
深度分析:4种国产CPU架构和6大品牌


前篇“国产基础软硬件:开源、迁移、上云,关键在生态”分享了国产基础软硬件发展策略,今天接着国产化话题,讲讲国产处理器。
国产 CPU 厂商得到了相应指令集的架构授权,发展成为6大主流厂商:龙芯、飞腾、鲲鹏、海光、申威、兆芯。CPU 的指令集分为复杂指令集(CISC)和精简指令集(RISC)两大类。复杂指令集以x86架构为代表,精简指令集则包括 ARM、MIPS、Alpha、Power 等。
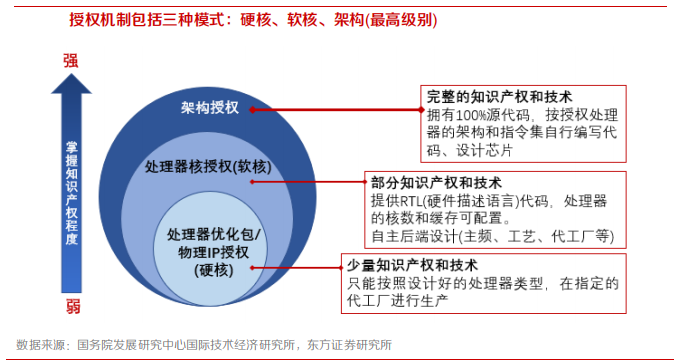
6 大主流 CPU 厂商的技术路线和生态建设各有优势。目前在通用计算领域,优势较强的是龙芯、飞腾、鲲鹏、海光这 4 大厂商,我们将在本章进行重点介绍。
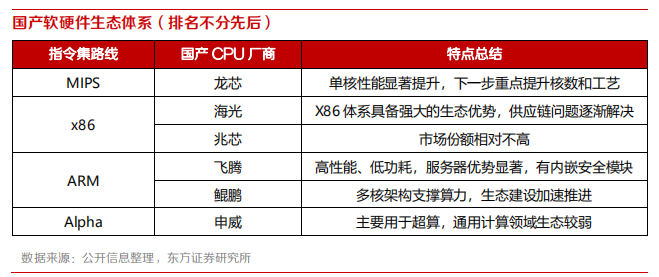
龙芯技术源于中科院计算产业,沿着市场化的道路不断发展,已有超过 20 多年的 CPU 行业积累。2001 年,在中科院计算所知识创新工程的支持下,龙芯课题组正式成立。2010 年,龙芯公司正式成立。龙芯坚持“市场带技术”的道路,而不是“市场换技术”的道路,坚持自主研发,坚持市场化的机制,整体的发展可概况为三个十年。
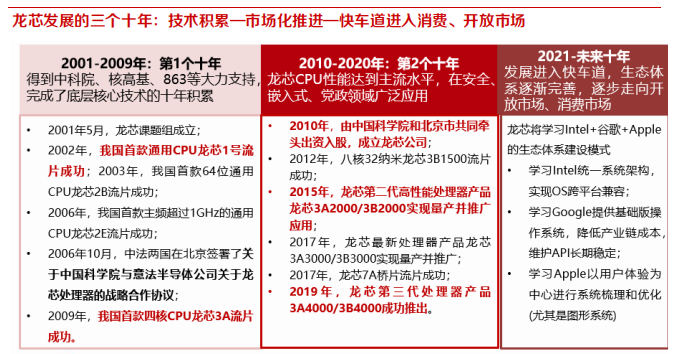
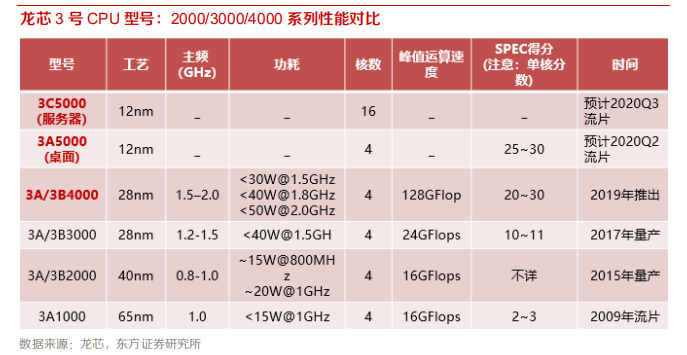
龙芯 CPU 系列包括龙芯 3 号大 CPU、 龙芯 2 号中 CPU 、龙芯 1 号小 CPU 三个系列,分别针对电脑(桌面和服务器)、工控和嵌入式、单片机领域。本章重点介绍用于桌面和服务器的龙芯3 号系列 CPU。
1)早期阶段(2015 年之前):性能较低,达不到“可用”程度:龙芯第一代 3A1000/3B1500 的单核性能较低,SPEC CPU 2006 分值只有 2-3 分,打开 20M 的测试文档需要 33 秒。
2)开始进入“可用”阶段(2016-2017 年):单核性能显著提升:龙芯第二代 3A3000/3B3000/7100 单核性能提升到 10-11 分,超过 Intel 凌动系列,打开 20M 的测试文档时间缩短为 6 秒。
3)“可用”向“好用”升级阶段(2019-2020):单核性能再次突破:龙芯第三代 3A/B4000、3A/C5000、7A2000 的单核性能提高到 20-30 分,打开 20M 的测试文档时间少于 1 秒。
