现的顶级指令:
不同LLM作为优化器时,指令的风格差异很大:PalM 2-L-IT和text-bison的指令简洁明了,而GPT的指令则冗长而详细。
虽然有些得分高的指令中包含「step by step」,但大多数其他指令在语义不同的情况下也达到了相当或更高的准确度。
GSM8K结果
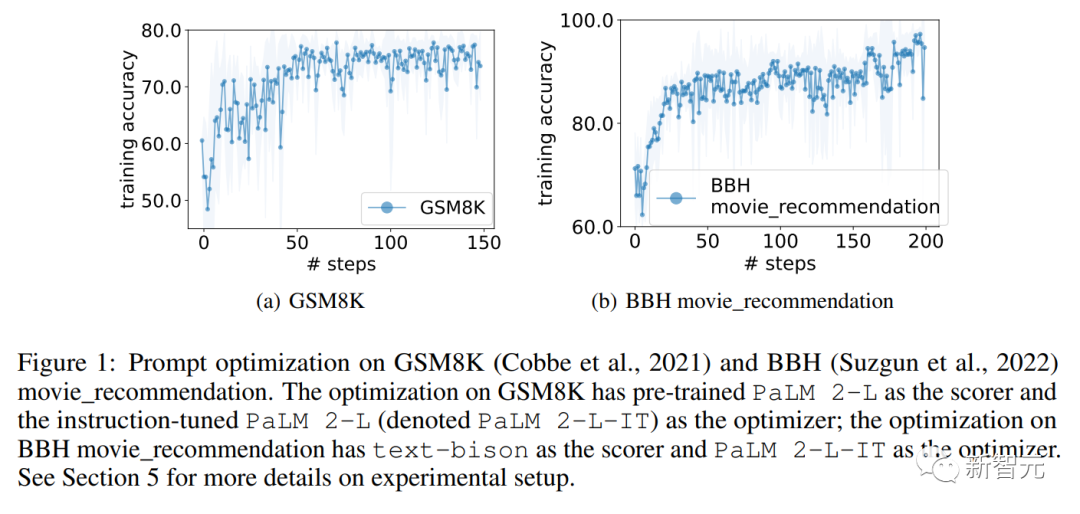
GSM8K上的优化以预训练的PalM 2-L作为评分器,以经过指令调整的PalM 2-I-IT作为优化器。
BBH的电影推荐上的优化以text-bison作为评分器,以PalM 2-I-IT作为优化器。
下图显示了在预训练的PalM 2-L和PalM 2-I-IT作为优化器的即时优化曲线:
曲线整体呈上升趋势,并在整个过程中出现了几次跳跃。
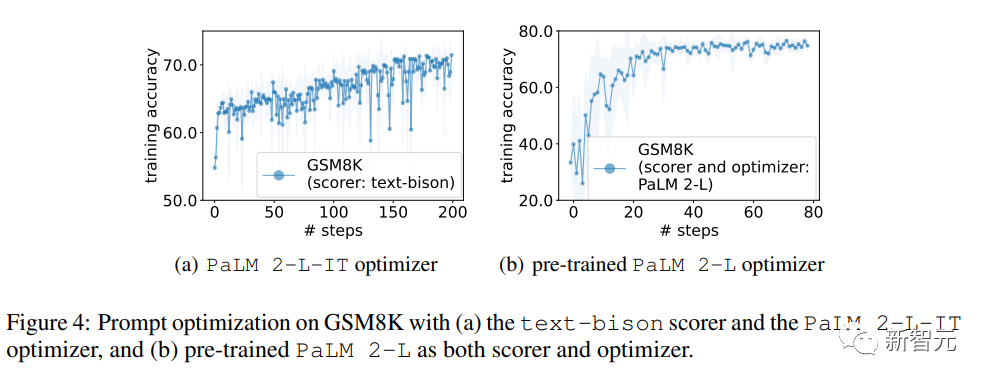
接下来,研究人员使用(a)text-bison评分器和PalM 2-L-IT优化器,以及(b)预训练 PaLM 2-L作为评分器和优化器,在 GSM8K 上进行提示优化。
下图中的优化曲线也呈现出了类似的上升趋势。
BBH结果
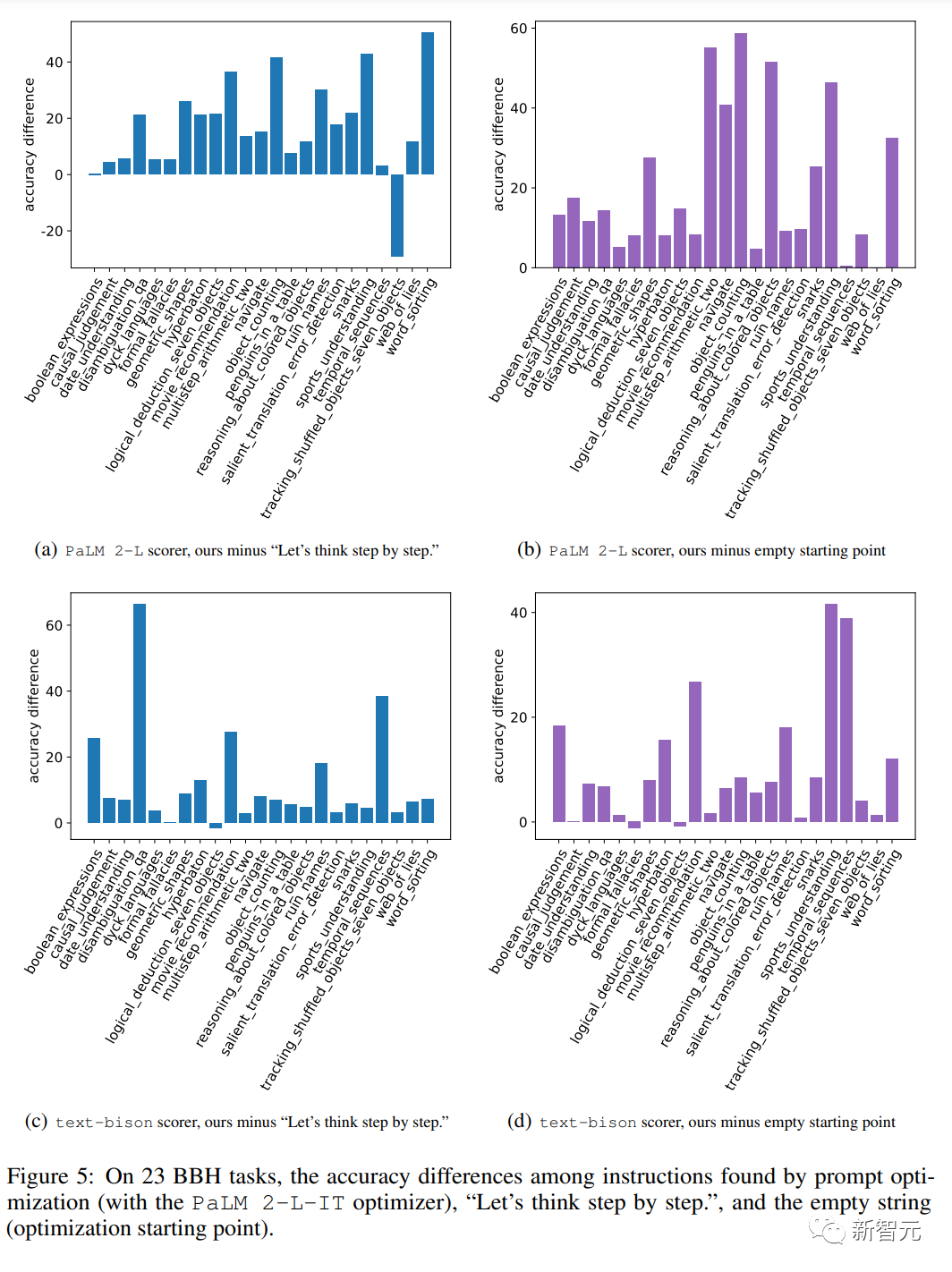
