
从输入 URL 到展现涉及哪些缓存环节(非常详细)
前言
缓存是一项用来提高网站性能不可或缺的技术,利用这项技术可以很好地提高 web 的性能。缓存可以很有效地降低网络的时延,同时也会减少大量请求对于服务器的压力。大家在继续看下去之前可以先思考一下 “从输入 URL 到页面加载完成的过程中都发生了什么事情”。你现在所看到的其实就是这个热点问题的一个变种问题。
不过这个问题对缓存会有一个更详尽的解释。我相信你看完这篇文章后对缓存会有一个全新的认识,如果没有那就再看一遍。
入题
在这篇文章,我会详尽的描述从输入 URL 到展现涉及到的缓存环节,不过由于本人知识有限,很可能有某些隐藏的缓存机制在下遗漏了,还请大佬不吝赐教。
在讲“从输入 URL 到展现涉及到的缓存环节”之前,我们先了解下缓存的优点:
缓存的几个优点
减少冗余的数据传输,可节省流量
缓解带宽瓶颈问题,可更快加载页面
缓解瞬间拥塞,可缓解原始服务器的压力
降低距离延时,加快响应速度
目录
地址栏网址缓存
检查 HSTS 预加载列表
DNS 缓存
ARP(地址解析协议)缓存
TCP 发送缓冲区 & 接收缓冲区
HTTP 请求缓存( CDN 节点缓存、代理服务器缓存、浏览器缓存、后端动态计算结果缓存等 )
接下来我们进入正题(带着答案,口味更佳):
一、地址栏网址缓存
输入 url 后遇到的第一个缓存环节就是地址栏网址缓存。
但我们输入一个常用的网址时,经常会有这样的情况,我们只是输入了几个字母,浏览器就自动补全了该网址。如下图:我只输入 j,就自动给我补全了 juejin.im:

当我们使用这个自动补全的网址时,你会发现请求的相关的静态资源也是从缓存中取得的。
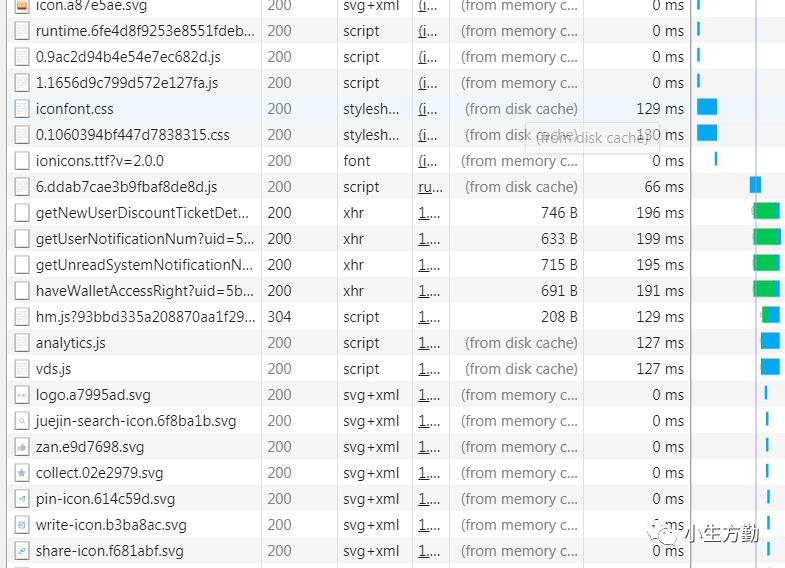
注意:不论什么时候,我们获取的主页面资源 timeline, 都应该是重新请求服务器而获得的,不可以使用本地浏览器的缓存。至于为什么?你看到静态资源文件名的 hash 值你就应该清楚了。