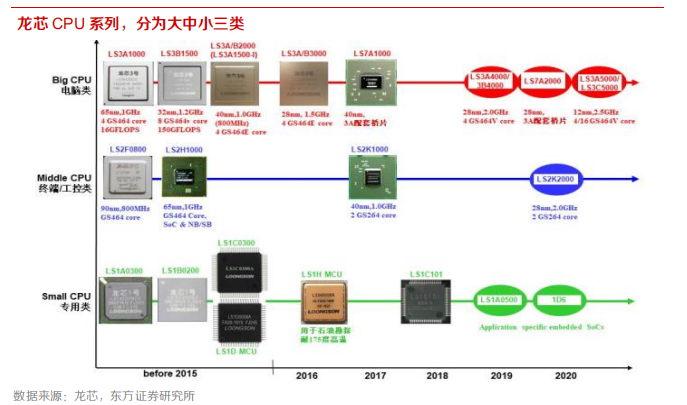
龙芯 3 号的更新升级有两种模式:
1)工艺更新微结构不变
2)工艺不变更新微结构。
龙芯 3A4000相比 3000,采用相同工艺(28nm)但性能成倍提高;龙芯 5000 系列工艺更新 12nm。龙芯 3 号 CPU 下一代 5000 系列的目标:提高主频和核数。龙芯新一代桌面芯片 3A5000 将在2020年Q2 流片,采用 12nm 工艺,单核性能提高至 25-30 分,与 3A4000 可原位替换,操作系统二进制兼容;龙芯服务器芯片 3C5000 预计于 2020 三季度流片,采用 12nm工艺,16 核结构,支持 4-16 路服务器。
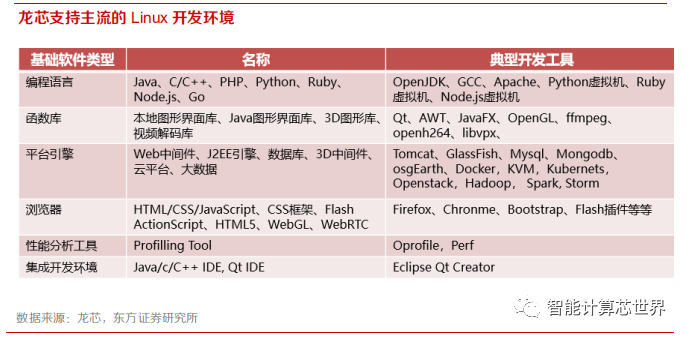
虽然从全球整体来看,MIPS 架构的生态基础相对 x86 和 ARM 较为薄弱,但龙芯的信创生态建设已经较为完善,而且处于不断扩张的发展中。龙芯非常重视 Linux 生态建设,为开源社区积极贡献代码,增强技术影响力。龙芯致力于 Linux 生态体系的兼容优化,有上百人规模的开源软件工程师团队,提供操作系统和底层软件兜底服务的能力。
2020 年 3 月 17 日,Java14f 发布,根据官方发布的统计,Oracle、红帽、SAP、龙芯和谷歌,位于 OpenJDK 代码提交次数的全球前五位。
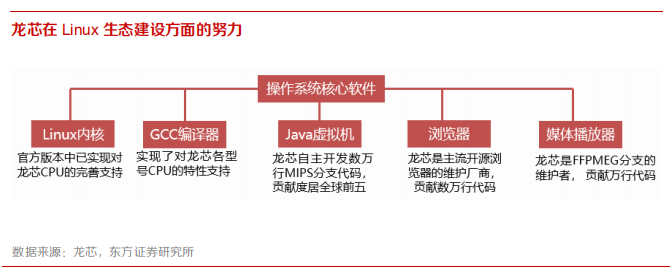
在应用开发环境建设方面,龙芯支持主流的 Linux 开发环境,包括多种编程语言、函数库、平台引擎和集成开发工具等。
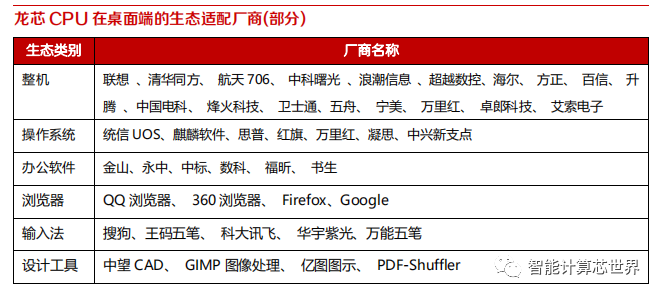
PC 端的生态建设:龙芯 CPU 已经支持主流的整机、操作系统、办公软件、浏览器、输入法和部分设计工具等常见软硬件,覆盖了基本的办公需求。
服务器生态领域:龙芯目前的 3B4000 服务器芯片是 4 核的,可以支持双路、 四路全相连结构,实现了虚拟机效率提升至 95%以上、跨片访存带宽提升至 400% 以上、内存数量线性扩展以及高吞吐率。目前也已经有百款厂商适配了龙芯的服务器 CPU。我们认为,龙芯新一代 16 核的服务器CPU 在 2020 年内流片之后,龙芯在服务器领域的市场影响力将进一步得到增强。
