如何用Python鉴别某宝商品是否存在刷单?
共
1732字,需浏览
4分钟
·
2019-12-08 23:31
 作者 | 小Z
作者 | 小Z
来源 | 数据不吹牛
起因:
发际线堪忧的小Q,为了守住头发最后的尊严,深入分析了几十款防脱洗发水的评价,最后综合选了一款他认为最完美的防脱洗发水。
一星期后,他没察觉到任何变化。
一个月后,他用卷尺量了量,发际线竟然后退了0.5cm!难道防脱要经历一个物极必反的过程,先脱再长?小Q不甘心,决定继续坚持。
两个月后,小Q心如死灰,忍不住和小Z抱怨。
!!!!!!
这句话,平地一惊雷,炸出了小Q惨痛的网购回忆。
他,屡屡冲着卖家秀而去,却屡屡化身买家秀而归。
说好的椰子!?
我想买两个杯子来着,怎么变成了一个!?

小Q曾经因为网购吃亏太多,而为自己的颜值和智商担忧。但经过小Z的点拨,他认定了一件事:活成卖家秀,并不是自身的问题,而是万恶的假评价误导了自己的消费决策。
为了自己,为了让更多的朋友免受误导,他和小Z一拍即合,决定用数据思维来鉴定刷单。
经过一番翻云覆雨,终于总结出了用数据鉴定刷单的两板斧。
 第一板斧:评销比
第一板斧:评销比
购买——使用——评价是一个完整的购后链路。消费者在购买了产品之后,一定会使用,但评价则需要一定场景来触发。
比如这个产品超出预期,我要感谢卖家!或者这个产品在侮辱我的智商,我要骂街!
当然,还存在一部分为了刷积分而评价的人,不过正常情况下,主动评论的人占总人数的比重是维持在稳定水平的。

如果有通过大规模红包返现或其他人为手段刷的好评,在同样购买人数的前提下,参与评价的人大概率是高于正常的。
怎么衡量这个比例是否合理呢?这里,我们引入一个叫做评销比的指标。
评销比 = 单款产品总评论数 / 单款产品总销量 * 100,以此来衡量平均每卖出100单位的产品,对应着多少条评价。
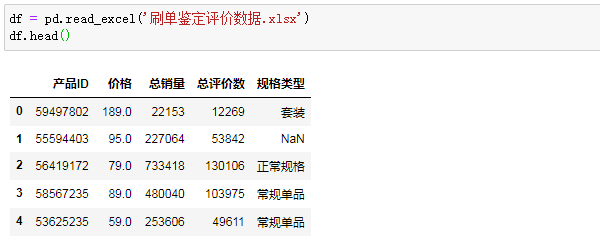
接下来,我们导入爬取的脱敏真实数据(为了去重广告嫌疑脱的敏)来实践一下:
增加一列计算评销比:
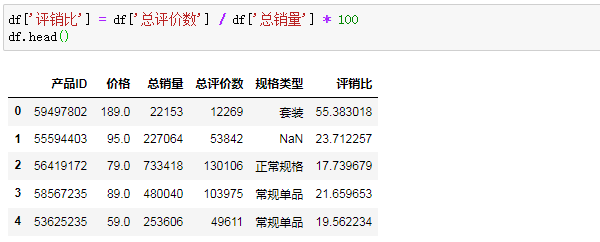
看看评销比分布形态,数据在20左右分散开来,略微偏右:
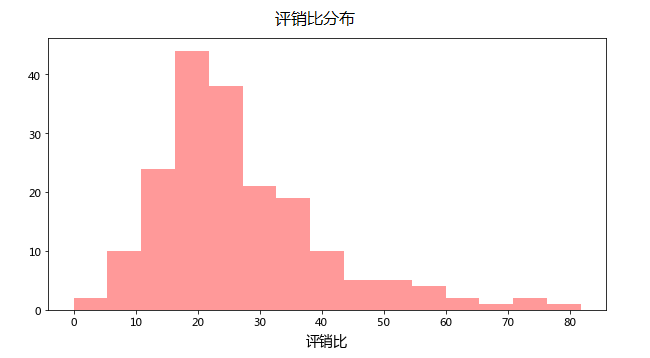
从评销比分布图,可以看出在40处有二次下跌,我们暂且把40(一般也可以尝试平均值)设置为一个筛选阈值,高于阈值的判定为有刷单嫌疑。

