
黄雨龙:一群人可以走的更远!
这半年,我从跨专业找到数据分析实习岗位,到开始边实习边学习。本文记录了我在企业实习的整个学习经历,同时也分享了和Datawhale相识的过程,以及在Datawhale和小伙伴们一起学习成长的经历。
我的实习经历
关注「Datawhale」公众号有5个月了(好像是在GitHub找《西瓜书》资料偶然发现的),让我感触最深的是:每次我生活中遇到问题,Datawhale刚好会在那段时间推送符合我需求的文章。
比如:
去年10月,我有幸找到了一家数据分析的实习岗位。因为我是跨专业找工作,所以对商业数据分析的了解几乎为零。刚好在2020年11月份推送了一些 房租数据分析(可点击)相关文章,让我初步了解数据分析的简单流程。因为后面我的实习岗位是做SQL开发,所以这些文章对我有了一定的启发。 去年11月,通过一个月的实习,我的SQL能力得到了很好的锻炼,开始真正参与数据开发工作:GJ项目。在GJ项目包含3部分内容:商业标签开发(我完成开发)、预测算法(用GBDT实现) 和 线性规划算法(用混合整数规划MILP实现)。完成商业标签开发任务中,我开始梳理两个算法实现逻辑文档(主要给客户讲明白)。这个时间段Datawhale刚好又推送了 逻辑回归+GBDT模型融合实战(可点击)、异常值检测等系列文章让我收获很多(因为商业的原始数据太“脏”了p.p)。这是我第一次接触机器学习相关知识。
去年12月-今年1月,因为GJ项目合同变更被迫停止,中间我参与到了另外两个项目(GBL项目、LULU项目)的数据开发工作,主要做SQL做报表开发。一共完成了近20张报表开发工作量。因为前面有参与两个算法的调研,开始自学《西瓜书》(我的机器学习入门书籍)。《算法图解》这本书是我算法入门的书籍,认真读了几遍收获很多。刚好这段时间Datawhale又推送了 基于Dijkstra算法的武汉地铁路径规划(可点击),我照着文章做了上海的路径规划(因为在上海出差p.p)。
今年2月末,结束了前面两个项目的任务,GJ项目又重新启动。实习4个月的我,突然被“委以重任”,让我到客户现场全权负责整个项目的沟通与开发工作。最主要的是将两个算法任务也由我来负责。幸好这个时候已经将《西瓜书》前10章内容啃了一遍,也在B站上面上传了7个学习理解视频(B站号:我们都来自星尘)、在个人公众号(yunzhib612)和知乎上开始写一些机器学习中基础概念的理解文章。所以能让我负责这两个算法,压力是有的,但也有一定的信心,挑战与机遇同在嘛。
