
伴鱼基于 Flink 构建数据集成平台的设计与实现
摘要:数据仓库有四个基本的特征:面向主题的、集成的、相对稳定的、反映历史变化的。其中数据集成是数据仓库构建的首要前提,指将多个分散的、异构的数据源整合在一起以便于后续的数据分析。将数据集成过程平台化,将极大提升数据开发人员的效率,本文主要内容为:
数据集成 VS 数据同步 集成需求 数据集成 V1 数据集成 V2 线上效果 总结
A data warehouse is a subject-oriented, integrated, nonvolatile, and time-variant collection of data in support of management’s decisions.
—— Bill Inmon
一、数据集成 VS 数据同步
「数据集成」特指面向数据仓库 ODS 层的数据同步过程; 「数据同步」面向的是一般化的 Source 到 Sink 的数据传输过程。

「数据同步平台」提供基础能力,不掺杂具体的业务逻辑。 「数据集成平台」是构建在「数据同步平台」之上的,除了将原始数据同步之外还包含了一些聚合的逻辑 (如通过数据库的日志数据对快照数据进行恢复,下文将会详细展开) 以及数仓规范相关的内容 (如数仓 ODS 层库表命名规范) 等。
二、集成需求
目前伴鱼内部数据的集成需求主要体现在三块:Stat Log (业务标准化日志或称统计日志)、TiDB 及 MongoDB。除此之外还有一些 Service Log、Nginx Log 等,此类不具备代表性不在本文介绍。另外,由于实时数仓正处于建设过程中,目前「数据集成平台」只涵盖离线数仓 (Hive)。
Stat Log:业务落盘的日志将由 FileBeat 组件收集至 Kafka。由于日志为 Append Only 类型, 因此 Stat Log 集成相对简单,只需将 Kafka 数据同步至 Hive 即可。 DB (TiDB、MongoDB):DB 数据相对麻烦,核心诉求是数仓中能够存在业务数据库的镜像,即存在业务数据库中某一时刻(天级 or 小时级)的数据快照,当然有时也有对数据变更过程的分析需求。因此 DB 数据集成需要将这两个方面都考虑进去。
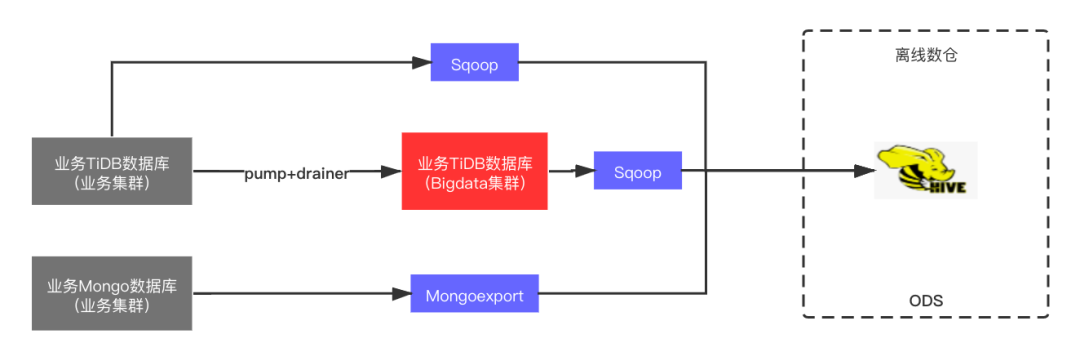
三、数据集成 V1
3.1 Stat Log