可以在 Chrome 的地址栏中输入 Chrome://cache 查看缓存的信息
转换非 ASCII 的 Unicode 字符
浏览器检查输入是否含有不是 a-z,A-Z,0-9,- 或者 . 的字符;如果有的话,浏览器会对主机名部分使用 Punycode 编码
二、检查 HSTS 预加载列表
HSTS( HTTP Strict Transport Security )国际互联网工程组织 IETE 正在推行一种新的 Web 安全协议,作用是强制客户端(如浏览器)使用 HTTPS 与服务器创建连接。
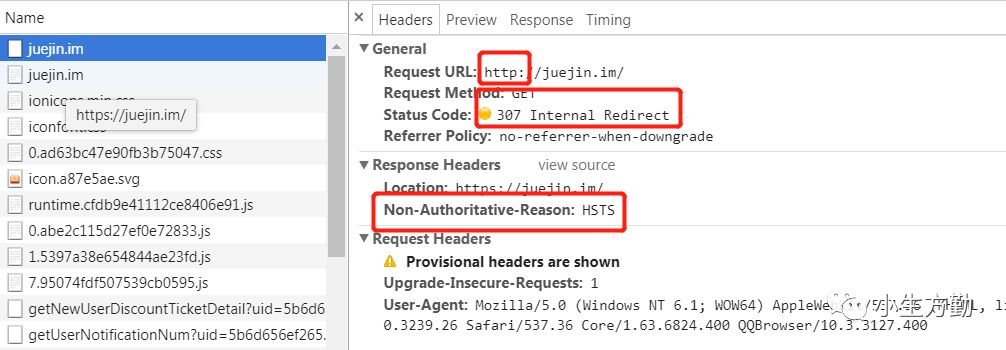
采用 HSTS 后:支持这个协议的浏览器,在输入 URL 后会检查自带的 HSTS 预加载列表(这个列表里包含了那些请求浏览器只使用 HTTPS 进行连接的域名),若网站在这个列表里,浏览器会使用 HTTPS 协议并且返回码为 307。而不支持 HSTS 的浏览器访问我们的网站,则不会产生跳转,从而提高了兼容性。这个机制对于不支持 HTTPS 的搜索引擎来说是非常友好的!
如掘金输入 http://juejin.im/timeline 会跳转到 https://juejin.im/timeline:

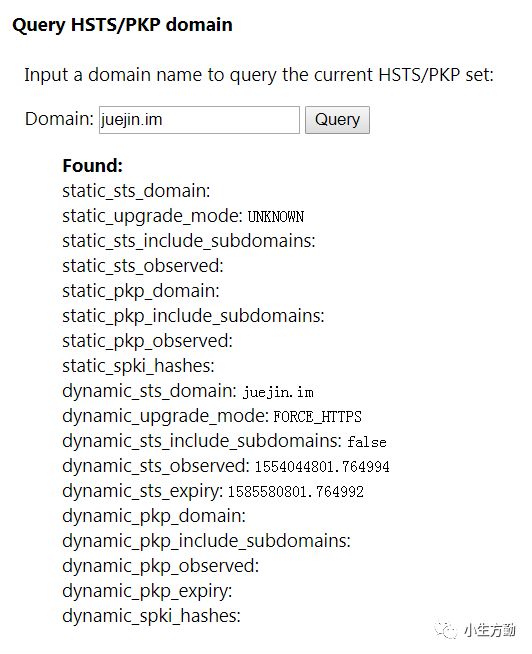
查看 HSTS 预加载列表是否存在你想访问的域名你可以在输入 qqbrowser://net-internals/#hsts,若存在会返回信息:
三、DNS 缓存
但你输入 juejin.im 按下回车后,就开始对 juejin.im 进行域名解析。域名解析最少涉及了三个地方的缓存:
浏览器的 DNS 缓存
操作系统中的 DNS 缓存
索操作系统的 hosts 文件(可手动写入的缓存)
域名解析的具体过程
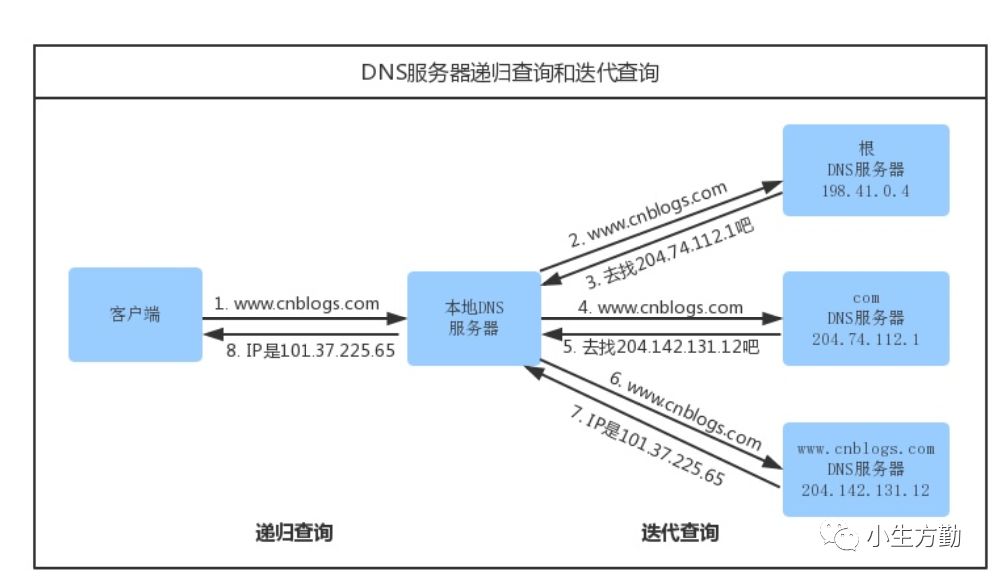