今年3月,我首先选择尝试做预测算法:基于商品销量做预测(典型的时序数据)。这个时候Datawhale三月份新的组队学习(前面一直在看,因为基础差只敢观望p.p),当我看见数据挖掘学习赛-心跳信号分类我立刻心动了,因为学习内容涉及到时序数据分类,虽然跟工作要求(回归预测)不一样,但我觉得对理解GBDT算法会有很大帮助。另外出于私心:我个人专业是天文学,在校要处理一些天文观测数据(也是时序数据),根据观测到的数据特征给出一个星系类型的判别(时序分类)。便欣然报名参加了这个学习赛。
上面的时间轴即是自己真实的实习经历,也是我开始逐渐了解Datawhale的一个过程。后面根据自己的需求欣然参加了这个月的组队学习「心电信号分类学习赛」。
我的学习经历
我参与的是Datawhale三月的数据挖掘学习(一般每月第二周的周四会发文),目前学习已经结束,有需要的可以根据开源地址自己学习,同时记录了我参与学习的心得,希望对大家有所帮助。
开源地址:
https://github.com/datawhalechina/team-learning-data-mining/tree/master/HeartbeatClassification
我自己写的完整笔记:
以下是我参与学习的记录总结:
Task00:熟悉规则(1天),打卡日期2021-03-15 ,Datawhale视频介绍了学习的流程,主要是提前准备好:学习输出平台(如知乎)并在学习赛界面注册一个账号(获取数据及上传数据)。
Task01:赛题理解及Baseline学习(2天),打卡日期2021-03-17,基于LightGBM算法实现数据挖掘 是我对Task01任务的理解笔记。良好的赛题理解是选择合适模型的基础(学习赛其实已经帮忙选择好了LGBMp.p)。对评估函数的理解是后续模型调参的方向(希望模型结果最好嘛)。
评测公式:
 如果真实结果为,模型预测为;则得分值为: 。内在含义是考察与实际结果「1」的误差大小,即更关注「模型准确率」。
如果真实结果为,模型预测为;则得分值为: 。内在含义是考察与实际结果「1」的误差大小,即更关注「模型准确率」。模型选择:赛题为「多分类问题」,可以考虑「决策树」、「逻辑回归」、「贝叶斯分类」等方法实现。详细的内容思考见上面文章链接。
Task02:探索性数据分析(EDA)(3天),打卡日期2021-03-20,
我认为探索性数据分析是一个很重要的环节,从开始 470分 到 300分 提高,最关键是处理了数据不平衡问题。由于“心跳信号分类学习赛”所给的数据质量太好了,所以Task02文档内容仅仅给出了一些统计展示,并没有给出实际过程的处理方法(缺失值处理、数据格式处理、异常值处理等等)。这样很让人忽略这种步骤的重要性(毕竟是学习赛,面向初学者)。在数据理解与模型选择(链接:https://zhuanlan.zhihu.com/p/358431898) 这篇学习中,记录了自己对数据的重新认知过程。在学习赛过程中对数据特征反复观察,往往能产生更好的想法。前面观看了Datawhale B站的「鱼佬数据挖掘直播」,让我对后续的关注的「数据特征」有了自己的想法,视频地址:
https://www.bilibili.com/video/BV1SX4y137L6
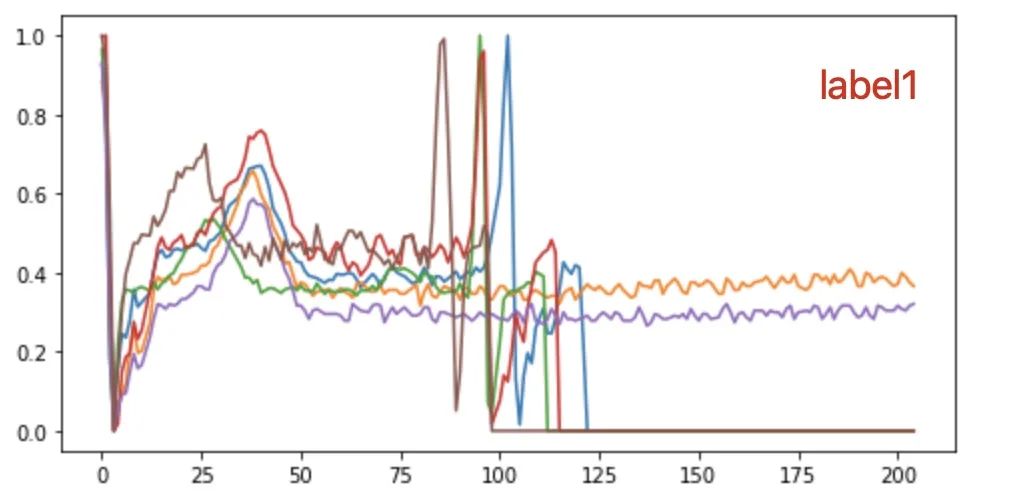
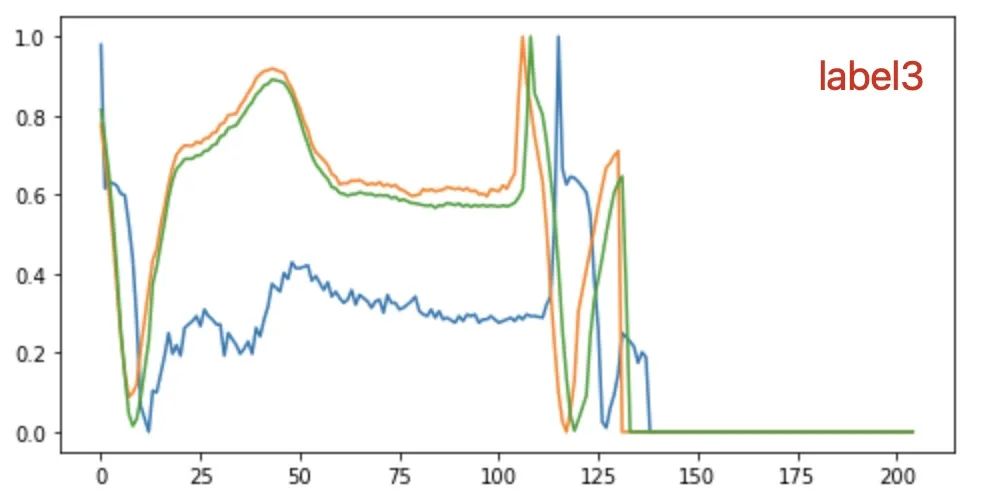
多画出几组数据观察不同label下的数据特征,可以发现 “label3的数据 比 label1的数据均值要大一些”,所以在原有的数据集中(or自己根据关心的特征构建一个新的数据集),可以添加「均值」这个特征。当然这个地方只是小小的举例,重点来表达「数据特征再思考」
数据不平衡问题:
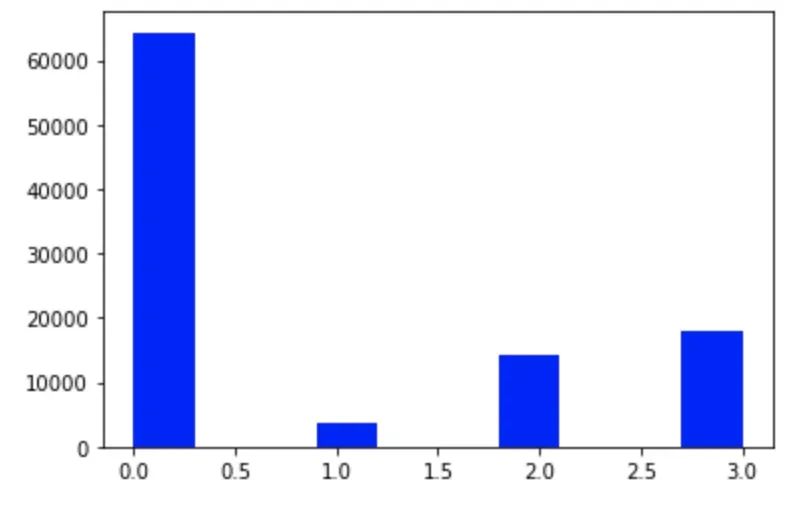
在Task02中,一定要留意「信号类别数据不平衡问题」。为什么要关注这个问题呢?因为「LGBM」本质上还是一颗决策树,决策树的分枝策略是基于「纯度」概念,这样就会对类别数量大的数据有偏爱。在这个问题中,我尝试「过采样」、「欠采样」、和「SMOTE」三种方法,最好的结果由「SMOTE」方法给出。我想是因为SMOTE产生新数据的方式是由「插值获取」(扩大了原有训练集样本取值范围),而不是简单的「重复取样」,所以SMOTE新数据更能接近心跳信号的样本空间分布(个人简单理解);而过采样和欠采样,并没有造成样本取值范围的改变,只是简单的伯努利随机取样;所以进行SMOTE平衡,会有较大的提高。
所以,提前了解所用模型(LGBM)&数据处理过程(SMOTE)的实现逻辑,然后在数据探索过程中留意潜在影响的因素(数据分布特征)对后续模型调参很重要。
Task03:特征工程(3天),打卡日期2021-03-23,特征工程做得好,模型调参轻松了!这个步骤如果想做得好,一定要求对数据特征有很好的认识。Tsfresh算法包可以提取时间序列特征(如由Datawhale成员分享出来的700+特征数据集),我后面也尝试了以这个数据集来做模型训练,但是结果很不好。主要原因有:(1)自己没有做好数据特征的刷选(目前了解到的方法不是很多);(2)在700+的数据特征中应该包含很多「无效特征」甚至是带来新噪声的特征。所以,在这部分我个人的想法是:基于自己对数据特点的理解,通过Tsfresh定向提取自己感兴趣的特征(如均值,方差等等),然后将这些特征作为新的数据列融合到原始数据中,获取新的训练数据(目前的想法,相关事情还在做的)。我觉得这种循序渐进的去考量一下自己感兴趣的特征量,才能让我在学习赛中提高更多。