3.2 DB

四、数据集成 V2
4.1 Stat Log
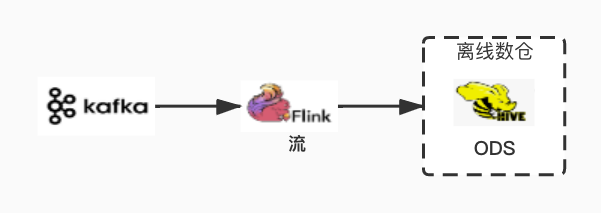
checkpoint: 10 min watermark: 1 min partition.time-extractor.kind: ‘custom’ sink.partition-commit.delay: ‘3600s’ sink.partition-commit.policy.kind: ‘metastore,success-file’ sink.partition-commit.trigger: ‘partition-time’
4.2 DB

用户提交集成任务后将同步创建三个任务:
增量任务 (流):「增量任务」将 DB 日志数据由 Kafka 同步至 Hive。由于采集组件都是按照集群粒度进行采集,且集群数量有限,目前都是手动的方式将同步的任务在「实时计算平台」创建,集成任务创建时默认假定同步任务已经 ready,待「数据同步平台」落地后可以同步做更多的自动化操作和校验。 存量任务 (批):要想还原出快照数据则至少需要一份初始的快照数据,因此「存量任务」的目的是从业务数据库拉取集成时数据的初始快照数据。 Merge 任务 (批):「Merge 任务」将存量数据和增量数据进行聚合以还原快照数据。还原后的快照数据可作为下一日的存量,因此「存量任务」只需调度执行一次,获取初始快照数据即可。
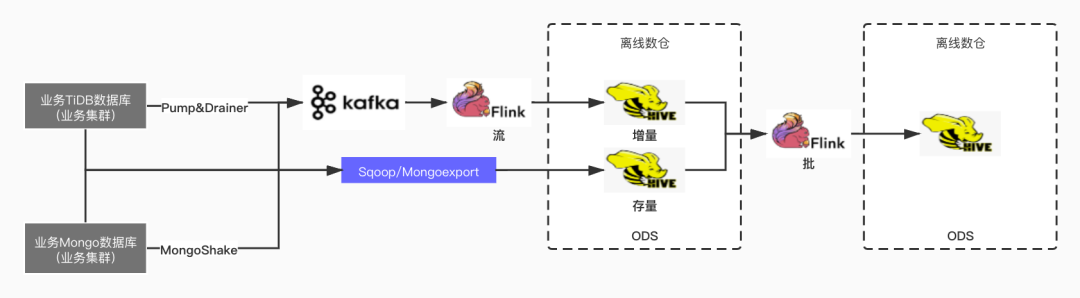
DB 的数据集成相较于 Stat Log 复杂性高,接下来以 TiDB 的数据集成为例讲述设计过程中的一些要点 (MongoDB 流程类似,区别在于存量同步工具及数据解析)。
■ 4.2.1 需求表达
TiDB 源信息:包括集群、库、表。 集成方式:集成方式表示的是快照数据的聚合粒度,包括全量和增量。全量表示需要将存量的快照数据与今日的增量日志数据聚合,而增量表示只需要将今日的增量日志数据聚合 (即便增量方式无需和存量的快照数据聚合,但初始存量的获取依旧是有必要的,具体的使用形式由数仓人员自行决定)。
■ 4.2.2 存量任务
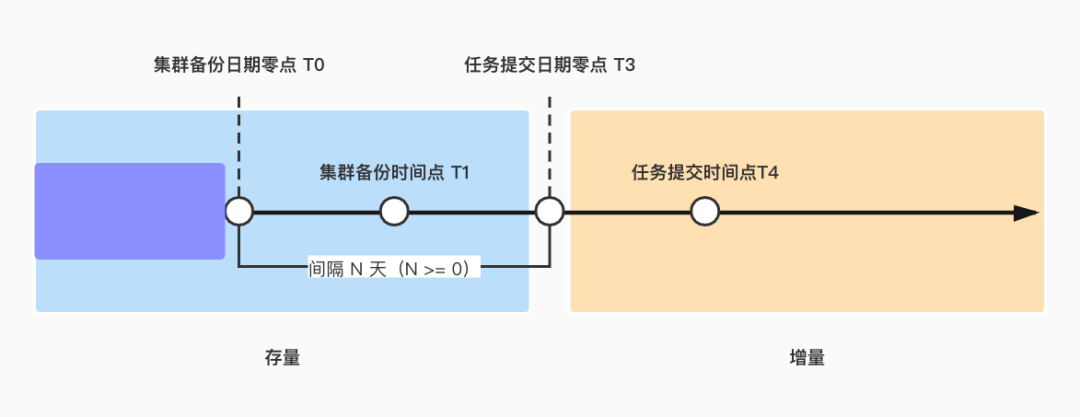