浏览器搜索自己的 DNS 缓存(浏览器维护一张域名与 IP 地址的对应表);如果没有命中,进入下一步;
搜索操作系统中的 DNS 缓存;如果没有命中,进入下一步;
搜索操作系统的 hosts 文件( Windows 环境下,维护一张域名与 IP 地址的对应表);如果没有命中,进入下一步;
操作系统将域名发送至 LDNS (本地区域名服务器),LDNS 查询自己的 DNS 缓存(一般命中率在 80% 左右),查找成功则返回结果,失败则发起一个迭代 DNS 解析请求:
LDNS向 Root Name Server(根域名服务器,如com、net、im 等的顶级域名服务器的地址)发起请求,此处,Root Name Server 返回 im 域的顶级域名服务器的地址;
LDNS 向 im 域的顶级域名服务器发起请求,返回 juejin.im 域名服务器地址;
LDNS 向 juejin.im 域名服务器发起请求,得到 juejin.im 的 IP 地址;
LDNS 将得到的 IP 地址返回给操作系统,同时自己也将 IP 地址缓存起来;操作系统将 IP 地址返回给浏览器,同时自己也将 IP 地址缓存起来。
DNS Prefetch
即 DNS 预获取,是前端优化的一部分。一般来说,在前端优化中与 DNS 有关的有两点:
减少 DNS 的请求次数
进行 DNS 预获取
典型的一次 DNS 解析需要耗费 20-120 毫秒,减少DNS解析时间和次数是个很好的优化方式。DNS Prefetching 是让具有此属性的域名不需要用户点击链接就在后台解析,而域名解析和内容载入是串行的网络操作,所以这个方式能减少用户的等待时间,提升用户体验。
你可以通过
chrome://net-internals/#dns查找目前系统中的 DNS 缓存和 Chrome 中使用的情况。
提个问题
问:浏览器 DNS 缓存的时间一般不会太长,一分钟左右。为什么缓存不设置较长时间呢?