云计算生态领域:龙芯的 KVM 虚拟机于 2019 年 4 月发布,完善支持 OpenStack 集群管理工具,实现了从 CPU 到系统, 全链条虚拟机的自主研制。在云容器方面,龙芯的 Doker 容器于2017 年发布,完善支持集群管理工具 Swarm、 Kubernets、 Openshift、 Mesos 等。龙芯的云计算生态伙伴包括:浪潮云、 腾讯云、 金山云、 曙光云、 云栈希云、 中标易云、 道客云、航天科工天熠云、 UCLOUD、 CETC 电科云、 普华云、 升腾云、 金蝶云、江苏华云、 广西梯度云、 上海田亩云、 北京优炫云、 成都精灵云、 广东品高云,等等。
飞腾有 20 多年的 CPU 研制积累,背后依托中国电子信息产业集团(CEC)。2014 年,中国电子信息产业集团、天津滨海新区政府、天津先进技术研究院三方联合成立天津飞腾信息技术有限公司,致力于飞腾系列 CPU 的设计研发和产业推广。飞腾公司核心技术和研发团队来自国内顶尖高校,拥有 20 多年自主 CPU 研制经验。飞腾的芯片面向三大领域:服务器、PC 和嵌入式,本章重点介绍服务器和 PC 端的 CPU。
从技术路线角度,飞腾的发展经历了 2 个阶段:
1)早期:基于 SPARC 架构(1999-2012),生态建设受限。2000 年,飞腾第一款嵌入式 CPU 推出;2005 年,飞腾团队推出了 32 位、64 位的通用 CPU;2009 年推出第一款 8 核高性能 CPU, 2012 年飞腾 16 核高性能通用 CPU 推出。但整个 SPARC 架构生态日渐式微,也一定程度上影响了飞腾 CPU 的进一步推广。
2)新篇章:基于 ARM 架构(2014-至今),性能显著提升、生态建设顺利推进。2014 年飞腾基于ARM 架构的 FT-1500A 推出,性能相当于 Intel Xeon E3,从此开启了技术发展的新篇章。2017年,飞腾推出 64 核的 FT-2000+系列。2019 年,飞腾桌面版 FT-2000/4 问世,采用 16nm 工艺,性能相当于 Intel Core i3 系列。