研究人员还在BBH数据集上进行了提示优化。与GSM8K类似,其优化曲线也基本呈上升趋势。这表示随着优化,生成的提示性能逐步提升。
但优化得到的提示大多数任务上比「Let's think step by step」提示效果好5%以上,个别任务提升可达50%以上。
与空提示相比,找到的提示在大多数任务上也有5%以上的显著提升。
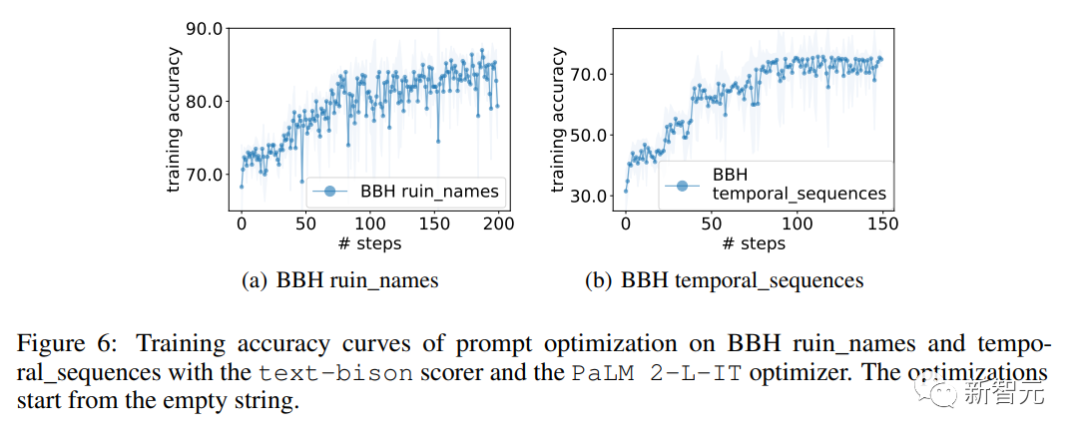
而在一些具体任务如ruin_names上,后期生成的提示通过替换关键词子句的方式进行释义改写,从而获得进一步提升。
可以看到,不同优化器找到的提示语义和风格有所不同,但效果相近。
一些任务优化过程中也出现了精度飞跃,对应生成提示的质的飞跃。
综上,BBH数据集的优化实验也验证了方法的有效性。
提示优化可以持续改进性能,明显超过强基线。但小的语义变化带来的效果提升显示了提示优化的难点之一。
下表比较了不同模型对于同一任务找到的不同提示风格,验证了提示优化可以广泛适用于不同模型,并给出每个任务的最优提示。

总而言之,这项研究首次提出并验证了使用大语言模型进行优化的有效性,为利用LLM进行更广泛优化任务提供了框架和经验,是这个新的研究方向的开拓性工作,具有重要意义。
参考资料:
https://arxiv.org/pdf/2309.03409.pdf