同步触发数据库平台进行备份恢复,产生回执 ID; 通过回执 ID 轮训备份恢复状态,恢复失败需要 DBA 定位异常,故将下线整个工作流,待恢复成功可在平台重新恢复执行「存量任务」。恢复进行中,工作流直接退出,借助 DS 定时调度等待下次唤醒。恢复成功,进入后续逻辑; 从恢复库中拉取存量,判定存量是否存在数据差,若存在则执行 Merge 任务的补数操作,整个操作可幂等执行,如若失败退出此次工作流,等待下次调度; 成功,下线整个工作流,任务完成。
■ 4.2.3 Merge 任务
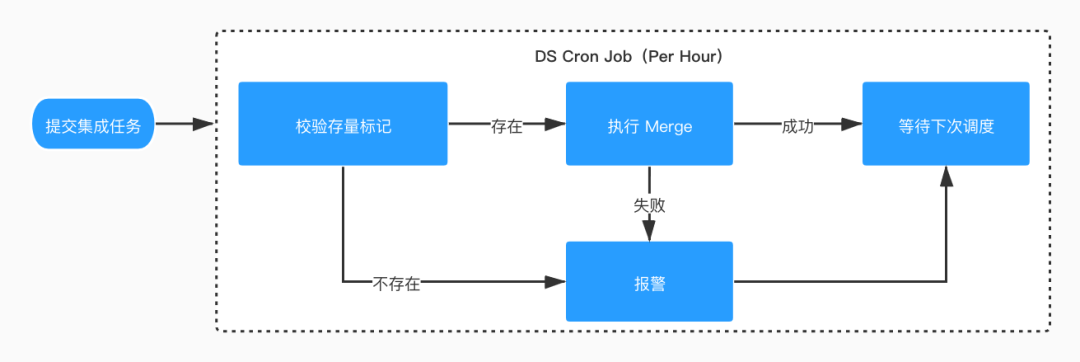
校验文件标记是否存在,若不存在说明数据未 ready ,进行报警并退出工作流等待下次调度; 执行 Merge 操作,失败报警并退出工作流等待下次调度; 成功,退出工作流等待下次调度。
加载存量、增量数据,统一数据格式(核心字段:主键 Key 作为同一条数据的聚合字段;CommitTs 标识 binlog 的提交时间,存量数据默认为 0 早于增量数据;OpType 标识数据操作类型,包括:Insert、Update、Delete,存量数据默认为 Insert 类型),将两份数据进行 union; 按照主键聚合; 保留聚合后 CommitTs 最大的数据条目,其余丢弃; 过滤 OpType 为 Delete 类型的数据条目; 输出聚合结果。
allMergedData.groupBy(x -> x.getKeyCols()).reduce(new ReduceFunction() { public MergeTransform reduce(MergeTransform value1, MergeTransform value2) throws Exception {if (value1.getCommitTS() > value2.getCommitTS()){return value1;}return value2;}}).filter(new FilterFunction() { //增量:过滤掉 op=delete public boolean filter(MergeTransform merge) throws Exception {if (merge.getOpType().equals(OPType.DELETE)){return false;}return true;}}).map(x -> x.getHiveColsText()).writeAsText(outPath);