答:虽然 DNS 缓存可以提高获取 DNS 的速度,但缓存时间过长也会影响 DNS 在 IP 变更时不能及时解析到最新的 IP。
四、ARP(地址解析协议)缓存
ARP 是一种用以解释地址的协议,根据通信方的 IP 地址就可以反查出对应方的 MAC 地址。
ARP 缓存是个用来储存 IP 地址和 MAC 地址的缓冲区,其本质就是一个 IP 地址与 MAC 地址的对应表,表中每一个条目分别记录了其他主机的 IP 地址和对应的 MAC 地址。
当地址解析协议被询问一个已知 IP 地址节点的 MAC 地址时,先在 AR 缓存中查看,若存在,就直接返回与之对应的MAC地址;若不存在,才发送 ARP 请求查询。
具体的 ARP 请求查询感兴趣的同学可以自行研究。
五、TCP 发送缓冲区 & 接收缓冲区
建立 TCP 连接这一步也涉及到缓存 —— 用来临时存放双方通信的数据,保证通信数据不会丢包。
每个 TCP 连接在内核中都有一个发送缓冲区和接收缓冲区,TCP 的全双工的工作模式以及 TCP 的流量(拥塞)控制便是依赖于这两个独立的 buffer 以及 buffer 的填充状态。
发送缓冲区
发送缓冲区存放的是
send()方法从应用缓冲区拷贝过来的数据。
内核基本上是按照 MSS(Maximum Segment Size,最大报文段长度) 从缓冲区中取数据发送出去,当缓冲区中数据小于 MSS,则将剩余数据全部发送出去。TCP 的发送缓冲区必须为已发送的数据保留一个副本,直到它被对端确认为止,才能从缓冲区中删掉已确认的数据。
接收缓冲区
接收缓冲区被 TCP 用来保存接收到的数据,直到应用程序来读取。
接收缓冲区把数据缓存入内核,等待 recv() 方法读取, recv() 方法所做的工作,就是把内核缓冲区中的数据拷贝到应用层用户的 buffer 里面,拷贝后就删掉已确认的数据。
流控制(Flow Control)
A mechanism to prevent a TCP sender from overwhelming a TCP receiver.
TCP 流控制主要用于匹配发送端和接收端的速度,即根据接收端当前的接收能力来调整发送端的发送速度。
由于发送速度可能大于接收速度,接收端的应用程序未能及时从接收缓冲区读取数据,接收缓冲区不够大不能缓存所有接收到的报文等原因,TCP接收端的接收缓冲区很快就会被塞满;从而导致不能接收后续的数据,发送端此后发送数据是无效的,因此需要流控制。
TCP 的缓存就讲到这里,感兴趣的可以自己翻阅资料。
六、HTTP 请求缓存( CDN 节点缓存、代理服务器缓存、浏览器缓存、后端动态计算结果缓存等 )
在建立了 TCP 连接之后,就开始 HTTP 请求了;而 HTTP 缓存是优化性能不可忽视的一部分,这一部分我会着重讲解。
再讲具体过程之前,我再讲一遍强缓存和协商缓存。
强缓存 ( Cache-Control 和 Expires )
强缓存主要是采用响应头中的 Cache-Control 和 Expires 两个字段进行控制的。
其中
Expires是HTTP1.0中定义的,它指定了一个绝对的过期时期。而Cache-Control是HTTP1.1时出现的缓存控制字段。由于Expires是HTTP1.0时代的产物,因此设计之初就存在着一些缺陷,如果本地时间和服务器时间相差太大,就会导致缓存错乱。
这两个字段同时使用的时候 Cache-Control 的优先级会更高一点。
这两个字段的效果是类似的,客户端都会通过对比本地时间和服务器返回的生存时间来检测缓存是否可用。如果缓存没有超出它的生存时间,客户端就会直接采用本地的缓存。如果生存日期已经过了,这个缓存也就宣告失效。接着客户端将再次与服务器进行通信来验证这个缓存是否需要更新。