飞腾新一代的 CPU 实现了性能的显著提升:在桌面领域:飞腾新一代的 FT-2000/4 较上一代 FT-1500A/4 计算性能提升了 1 倍,功耗方面降低 33%。FT-2000/4 还可以通过“降频”、“减核”的方式,在能源、交通、化工、金融等关键领域实现嵌入式低功耗终端应用。在服务器领域:飞腾新一代的服务器芯片 FT-2000+/64 较上一代 FT-1500A/16 计算性能提升 5.5 倍,单位功耗算力提升近 2 倍,是更加高效更加绿色的芯片。
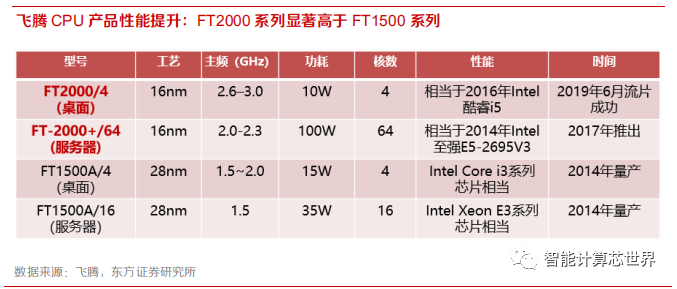
飞腾基于 ARM V8 架构的服务器 CPU,相比 x86 架构的海外厂商产品,优势在于多核处理能力和功耗上面。在 2019 年的某项目中,4 台基于飞腾 FT-2000+/64(64 核,16nm)的单路服务器和 4 台搭载英特尔至强 E5-2650V4(12 核,14nm)的双路服务器在大数据方面进行了对比测试。在 Storm测试中,飞腾的各项测试均相当或占优。
在离线计算 Spark 测试中,飞腾得益于其多核处理能力,也实现了性能占优;在消息队列 Kafka 测试中,飞腾的性能和 x86 服务器基本相当。飞腾的功耗仅仅为对方的 50%。体现出了飞腾对大数据组件,尤其对离线计算的良好支持,也体现了飞腾 CPU的节能。
针对云计算平台的虚拟化方面,飞腾服务器芯片提供了较好的硬件辅助虚拟化支持。在FT2000+/64 服务器上对比了虚拟机双核(采用 KVM 虚拟化)和宿主机双核在基准测试中的效率比值,平均约为 97.5%左右,这为基于 KVM 虚拟化的云平台性能提供了强有力的支撑。
生态建设:飞腾通过性能强大、低功耗的桌面 CPU,构建了终端全栈生态。终端全栈架构包括硬件层,固件、操作系统及驱动层和应用层。
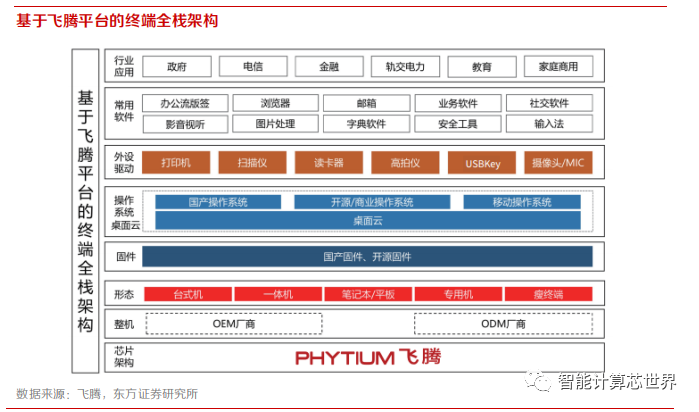
飞腾软硬件生态圈:飞腾联合了近 1000 家国内的软件/硬件厂商,支持超过 300 款服务器、30 多款整机、40 多款便携笔记本、20 多款存储设备。
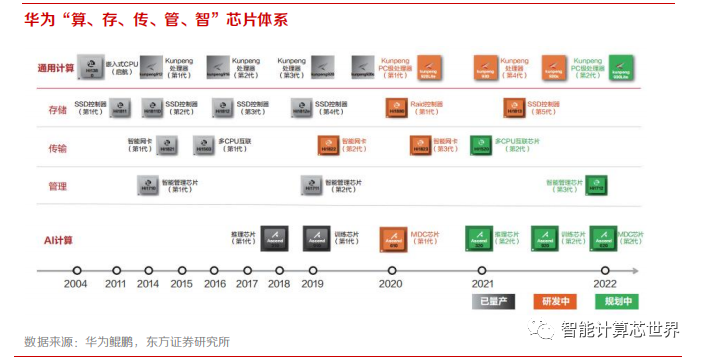
鲲鹏处理器基于 Armv8 架构永久授权,处理器核、微架构和芯片均由华为自主研发设计,鲲鹏计算产业兼容全球 Arm 生态。除了传统的服务器 CPU 和桌面 CPU,华为围绕鲲鹏处理器打造了“算、存、传、管、智”五个子系统的芯片族。历经 10 多年,目前已累计投入超过 2 万名工程师。