■ 4.2.4 容错性与数据一致性保证
我们大体可以从三个任务故障场景下的处理方式来验证方案的容错性。
「存量任务」异常失败:通常是备份恢复失败导致,DS 任务将发送失败报警,因「数据库平台」暂不支持恢复重试,需人工介入处理。同时「Merge 任务」检测不到存量的 _SUCCESS 标记,工作流不会向后推进。 「增量任务」异常失败:Flink 自身的容错机制以及「实时计算平台」的外部检测机制保障「增量任务」的容错性。若在「Merge 任务」调度执行期间「增量任务」尚未恢复,将误以为该小时无增量数据跳过执行,此时相当于快照更新延迟(Merge 是将全天的增量数据与存量聚合,在之后的调度时间点如果「增量任务」恢复又可以聚合得到最新的快照),或者在「增量任务」恢复后可人为触发「Merge 任务」补数。 「Merge 任务」异常失败:任务具有幂等性,通过设置 DS 任务失败后的重试机制保障容错性,同时发送失败报警。
数据的一致性体现在 Merge 操作。两份数据聚合,从代码层面一定可以确保算法的正确性 (这是可验证的、可测试的),那么唯一可能导致数据不一致的情况出现在两份输入的数据上,即存量和增量,存在两种情况:
存量和增量数据有交叠:体现在初始存量与整点的增量数据聚合场景,由于算法天然的去重性可以保证数据的一致。 存量和增量数据有缺失:体现在增量数据的缺失上,而增量数据是由 Flink 将 Kafka 数据写入 Hive 的,这个过程中是有一定的可能性造成数据的不一致,即分区提交后的乱序数据。虽然说乱序数据到来后的下一次 checkpoint 时间点分区将再次提交,但下游任务一般是检测到首次分区提交就会触发执行,造成下游任务的数据不一致。
针对 Flink 流式写 Hive 过程中的乱序数据处理可以采取两种手段:
一是 Kafka 设置单分区,多分区是产生导致乱序的根因,通过避免多分区消除数据乱序。 二是报警补偿,乱序一旦产生流式任务是无法完全避免的 (可通过 watermark 设置乱序容忍时间,但终有一个界限),那么只能通过报警做事后补偿。
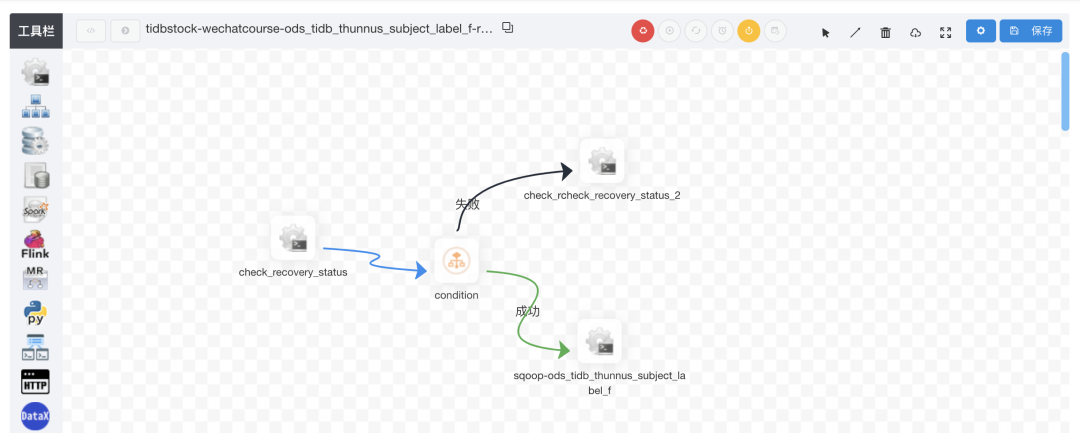
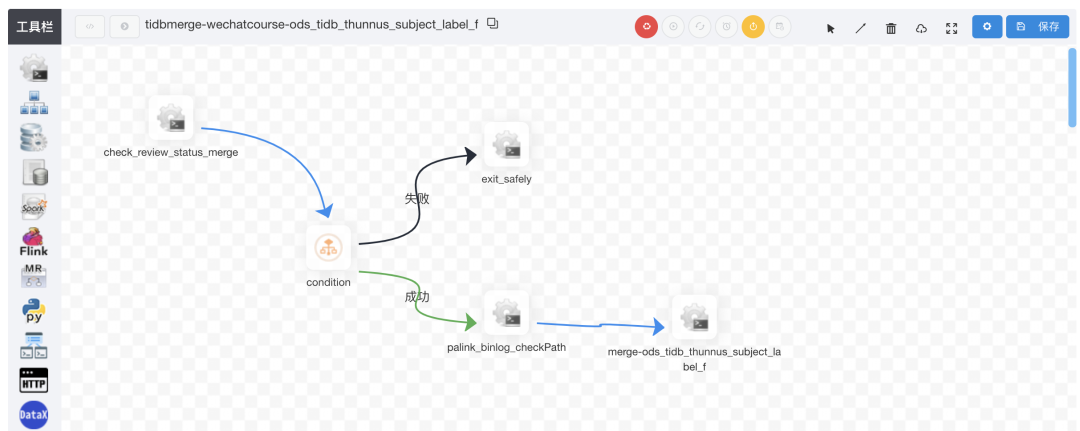
五、线上效果

六、总结
评论