在请求头中使用 Cache-Control 时,它可选的值有:
| 指令 | 说明 |
|---|---|
| no-cache | 使用代理服务器的缓存之前提交原始服务器验证,验证通过才能使用 |
| no-store | 在客户端或是代理服务器都不缓存请求或响应的任何内容 |
| max-age=[秒] | 告知服务器客户端可接受资源的存在最大时间 |
| max-stale(=[秒]) | 可接受(代理服务器缓存的)过期资源,参数可省略 |
| min-fresh=[秒] | 可接受(代理服务器缓存的)资源更新时间小于指定时间 |
| no-transform | 代理服务器不可以更改媒体类型 |
| only-if-cached | 客户端只接受已缓存的响应,若缓存不命中,则返回 504 错误 |
| cache-extension | 自定义扩展值,若服务器不知别该指令,就直接忽略 |
在响应头中使用 Cache-Control 时,它可选的值有:
| 指令 | 说明 |
|---|---|
| public | 表明该资源可以给多个用户使用 |
| private(= name) | 该资源是私有资源,指定的用户可以使用的缓存 |
| no-cache | 强制每次请求直接发送给源服务器,而不经过本地缓存版本的校验。 |
| no-store | 在客户端或是代理服务器都不缓存请求或响应的任何内容 |
| no-transform | 代理服务器不可以更改媒体类型 |
| must-revalidate | 可缓存但必须再向源服务器进行请求确认 |
| proxy-revalidate | 要求缓存服务器返回缓存的时候向源服务器进行请求确认 |
| max-age=[秒] | 告知客户端该资源在规定时间内是新鲜的,无需向服务器确认 |
| s-maxage=[秒] | 告知缓存服务该资源在规定时间内是新鲜的,无需向服务器确认 |
| cache-extension | 自定义扩展值,若服务器不识别该指令,就直接忽略 |
可缓存性
public:响应可以被任何对象(客户端、代理服务器等)缓存private:只能被单个用户缓存,不能作为共享缓存no-cache:使用缓存副本之前,需要将请求提交给原始服务器进行验证,验证通过才可以使用only-if-cached:客户端只接受已缓存的响应,并且不向原始服务器检查是否有更新的拷贝
到期
max-age=<seconds>:缓存存储的最大周期,超过这个时间缓存被认为过期(单位秒)。与Expires相反,时间是相对于请求的时间s-maxage=<seconds>:覆盖max-age或者Expires头,但是仅适用于共享缓存(比如各个代理),并且私有缓存中它被忽略max-stale[=<seconds>]:表明客户端愿意接收一个已经过期的资源。可选的设置一个时间(单位秒),表示响应不能超过的过时时间min-fresh=<seconds>:表示客户端希望在指定的时间内获取最新的响应
重新验证和重新加载
must-revalidate:缓存必须在使用之前验证旧资源的状态,并且不可使用过期资源。proxy-revalidate:与must-revalidate作用相同,但它仅适用于共享缓存(例如代理),并被私有缓存忽略
其他
no-store:彻底得禁用缓冲,本地和代理服务器都不缓冲,每次都从服务器获取no-transform:不得对资源进行转换或转变。Content-Encoding,Content-Range,Content-Type等HTTP头不能由代理修改。
协商缓存 ( Last-Modified 和 Etag )