在通用计算领域,鲲鹏 CPU 目前主要集中在服务器领域。鲲鹏 920 服务器 CPU 基于 ARM V8 多核架构,最高集成 64 个物理核,主频最高 2.6GHz,通过多核来提升算力。另外,华为鲲鹏 PC 级 的 CPU 也在规划中。
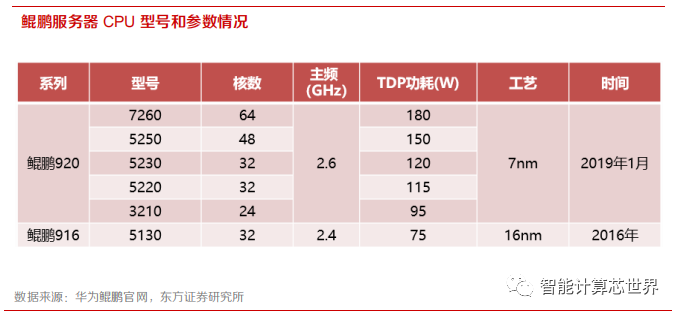
根据华为开发者大会 2020(cloud)公布的数据,相比英特尔 Skylake 服务器 CPU,华为鲲鹏 920 系列芯片的性能更高,功耗更低,主要得益于鲲鹏 920 的工艺升级到了 7nm,内核数量更多,而且进行了多核优化处理。
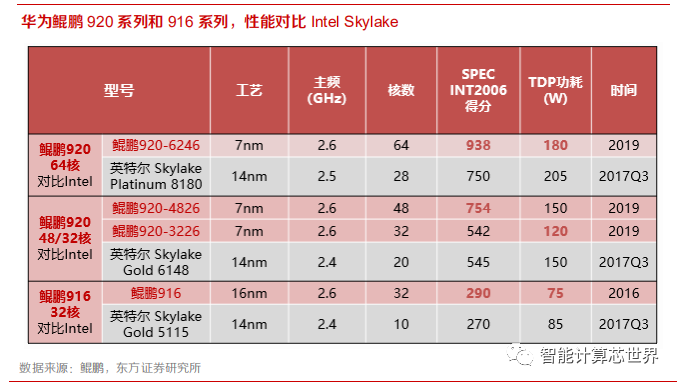
华为推出了基于鲲鹏 CPU 的泰山服务器系列,包含多个种类。根据华为 2019 年的生态大会公布的信息,华为未来将重点聚焦于算力的上游,进行生态伙伴赋能,未来有可能逐渐退出服务器整机领域。我们认为,随着华为生态建设的逐步完善和厂商对鲲鹏 CPU 接受度进一步提高,华为鲲鹏CPU 未来有望不依赖于华为自己的服务器整机进行推广,从而实现战略升维。

在 AI 算力方面,华为提供昇腾 AI 处理器和 Atlas 平台。昇腾系列包括 310 和 910 两款,均采用华为自研的达芬奇架构。昇腾 310 定位是高效、灵活、可编程的 AI 处理器,功耗仅 8W,八位整数精度(INT8)性能达到 16TOPS,16 位浮点数(FP16)性能达到 8 TFLOPS;昇腾 910 定位为超高算力的 AI 处理器,其最大功耗为310W,八位整数精度(INT8)下的性能达到 512TOPS,16位浮点数(FP16)下的性能达到 256 TFLOPS。
作为一款高集成度的片上系统(SoC),除了基于达芬奇架构的 AI 核外,昇腾 910 还集成了多个 CPU、DVPP 和任务调度器,具有自我管理能力,可以充分发挥其高算力的优势。昇腾 910 集成了 HCCS、PCIe 4.0 和 RoCE v2 接口,为构建横向扩展(Scale Out)和纵向扩展(Scale Up)系统提供了灵活高效的方法。HCCS 是华为自研的高速互联接口,片内 RoCE 可用于节点间直接互联,最新的 PCIe 4.0 的吞吐量比上一代提升一倍。华为 Atlas 平台是搭载昇腾处理器相关的服务器、边缘计算小站、AI 集群等。
