
英伟达神秘「变形」GPU曝光!5nm工艺,两种形态随心变

新智元报道
新智元报道
编辑:小咸鱼 好困
【新智元导读】英伟达似乎把明年要发的新GPU提前自曝了!一个出现在论文里的神秘显卡GPU-N有着779TFLOPs的FP16性能,是A100的2.5倍。非常接近传闻中比A100强3倍的下一代Hopper GH100。

全新COPA-GPU架构

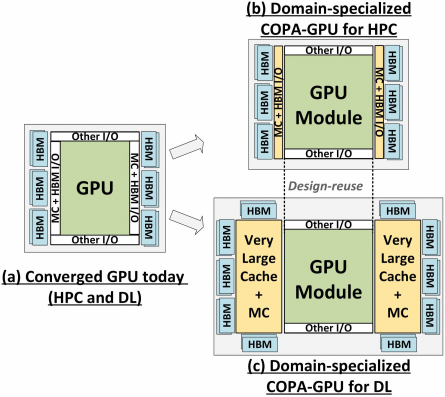
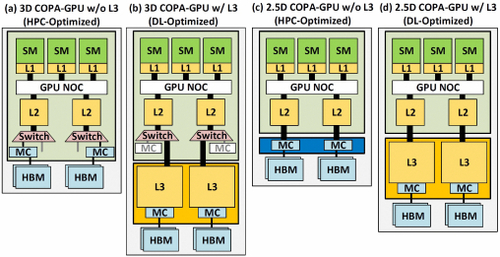
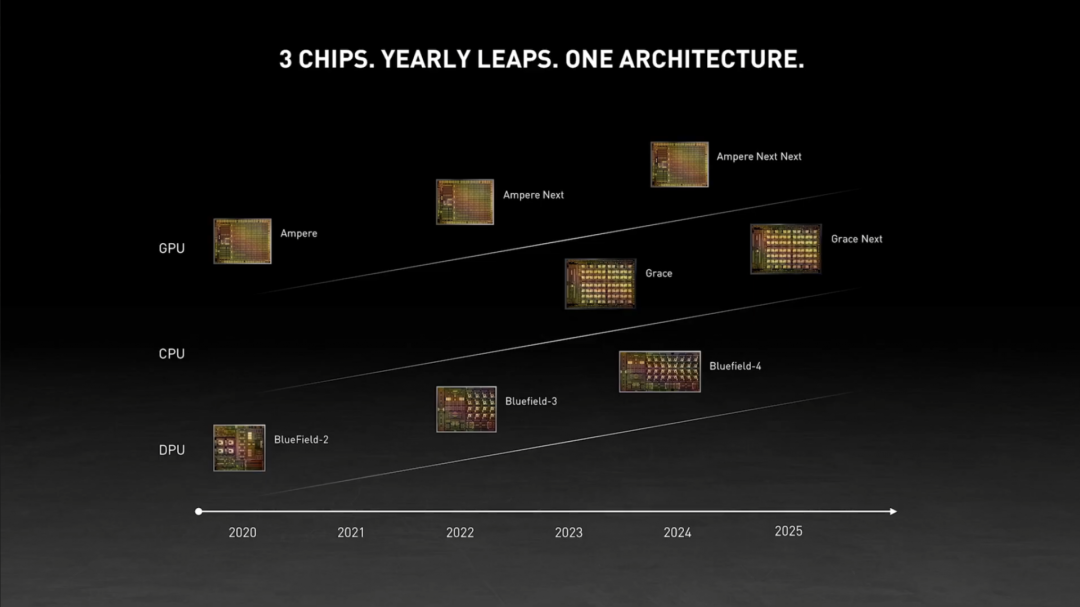
规格预测
参考资料:
https://wccftech.com/mysterious-nvidia-gpu-n-could-be-next-gen-hopper-gh100-in-disguise-with-134-sms-8576-cores-2-68-tb-s-bandwidth-simulated-performance-benchmarks-shown/

评论