协商缓存机制下,浏览器需要向服务器去询问缓存的相关信息,进而判断是重新发起请求还是从本地获取缓存的资源。如果服务端提示缓存资源未改动( Not Modified ),资源会被重定向到浏览器缓存,这种情况下网络请求对应的状态码是
304。
*Last-Modified 和 If-Modified-Since *
基于资源在服务器修改时间而验证缓存的过期机制
当客户端再次请求该资源的时候,会在其请求头上附带上 If-Modified-Since 字段(值就是第一次获取请求资源时响应头中返回的 Last-Modified 值)。如果修改时间未改变则表明资源未过期,命中缓存,服务器就直接返回 304 状态码,客户端直接使用本地的资源。否则,服务器重新发送响应资源,从而保证资源的有效性。
Etag 和 If-None-Match
基于资源校验码(一般为md5值)而验证缓存的过期机制
当客户端再次请求该资源的时候,会在其请求头上附带上 If-None-Match 字段(值就是第一次获取请求资源时响应头中返回的 Etag 值),其值与服务器端资源文件的验证码进行对比,如果匹配成功直接返回 304 状态码,从浏览器本地缓存取资源文件。如果不匹配,服务器会把新的验证码放在请求头的 Etag 字段中,并且以 200 状态码返回资源。
需要注意的是当响应头中同时存在
Etag和Last-Modified的时候,会先对Etag进行比对,随后才是Last-Modified。
Etag 的问题
相同的资源,在两台服务器产生的 Etag 是不是相同的,所以对于使用服务器集群来处理请求的网站来说, Etag 的匹配概率会大幅降低。所在在这种情况下,使用 Etag 来处理缓存,反而会有更大的开销。
静态资源和动态资源的请求过程解析
静态资源
第一次请求肯定是从服务器请求过来的资源,这个没有什么疑问,我们先看看第一次请求的响应头的内容:
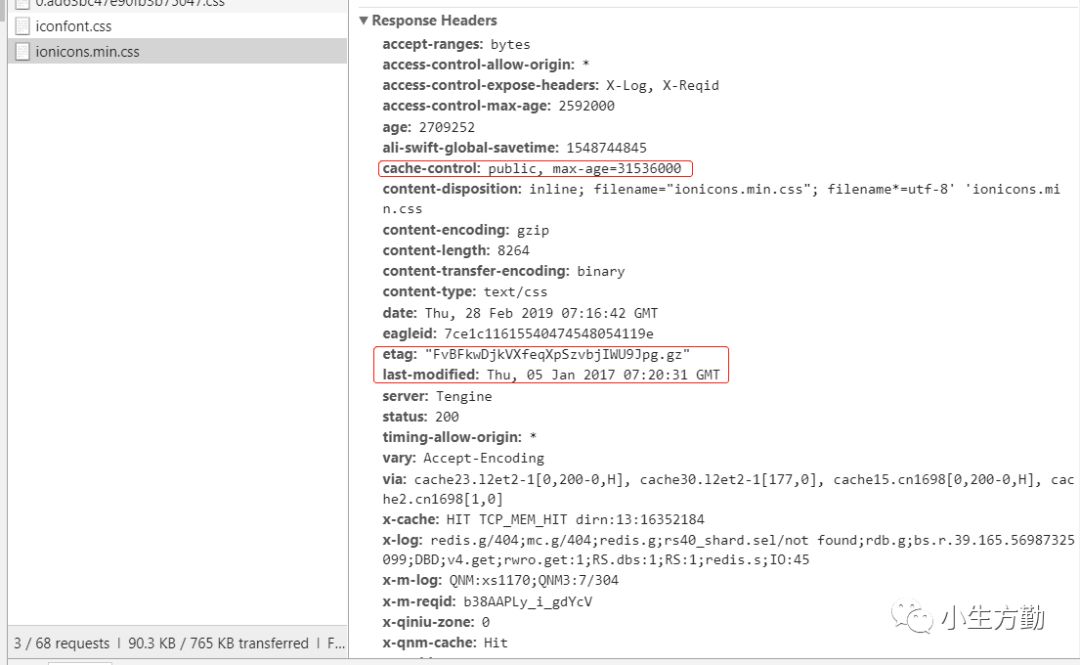
我们发现第一次的响应头中包含可强缓存的相关字段 cache-control ,同时也包含了协商缓存的相关字段 etag 和 last-modified;
当强缓存和协商缓存字段同时存在时会进行以下步骤来请求资源:
强缓存和协商缓存同时存在,如果强缓存还在有效期内则直接使用缓存;如果强缓存不在有效期,协商缓存生效。
即:强缓存优先级 > 协商缓存优先级强缓存的
expires和cache-control同时存在时,cache-control会覆盖expires的效果,expires无论有没有过期,都无效。
即:cache-control优先级 >expires优先级。协商缓存的
Etag和Last-Modified同时存在时,Etag会覆盖Last-Modified的效果。
即:ETag优先级 >Last-Modified优先级。
第二次请求该资源的时候,就直接是从缓存中读取的:

其实我们第一次获取的资源极有可能是从 CDN 节点的缓存中获取的,也很有可能是从中间代理服务器(nginx,node 等)的缓存中读取的;其中的好处不言而喻。
动态资源
由于动态资源的返回结果不一致,所以这个我们肯定不会在浏览器(中间代理服务器)缓存动态的结果。
不过这里我们可以在后端缓存一些重复率比较高的相关的计算结果。
如:这里有 60 只股票,用户可以选择其中几只股票作为自己的股票投资池。用户选择完股票后提交,会通过相关的算法计算其预期收益效果等指标。我们知道每次计算的时间可能会比较久,所以在这步我们可以在后端将可能的组合结果先计算好缓存起来,当我们请求的时候就后端就可以直接返回已经计算好的结果给前端。至于计算结果的缓存时间也就完全由服务器控制了。
关于动态资源一般前端是不做缓存的。
后端缓存主要通过保留数据库连接,存储处理结果等方式缩短处理时间,尽快响应客户端请求。