鲲鹏生态加速推进:华为聚焦于架构和并发,提供算力;硬件开放、软件开源、支持迁移和生态伙伴共建生态。在华为开发者大会 2020(Cloud)上,华为宣布“沃土计划 2.0” ,将在 2020 年投入 2 亿美元推动鲲鹏计算产业发展,并公布面向高校、初创企业、开发人员及合作伙伴的扶持细则。

华为携手腾讯游戏启动在鲲鹏领域的全面合作,并与麒麟软件、普华基础软件、统信软件、中科院软件所共同宣布基于 openEuler 的商用版本操作系统正式发布,加速鲲鹏生态在各行业落地。
海光(Hygon)获得 AMD x86 授权:2016 年,为应对危机,AMD 成立了天津海光来授权 x86 芯片的设计,由此获得 2.93 亿美元现金。天津海光成立了成都海光微电子和成都海光集成电路公司。AMD 分别拥有海光微电子股份 51%和海光集成电路 30%的股份。海光微电子由 AMD 持有大多数控股,因此被授权使用 x86 的设计。
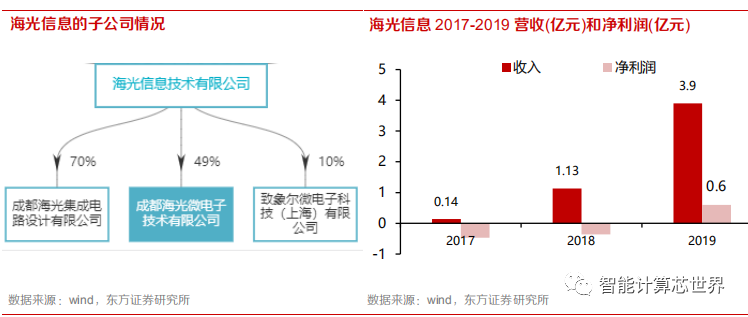
2019 年,海光进入实体清单,产业链一度受到影响,但恢复程度有望超预期。依托中科曙光、中科院的雄厚的研发实力,从长期来看,海光具备吸收先进的技术并做出自主改进和升级的能力,供应链的影响逐步减弱。在半导体生产线全球化布局的大背景下,公司通过全面梳理供应链,积极寻找可替代部件,也和部分上游企业进行了积极沟通,以促进交易恢复。公司供应链运营方面取得了实质性进展,已经形成了相对完整的应对方案,能够保持公司供应链平稳运行。可以看到,掌握先进制程工艺的厂商已经有三星、中芯国际、台积电等厂商。

海光在吸收了 AMD 的技术的基础上,凭借 x86 的生态和性能优势,依托中科院、中科曙光的研发实力支撑,通过整合供应链资源,有望在 2020 年实现市场份额的进一步突破。
完整内容参考《国产基础软硬件:开源、迁移、上云,关键在生态》内容如下,下载链接:国产基础软硬件:开源、迁移、上云,关键在生态

转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(35本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收188元(原总价290元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