第一版斧挥过,12%疑似刷单的产品应声倒下,小Z露出了欣慰的微笑。
小Q却眉头紧锁:“这个鉴定逻辑是有一定道理,但是,我买的那款洗发水竟然逃过了筛选!”
不要慌,我们还有第二板斧保驾护航。
 第二板斧:内容重复度
第二板斧:内容重复度
第二板斧整个判别逻辑极其简单粗暴:对于一款产品,如果存在不同的用户,在不同的时间,评论了相同的内容,那妥妥的是刷啊!
直接上案例数据,我们爬取了小Q购买的那款防脱洗发水评价,共计1706条:

为了让鉴别更加科学,先换位思考:除极端情绪外,我们自己在评论时总会用“还行”、“一般般”、“刚收到,还没用”等短评来敷衍。这些短评非常容易重复,但也不能说是刷的评价。
so,我们在用重复度鉴别时,可以先预设一个评论长度作为筛选标准,比如只对超过15个字的评论进行重复度匹配:
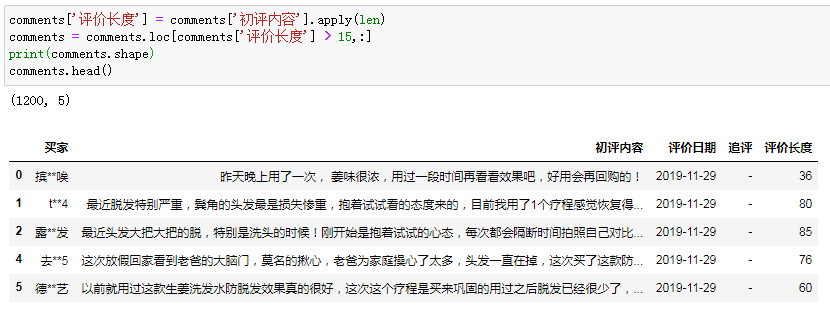
长度筛选之后,正好还剩下1200条评价,下面开始正式匹配。大家如果想更精细,可以考虑用文本挖掘等高阶方法,在这里我们用最最最简单粗暴的文本排序:

前6条评价,有3个不同的客户,分别在19年的10月16日、24日和21日发表了相同的内容,他们都受高考压力影响,脱发严重,每天房间、床铺、地上掉满他们的头发。
幸好!!!他们在秃顶前遇到了这款洗发水!用了几次不仅比之前掉的少,还新长出来了一些小碎发!

177个字,洋洋洒洒,令人动容!
但这到底是偶然的巧合还是有组织刷的评价呢?我们不能这么简单下定论。
继续看一看,这些长篇大论一字不差的重复评论有多少条:注:A,B,C三条内容完全一样,则统计为3条重复评价

1200条超过15个字的评价,有378条是虚伪的,占比高达31.5%。
他们文风多变,除了“高考压力”,还有“为父分忧而买”、也有“被微博广告安利”、甚至有“担心被骗,用第二套才敢评价的”。
可谓情真而意切,感人而至深!
小Z看过评价,深深不能自拔,瞬间理解了小Q为什么被忽悠。
“你跺你也麻啊!”
幸好,以后有了这两板斧保驾护航,再也不用担心这些虚评假意了。
注:文章所涉及所有源数据和代码,已上传至github(或点击阅读原文)https://github.com/seizeeveryday/DA-cases/tree/master/Comments
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报
 下载APP
下载APP