Task04:建模与调参(3天),打卡日期2021-03-26,在Task04中主要介绍了:「贪心调参」、「网络搜索」和「贝叶斯调参」三种调参方式。根据我浅显的调参认知,这些调参方式应该都是进行一种「遍历操作」然后给出很多模型中最好的一组参数值。因为自己刚刚接触机器学习,参加的是学习赛。所以按照自己的习惯我还是主要进行「手动调参方式」,这种方式对我这样的初学者最大的好处是「属性模型中每个参数的含义」,而不是去盲目的设置一个不知所以然的参数范围,让计算机去跑。由于,学习赛的数据量很大,在我的电脑上运行一次就已经很费时间,所以上述3种调参方式我没有应用到学习赛数据中。但是我在SKlearn官网找了一组轻量数据集,尝试了“网络搜索”调参过程。因为第一次参加学习赛,我希望自己能多做一些「曲折的尝试」(手动调参),这样在后续建模与调参过程中,才能有更好的理解(主要是学习量太多,一时消化不完p.p)
Task05:模型融合(3天);打卡日期2021-03-29,这一块学习内容与Task05面临的问题基本一样,可以在Sklearn官网找到一些轻量的数据进行学习(鸢尾花数据集就很不错)。我最新提交的数据结果还是基于单一的「LGBM」模型,在这个模型中重点考虑:K折值、学习率、bagging率、feature率、树的层数等等常见的参数。
总结
这是我第一次参加组队学习,也是第一次接触到机器学习(学习2个月p.p)。在「心跳信号分类学习赛」中,跟着大家的脚步一步一步学习下来让我收获很大。由一开始的「模型调参」,让我逐渐更加关心「数据特征」、「数据处理逻辑」、「模型的实现逻辑」等更加重要的问题点。截止到写这篇文章时,我的成绩是(没有达到自己设定目标:进入前10):
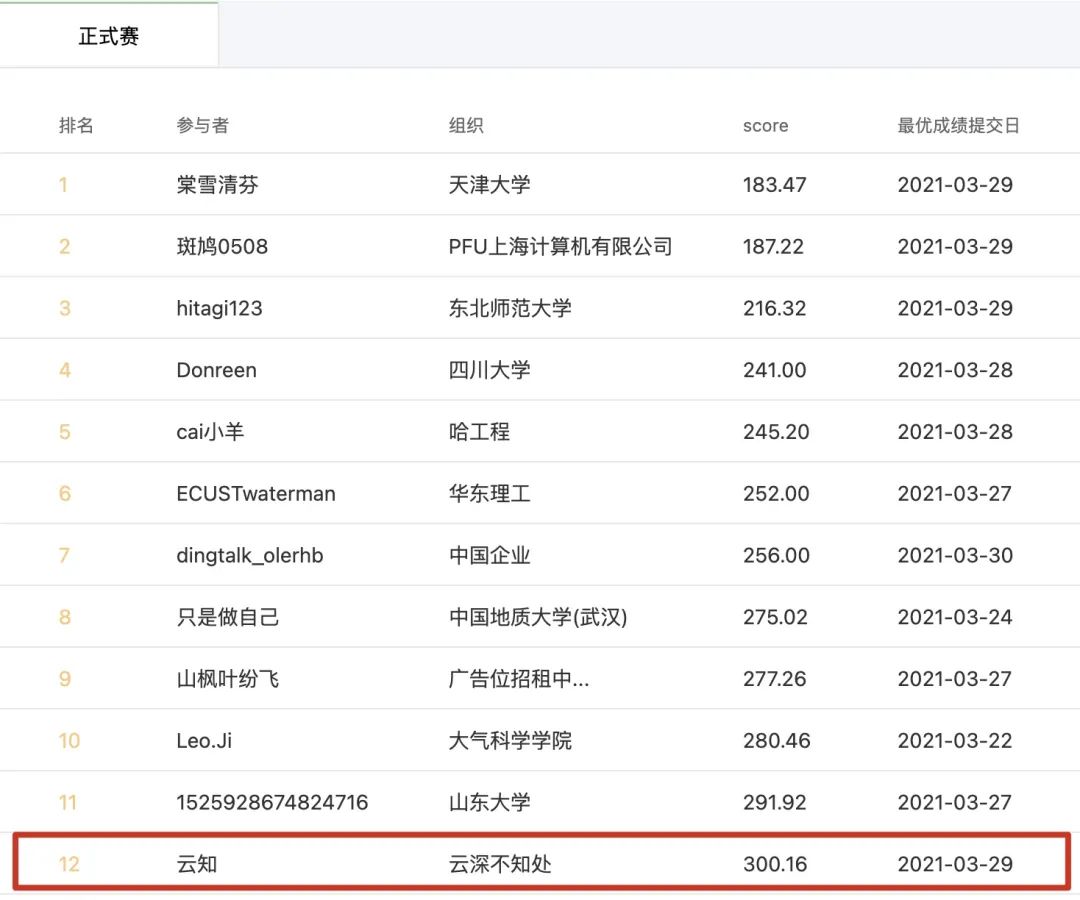
虽然,组织形式的学习活动结束了。但我后续还会将自己前面的一些想法加入到模型训练中,做更多的尝试、给自己一个更深刻的学习过程,努力进前10哈哈哈哈(心心念的前10)。
后记
这篇学习总结,即是对「组队学习」的总结,也是对「个人实习」的简单总结。现在我已经结束了实习,准备在自己喜欢的天文专业继续做一个鸵鸟。后续我还会继续参加更多有意思的比赛,学以致用,期待机器学习能在天文领域大放异彩。
最后还要特别谢谢我的队员们:
一个人可以走得很快,但一群人可以走的更远。愿我们都能在学习的过程中,享受到学习的乐趣。